 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquire and then Adapt: Squeezing out Text-to-Image Model for Image Restoration
Apr 21, 2025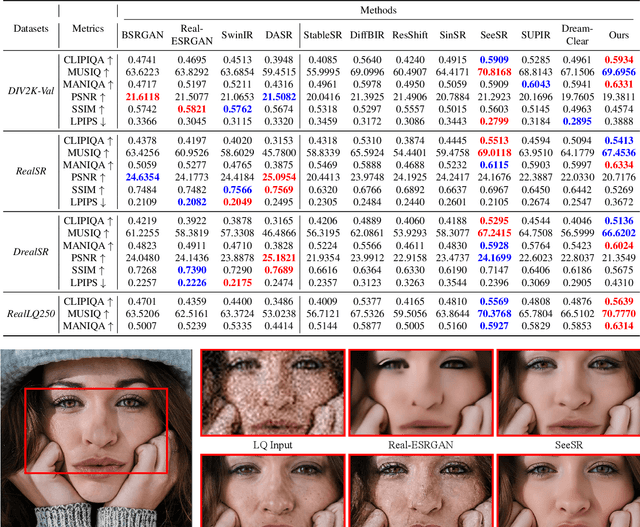
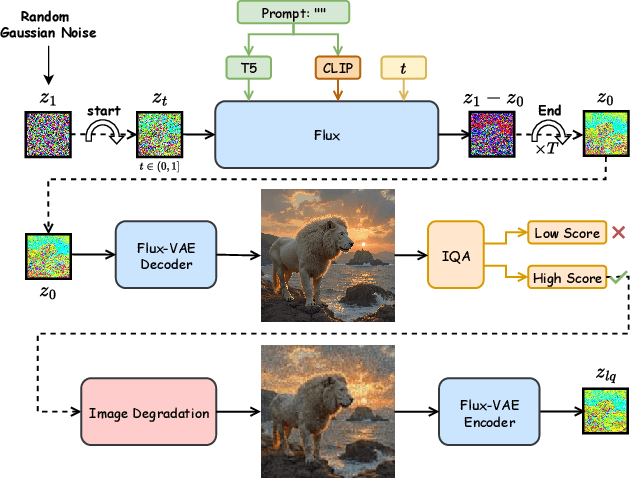
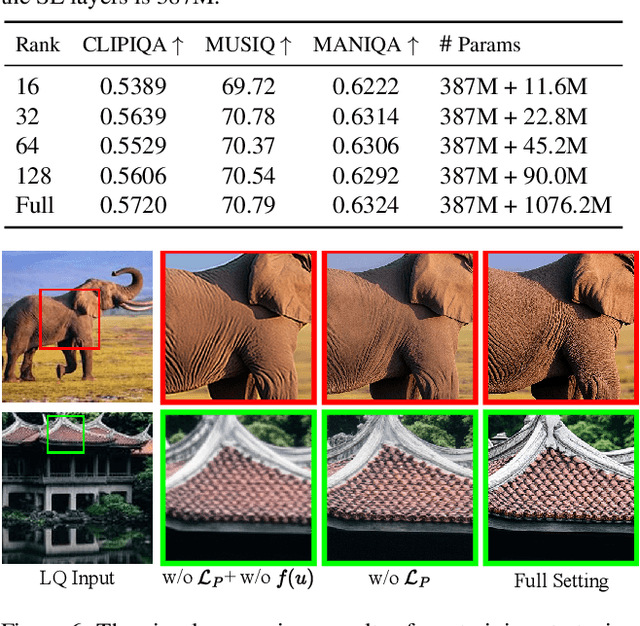
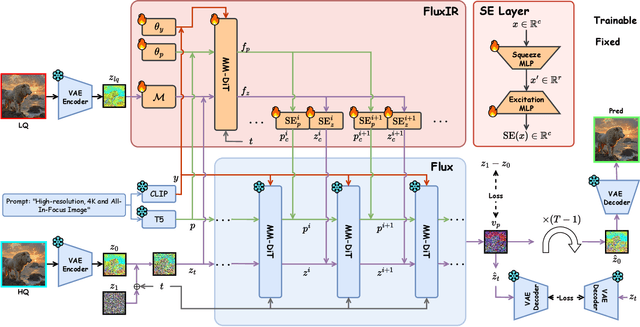
Recently, pre-trained text-to-image (T2I) models have been extensively adopted for real-world image restoration because of their powerful generative prior. However, controlling these large models for image restoration usually requires a large number of high-quality images and immense computational resources for training, which is costly and not privacy-friendly. In this paper, we find that the well-trained large T2I model (i.e., Flux) is able to produce a variety of high-quality images aligned with real-world distributions, offering an unlimited supply of training samples to mitigate the above issue. Specifically, we proposed a training data construction pipeline for image restoration, namely FluxGen, which includes unconditional image generation, image selection, and degraded image simulation. A novel light-weighted adapter (FluxIR) with squeeze-and-excitation layers is also carefully designed to control the large Diffusion Transformer (DiT)-based T2I model so that reasonable details can be restored. Experiments demonstrate that our proposed method enables the Flux model to adapt effectively to real-world image restoration tasks, achieving superior scores and visual quality on both synthetic and real-world degradation datasets - at only about 8.5\% of the training cost compared to current approaches.
