 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacet: highly efficient E(3)-equivariant networks for interatomic potentials
Sep 10, 2025Computational materials discovery is limited by the high cost of first-principles calculations. Machine learning (ML) potentials that predict energies from crystal structures are promising, but existing methods face computational bottlenecks. Steerable graph neural networks (GNNs) encode geometry with spherical harmonics, respecting atomic symmetries -- permutation, rotation, and translation -- for physically realistic predictions. Yet maintaining equivariance is difficult: activation functions must be modified, and each layer must handle multiple data types for different harmonic orders. We present Facet, a GNN architecture for efficient ML potentials, developed through systematic analysis of steerable GNNs. Our innovations include replacing expensive multi-layer perceptrons (MLPs) for interatomic distances with splines, which match performance while cutting computational and memory demands. We also introduce a general-purpose equivariant layer that mixes node information via spherical grid projection followed by standard MLPs -- faster than tensor products and more expressive than linear or gate layers. On the MPTrj dataset, Facet matches leading models with far fewer parameters and under 10% of their training compute. On a crystal relaxation task, it runs twice as fast as MACE models. We further show SevenNet-0's parameters can be reduced by over 25% with no accuracy loss. These techniques enable more than 10x faster training of large-scale foundation models for ML potentials, potentially reshaping computational materials discovery.
Structure-based out-of-distribution (OOD) materials property prediction: a benchmark study
Jan 16, 2024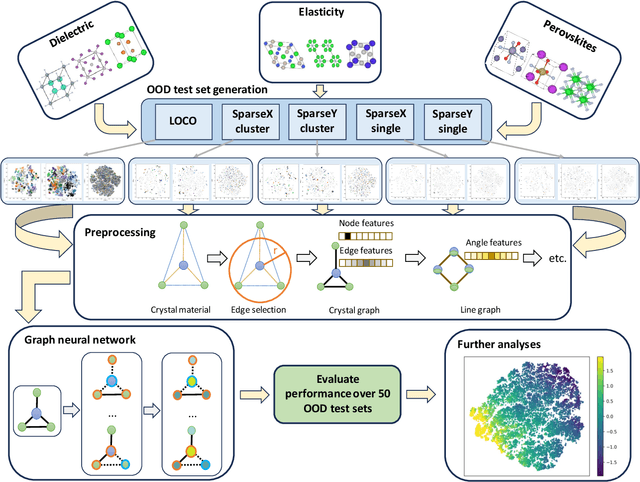
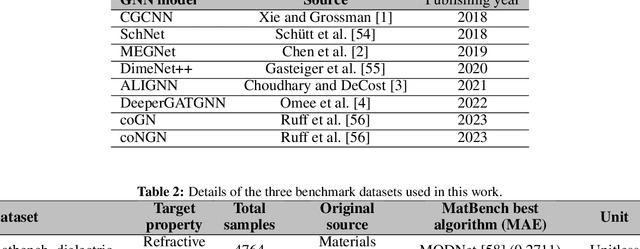
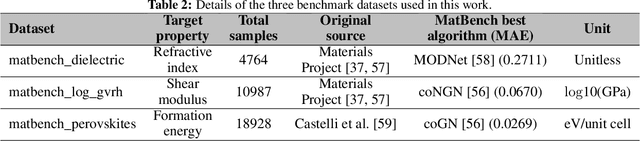
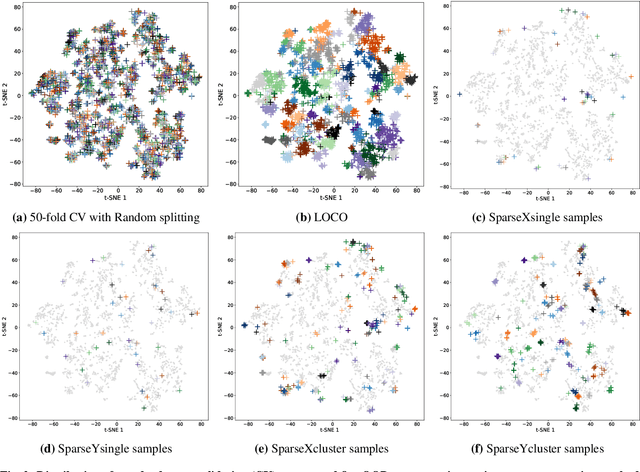
In real-world material research, machine learning (ML) models are usually expected to predict and discover novel exceptional materials that deviate from the known materials. It is thus a pressing question to provide an objective evaluation of ML model performances in property prediction of out-of-distribution (OOD) materials that are different from the training set distribution. Traditional performance evaluation of materials property prediction models through random splitting of the dataset frequently results in