 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRFormer: A Cross-Region Transformer for Shadow Removal
Paper and Code
Jul 04, 2022
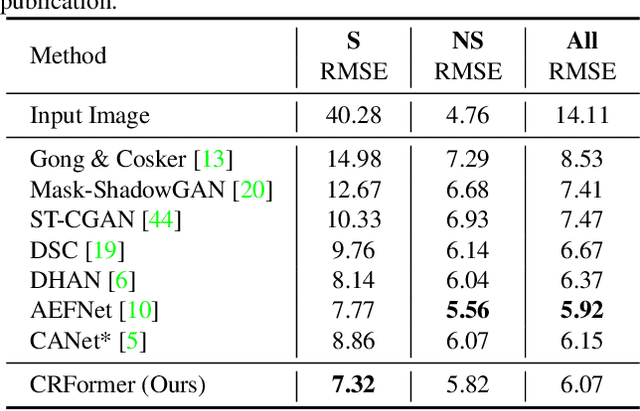
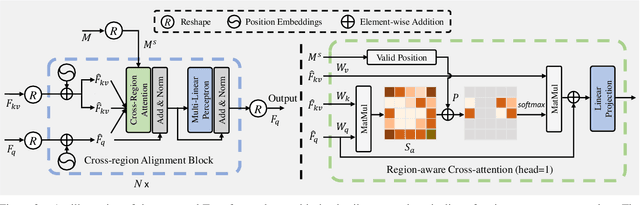
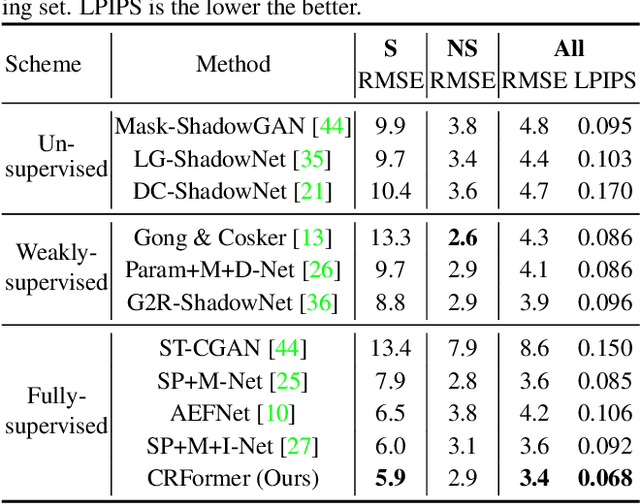
Aiming to restore the original intensity of shadow regions in an image and make them compatible with the remaining non-shadow regions without a trace, shadow removal is a very challenging problem that benefits many downstream image/video-related tasks. Recently, transformers have shown their strong capability in various applications by capturing global pixel interactions and this capability is highly desirable in shadow removal. However, applying transformers to promote shadow removal is non-trivial for the following two reasons: 1) The patchify operation is not suitable for shadow removal due to irregular shadow shapes; 2) shadow removal only needs one-way interaction from the non-shadow region to the shadow region instead of the common two-way interactions among all pixels in the image. In this paper, we propose a novel cross-region transformer, namely CRFormer, for shadow removal which differs from existing transformers by only considering the pixel interactions from the non-shadow region to the shadow region without splitting images into patches. This is achieved by a carefully designed region-aware cross-attention operation that can aggregate the recovered shadow region features conditioned on the non-shadow region features. Extensive experiments on ISTD, AISTD, SRD, and Video Shadow Removal datasets demonstrate the superiority of our method compared to other state-of-the-art methods.