Few-Shot 3D Point Cloud Semantic Segmentation via Stratified Class-Specific Attention Based Transformer Network
Mar 28, 20233D point cloud semantic segmentation aims to group all points into different semantic categories, which benefits important applications such as point cloud scene reconstruction and understanding. Existing supervised point cloud semantic segmentation methods usually require large-scale annotated point clouds for training and cannot handle new categories. While a few-shot learning method was proposed recently to address these two problems, it suffers from high computational complexity caused by graph construction and inability to learn fine-grained relationships among points due to the use of pooling operations. In this paper, we further address these problems by developing a new multi-layer transformer network for few-shot point cloud semantic segmentation. In the proposed network, the query point cloud features are aggregated based on the class-specific support features in different scales. Without using pooling operations, our method makes full use of all pixel-level features from the support samples. By better leveraging the support features for few-shot learning, the proposed method achieves the new state-of-the-art performance, with 15\% less inference time, over existing few-shot 3D point cloud segmentation models on the S3DIS dataset and the ScanNet dataset.
Parametric Surface Constrained Upsampler Network for Point Cloud
Mar 14, 2023Designing a point cloud upsampler, which aims to generate a clean and dense point cloud given a sparse point representation, is a fundamental and challenging problem in computer vision. A line of attempts achieves this goal by establishing a point-to-point mapping function via deep neural networks. However, these approaches are prone to produce outlier points due to the lack of explicit surface-level constraints. To solve this problem, we introduce a novel surface regularizer into the upsampler network by forcing the neural network to learn the underlying parametric surface represented by bicubic functions and rotation functions, where the new generated points are then constrained on the underlying surface. These designs are integrated into two different networks for two tasks that take advantages of upsampling layers - point cloud upsampling and point cloud completion for evaluation. The state-of-the-art experimental results on both tasks demonstrate the effectiveness of the proposed method. The implementation code will be available at https://github.com/corecai163/PSCU.