artificially high performance assessments due to the inherent redundancy of typical material datasets. Here we present a comprehensive benchmark study of structure-based graph neural networks (GNNs) for extrapolative OOD materials property prediction. We formulate five different categories of OOD ML problems for three benchmark datasets from the MatBench study. Our extensive experiments show that current state-of-the-art GNN algorithms significantly underperform for the OOD property prediction tasks on average compared to their baselines in the MatBench study, demonstrating a crucial generalization gap in realistic material prediction tasks. We further examine the latent physical spaces of these GNN models and identify the sources of CGCNN, ALIGNN, and DeeperGATGNN's significantly more robust OOD performance than those of the current best models in the MatBench study (coGN and coNGN), and provide insights to improve their performance.
Generative Design of inorganic compounds using deep diffusion language models
Sep 30, 2023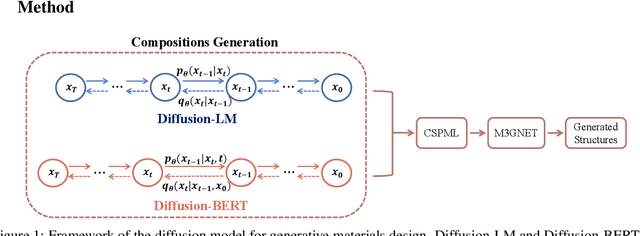

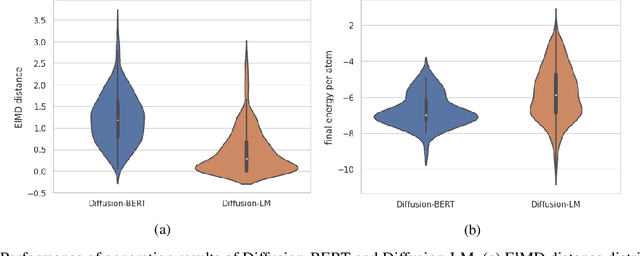
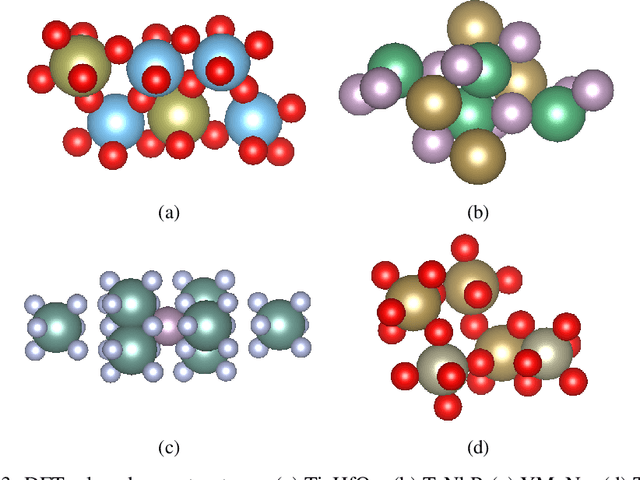
Due to the vast chemical space, discovering materials with a specific function is challenging. Chemical formulas are obligated to conform to a set of exacting criteria such as charge neutrality, balanced electronegativity, synthesizability, and mechanical stability. In response to this formidable task, we introduce a deep learning-based generative model for material composition and structure design by learning and exploiting explicit and implicit chemical knowledge. Our pipeline first uses deep diffusion language models as the generator of compositions and then applies a template-based crystal structure prediction algorithm to predict their corresponding structures, which is then followed by structure relaxation using a universal graph neural network-based potential. The density functional theory (DFT) calculations of the formation energies and energy-above-the-hull analysis are used to validate new structures generated through our pipeline. Based on the DFT calculation results, six new materials, including Ti2HfO5, TaNbP, YMoN2, TaReO4, HfTiO2, and HfMnO2, with formation energy less than zero have been found. Remarkably, among these, four materials, namely Ti2$HfO5, TaNbP, YMoN2, and TaReO4, exhibit an e-above-hull energy of less than 0.3 eV. These findings have proved the effectiveness of our approach.