Cross-domain Few-shot Segmentation with Transductive Fine-tuning
Nov 27, 2022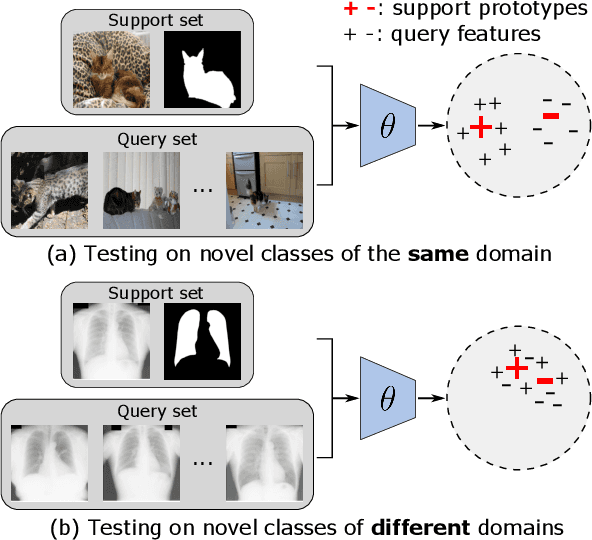
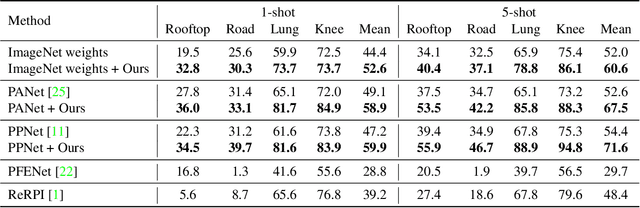
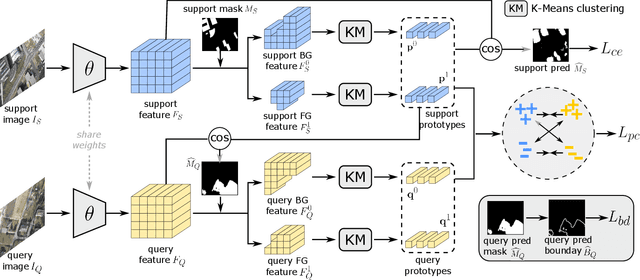
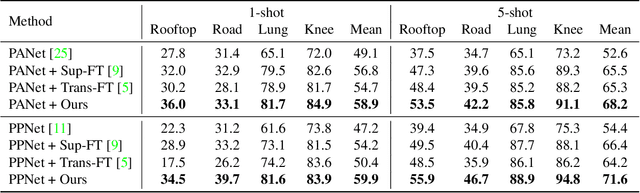
Few-shot segmentation (FSS) expects models trained on base classes to work on novel classes with the help of a few support images. However, when there exists a domain gap between the base and novel classes, the state-of-the-art FSS methods may even fail to segment simple objects. To improve their performance on unseen domains, we propose to transductively fine-tune the base model on a set of query images under the few-shot setting, where the core idea is to implicitly guide the segmentation of query images using support labels. Although different images are not directly comparable, their class-wise prototypes are desired to be aligned in the feature space. By aligning query and support prototypes with an uncertainty-aware contrastive loss, and using a supervised cross-entropy loss and an unsupervised boundary loss as regularizations, our method could generalize the base model to the target domain without additional labels. We conduct extensive experiments under various cross-domain settings of natural, remote sensing, and medical images. The results show that our method could consistently and significantly improve the performance of prototypical FSS models in all cross-domain tasks.
PLMCL: Partial-Label Momentum Curriculum Learning for Multi-Label Image Classification
Aug 22, 2022
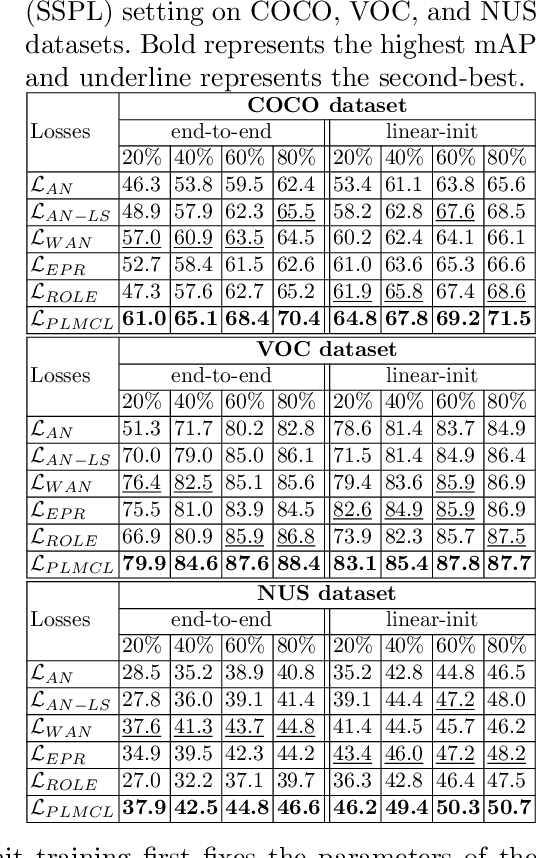
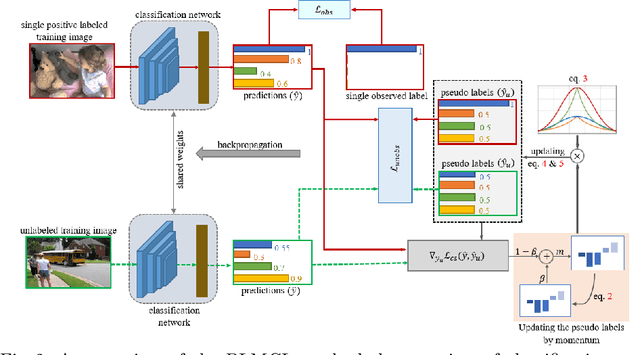
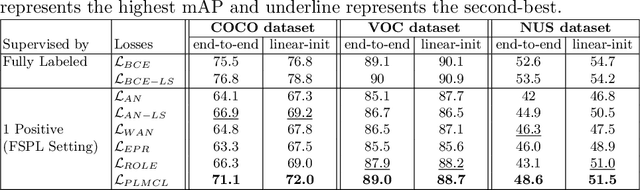
Multi-label image classification aims to predict all possible labels in an image. It is usually formulated as a partial-label learning problem, given the fact that it could be expensive in practice to annotate all labels in every training image. Existing works on partial-label learning focus on the case where each training image is annotated with only a subset of its labels. A special case is to annotate only one positive label in each training image. To further relieve the annotation burden and enhance the performance of the classifier, this paper proposes a new partial-label setting in which only a subset of the training images are labeled, each with only one positive label, while the rest of the training images remain unlabeled. To handle this new setting, we propose an end-to-end deep network, PLMCL (Partial Label Momentum Curriculum Learning), that can learn to produce confident pseudo labels for both partially-labeled and unlabeled training images. The novel momentum-based law updates soft pseudo labels on each training image with the consideration of the updating velocity of pseudo labels, which help avoid trapping to low-confidence local minimum, especially at the early stage of training in lack of both observed labels and confidence on pseudo labels. In addition, we present a confidence-aware scheduler to adaptively perform easy-to-hard learning for different labels. Extensive experiments demonstrate that our proposed PLMCL outperforms many state-of-the-art multi-label classification methods under various partial-label settings on three different datasets.
CRFormer: A Cross-Region Transformer for Shadow Removal
Jul 04, 2022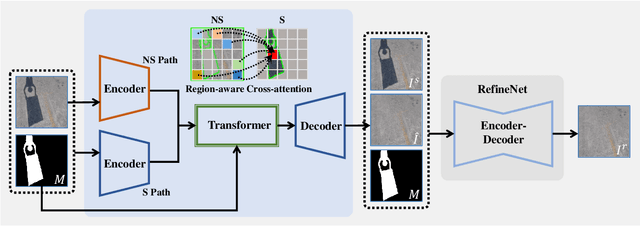
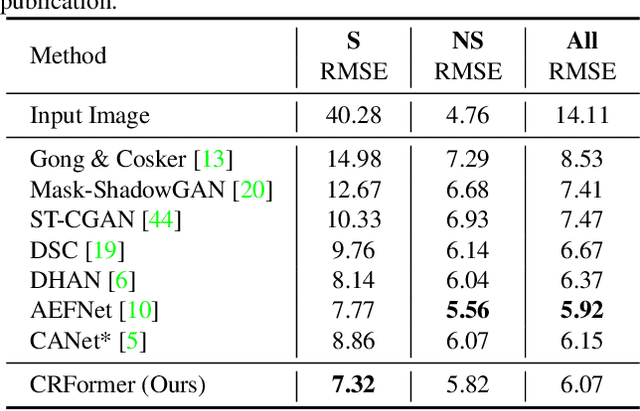
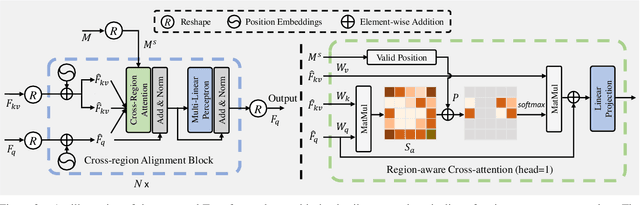
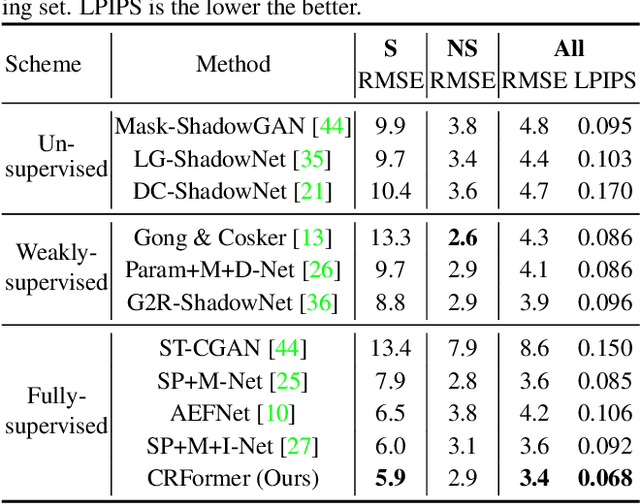
Aiming to restore the original intensity of shadow regions in an image and make them compatible with the remaining non-shadow regions without a trace, shadow removal is a very challenging problem that benefits many downstream image/video-related tasks. Recently, transformers have shown their strong capability in various applications by capturing global pixel interactions and this capability is highly desirable in shadow removal. However, applying transformers to promote shadow removal is non-trivial for the following two reasons: 1) The patchify operation is not suitable for shadow removal due to irregular shadow shapes; 2) shadow removal only needs one-way interaction from the non-shadow region to the shadow region instead of the common two-way interactions among all pixels in the image. In this paper, we propose a novel cross-region transformer, namely CRFormer, for shadow removal which differs from existing transformers by only considering the pixel interactions from the non-shadow region to the shadow region without splitting images into patches. This is achieved by a carefully designed region-aware cross-attention operation that can aggregate the recovered shadow region features conditioned on the non-shadow region features. Extensive experiments on ISTD, AISTD, SRD, and Video Shadow Removal datasets demonstrate the superiority of our method compared to other state-of-the-art methods.