MD-HIT: Machine learning for materials property prediction with dataset redundancy control
Jul 10, 2023



Materials datasets are usually featured by the existence of many redundant (highly similar) materials due to the tinkering material design practice over the history of materials research. For example, the materials project database has many perovskite cubic structure materials similar to SrTiO$_3$. This sample redundancy within the dataset makes the random splitting of machine learning model evaluation to fail so that the ML models tend to achieve over-estimated predictive performance which is misleading for the materials science community. This issue is well known in the field of bioinformatics for protein function prediction, in which a redundancy reduction procedure (CD-Hit) is always applied to reduce the sample redundancy by ensuring no pair of samples has a sequence similarity greater than a given threshold. This paper surveys the overestimated ML performance in the literature for both composition based and structure based material property prediction. We then propose a material dataset redundancy reduction algorithm called MD-HIT and evaluate it with several composition and structure based distance threshold sfor reducing data set sample redundancy. We show that with this control, the predicted performance tends to better reflect their true prediction capability. Our MD-hit code can be freely accessed at https://github.com/usccolumbia/MD-HIT
Composition based oxidation state prediction of materials using deep learning
Nov 29, 2022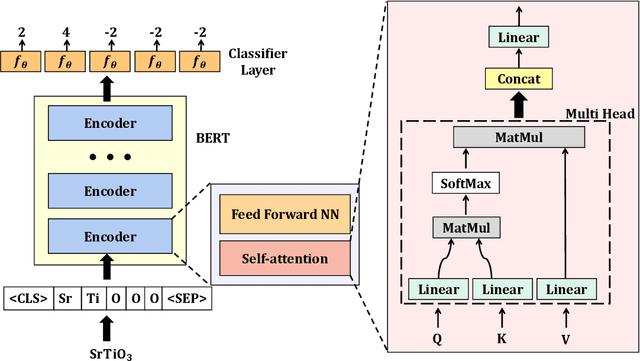

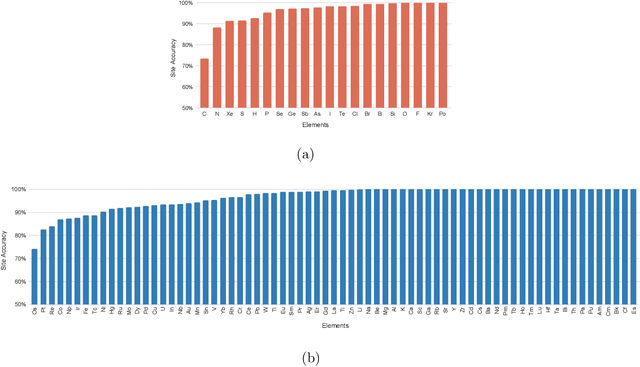
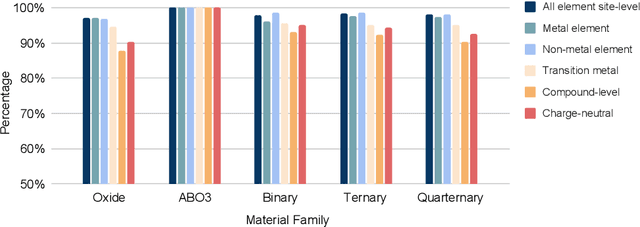
Oxidation states are the charges of atoms after their ionic approximation of their bonds, which have been widely used in charge-neutrality verification, crystal structure determination, and reaction estimation. Currently only heuristic rules exist for guessing the oxidation states of a given compound with many exceptions. Recent work has developed machine learning models based on heuristic structural features for predicting the oxidation states of metal ions. However, composition based oxidation state prediction still remains elusive so far, which is more important in new material discovery for which the structures are not even available. This work proposes a novel deep learning based BERT transformer language model BERTOS for predicting the oxidation states of all elements of inorganic compounds given only their chemical composition. Our model achieves 96.82\% accuracy for all-element oxidation states prediction benchmarked on the cleaned ICSD dataset and achieves 97.61\% accuracy for oxide materials. We also demonstrate how it can be used to conduct large-scale screening of hypothetical material compositions for materials discovery.