Physics Guided Generative Adversarial Networks for Generations of Crystal Materials with Symmetry Constraints
Mar 27, 2022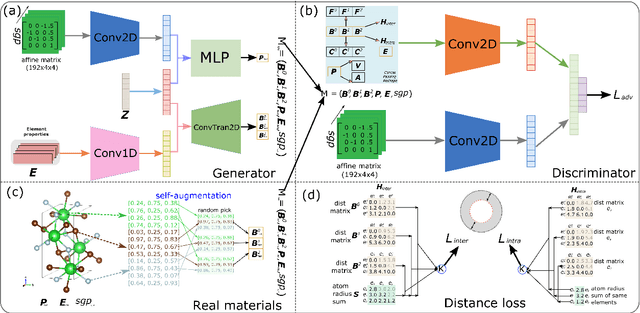
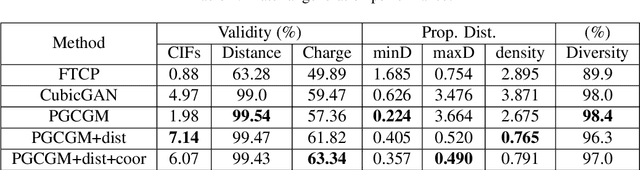

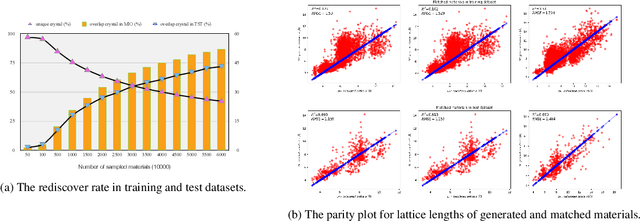
Discovering new materials is a long-standing challenging task that is critical to the progress of human society. Conventional approaches such as trial-and-error experiments and computational simulations are labor-intensive or costly with their success heavily depending on experts' heuristics. Recently deep generative models have been successfully proposed for materials generation by learning implicit knowledge from known materials datasets, with performance however limited by their confinement to a special material family or failing to incorporate physical rules into the model training process. Here we propose a Physics Guided Crystal Generative Model (PGCGM) for new materials generation, which captures and exploits the pairwise atomic distance constraints among neighbor atoms and symmetric geometric constraints. By augmenting the base atom sites of materials, our model can generates new materials of 20 space groups. With atom clustering and merging on generated crystal structures, our method increases the generator's validity by 8 times compared to one of the baselines and by 143\% compared to the previous CubicGAN along with its superiority in properties distribution and diversity. We further validated our generated candidates by Density Functional Theory (DFT) calculation, which successfully optimized/relaxed 1869 materials out of 2000, of which 39.6\% are with negative formation energy, indicating their stability.
Style Mixing and Patchwise Prototypical Matching for One-Shot Unsupervised Domain Adaptive Semantic Segmentation
Dec 09, 2021
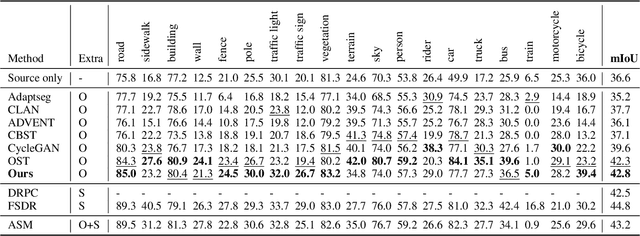
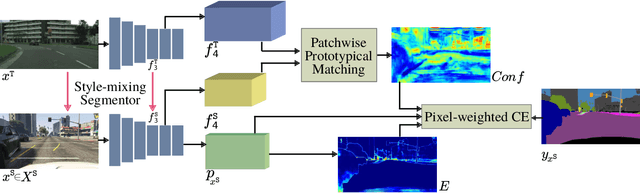
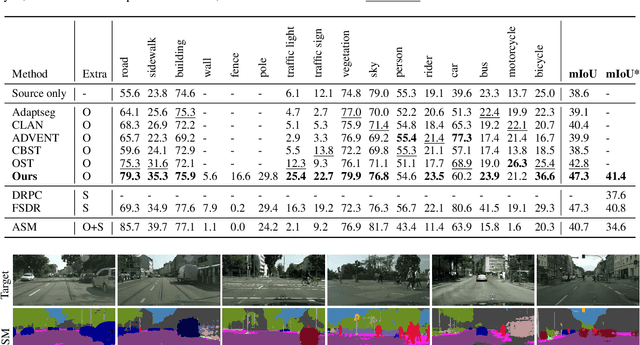
In this paper, we tackle the problem of one-shot unsupervised domain adaptation (OSUDA) for semantic segmentation where the segmentors only see one unlabeled target image during training. In this case, traditional unsupervised domain adaptation models usually fail since they cannot adapt to the target domain with over-fitting to one (or few) target samples. To address this problem, existing OSUDA methods usually integrate a style-transfer module to perform domain randomization based on the unlabeled target sample, with which multiple domains around the target sample can be explored during training. However, such a style-transfer module relies on an additional set of images as style reference for pre-training and also increases the memory demand for domain adaptation. Here we propose a new OSUDA method that can effectively relieve such computational burden. Specifically, we integrate several style-mixing layers into the segmentor which play the role of style-transfer module to stylize the source images without introducing any learned parameters. Moreover, we propose a patchwise prototypical matching (PPM) method to weighted consider the importance of source pixels during the supervised training to relieve the negative adaptation. Experimental results show that our method achieves new state-of-the-art performance on two commonly used benchmarks for domain adaptive semantic segmentation under the one-shot setting and is more efficient than all comparison approaches.
ATLANTIS: A Benchmark for Semantic Segmentation of Waterbody Images
Nov 22, 2021
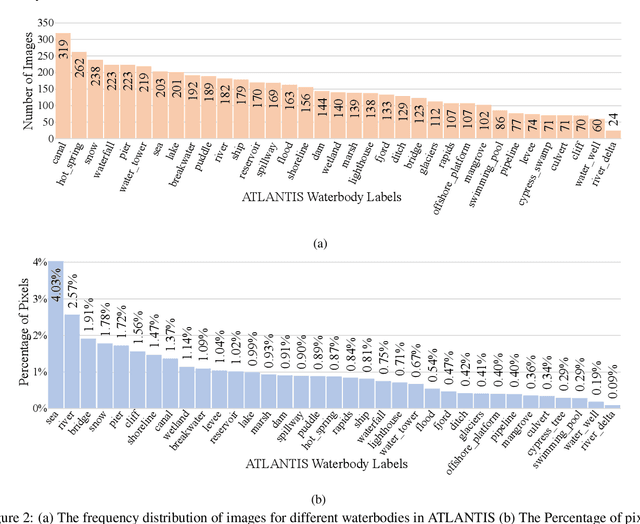
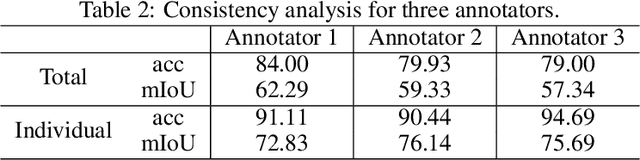
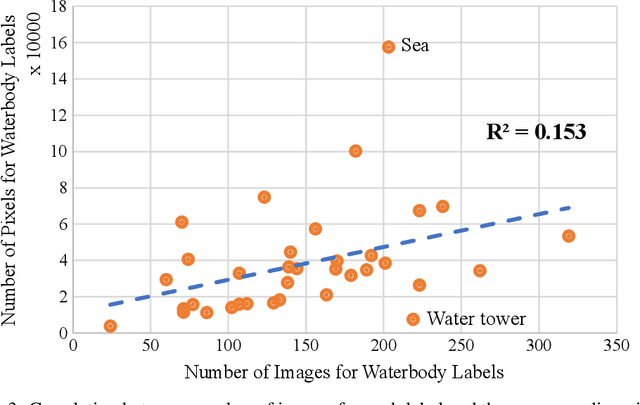
Vision-based semantic segmentation of waterbodies and nearby related objects provides important information for managing water resources and handling flooding emergency. However, the lack of large-scale labeled training and testing datasets for water-related categories prevents researchers from studying water-related issues in the computer vision field. To tackle this problem, we present ATLANTIS, a new benchmark for semantic segmentation of waterbodies and related objects. ATLANTIS consists of 5,195 images of