Probabilistic Generative Transformer Language models for Generative Design of Molecules
Sep 20, 2022
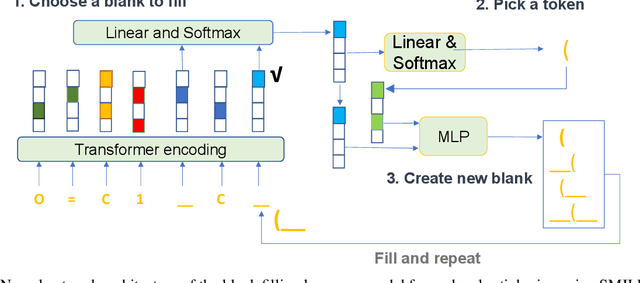
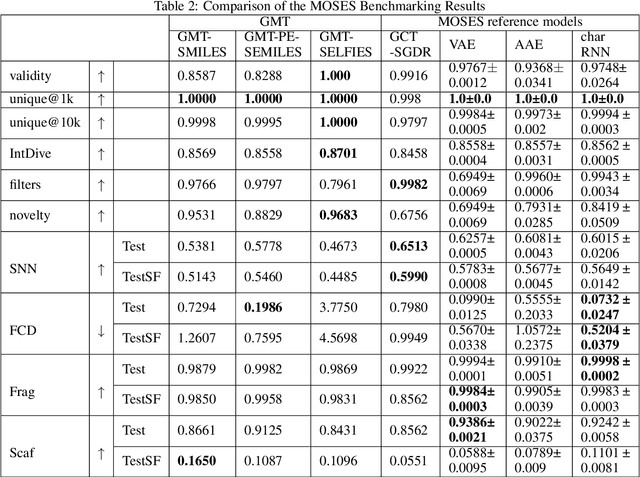
Self-supervised neural language models have recently found wide applications in generative design of organic molecules and protein sequences as well as representation learning for downstream structure classification and functional prediction. However, most of the existing deep learning models for molecule design usually require a big dataset and have a black-box architecture, which makes it difficult to interpret their design logic. Here we propose Generative Molecular Transformer (GMTransformer), a probabilistic neural network model for generative design of molecules. Our model is built on the blank filling language model originally developed for text processing, which has demonstrated unique advantages in learning the "molecules grammars" with high-quality generation, interpretability, and data efficiency. Benchmarked on the MOSES datasets, our models achieve high novelty and Scaf compared to other baselines. The probabilistic generation steps have the potential in tinkering molecule design due to their capability of recommending how to modify existing molecules with explanation, guided by the learned implicit molecule chemistry. The source code and datasets can be accessed freely at https://github.com/usccolumbia/GMTransformer
Materials Transformers Language Models for Generative Materials Design: a benchmark study
Jun 27, 2022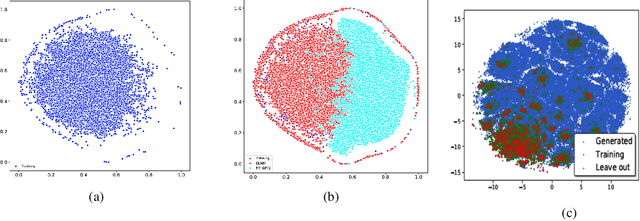
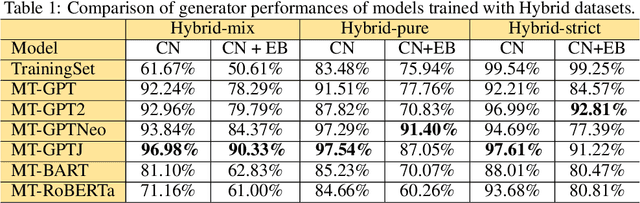
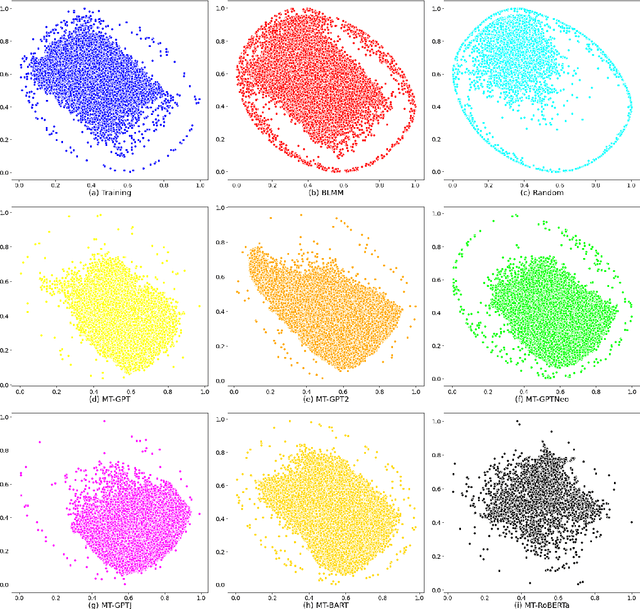
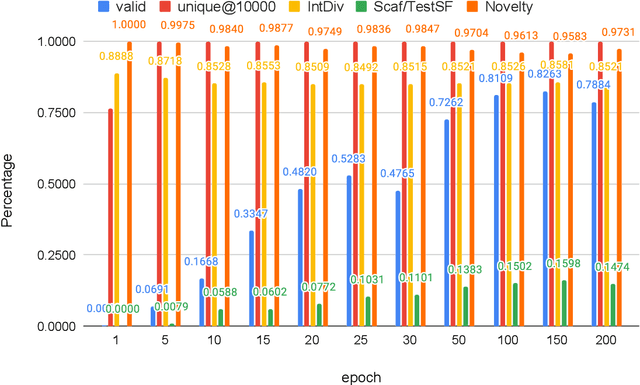
Pre-trained transformer language models on large unlabeled corpus have produced state-of-the-art results in natural language processing, organic molecule design, and protein sequence generation. However, no such models have been applied to learn the composition patterns of inorganic materials. Here we train a series of seven modern transformer language models (GPT, GPT-2, GPT-Neo, GPT-J, BLMM, BART, and RoBERTa) using the expanded formulas from material deposited in the ICSD, OQMD, and Materials Projects databases. Six different datasets with/out non-charge-neutral or balanced electronegativity samples are used to benchmark the performances and uncover the generation biases of modern transformer models for the generative design of materials compositions. Our extensive experiments showed that the causal language models based materials transformers can generate chemically valid materials compositions with as high as 97.54\% to be charge neutral and 91.40\% to be electronegativity balanced, which has more than 6 times higher enrichment compared to a baseline pseudo-random sampling algorithm. These models also demonstrate high novelty and their potential in new materials discovery has been proved by their capability to recover the leave-out materials. We also find that the properties of the generated samples can be tailored by training the models with selected training sets such as high-bandgap materials. Our experiments also showed that different models each have their own preference in terms of the properties of the generated samples and their running time complexity varies a lot. We have applied our materials transformer models to discover a set of new materials as validated using DFT calculations.