waterbodies, as well as high quality pixel-level manual annotations of 56 classes of objects, including 17 classes of man-made objects, 18 classes of natural objects and 21 general classes. We analyze ATLANTIS in detail and evaluate several state-of-the-art semantic segmentation networks on our benchmark. In addition, a novel deep neural network, AQUANet, is developed for waterbody semantic segmentation by processing the aquatic and non-aquatic regions in two different paths. AQUANet also incorporates low-level feature modulation and cross-path modulation for enhancing feature representation. Experimental results show that the proposed AQUANet outperforms other state-of-the-art semantic segmentation networks on ATLANTIS. We claim that ATLANTIS is the largest waterbody image dataset for semantic segmentation providing a wide range of water and water-related classes and it will benefit researchers of both computer vision and water resources engineering.
DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation
Apr 22, 2021
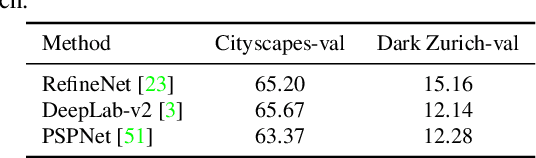
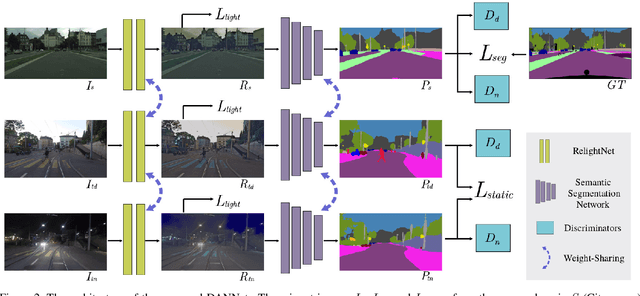
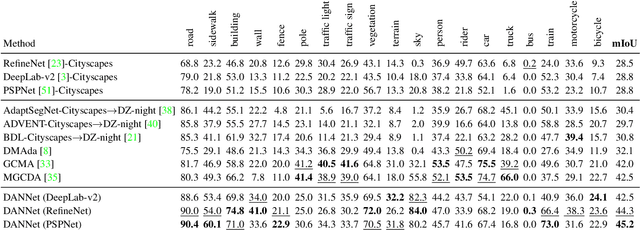
Semantic segmentation of nighttime images plays an equally important role as that of daytime images in autonomous driving, but the former is much more challenging due to poor illuminations and arduous human annotations. In this paper, we propose a novel domain adaptation network (DANNet) for nighttime semantic segmentation without using labeled nighttime image data. It employs an adversarial training with a labeled daytime dataset and an unlabeled dataset that contains coarsely aligned day-night image pairs. Specifically, for the unlabeled day-night image pairs, we use the pixel-level predictions of static object categories on a daytime image as a pseudo supervision to segment its counterpart nighttime image. We further design a re-weighting strategy to handle the inaccuracy caused by misalignment between day-night image pairs and wrong predictions of daytime images, as well as boost the prediction accuracy of small objects. The proposed DANNet is the first one stage adaptation framework for nighttime semantic segmentation, which does not train additional day-night image transfer models as a separate pre-processing stage. Extensive experiments on Dark Zurich and Nighttime Driving datasets show that our method achieves state-of-the-art performance for nighttime semantic segmentation.