Physics Guided Generative Adversarial Networks for Generations of Crystal Materials with Symmetry Constraints
Mar 27, 2022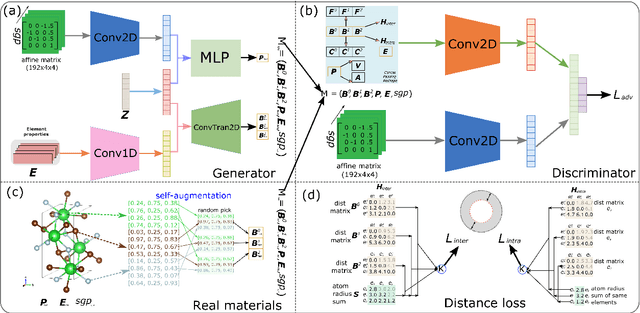
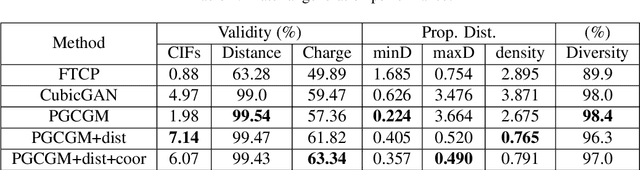

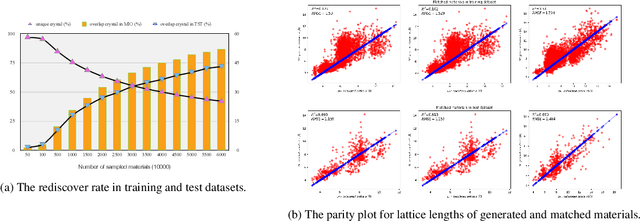
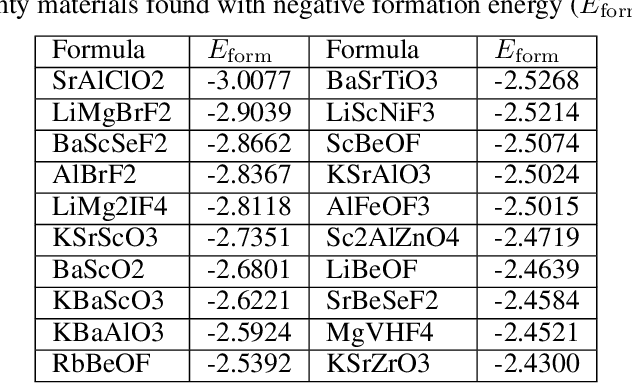
Discovering new materials is a long-standing challenging task that is critical to the progress of human society. Conventional approaches such as trial-and-error experiments and computational simulations are labor-intensive or costly with their success heavily depending on experts' heuristics. Recently deep generative models have been successfully proposed for materials generation by learning implicit knowledge from known materials datasets, with performance however limited by their confinement to a special material family or failing to incorporate physical rules into the model training process. Here we propose a Physics Guided Crystal Generative Model (PGCGM) for new materials generation, which captures and exploits the pairwise atomic distance constraints among neighbor atoms and symmetric geometric constraints. By augmenting the base atom sites of materials, our model can generates new materials of 20 space groups. With atom clustering and merging on generated crystal structures, our method increases the generator's validity by 8 times compared to one of the baselines and by 143\% compared to the previous CubicGAN along with its superiority in properties distribution and diversity. We further validated our generated candidates by Density Functional Theory (DFT) calculation, which successfully optimized/relaxed 1869 materials out of 2000, of which 39.6\% are with negative formation energy, indicating their stability.
Semi-supervised teacher-student deep neural network for materials discovery
Dec 12, 2021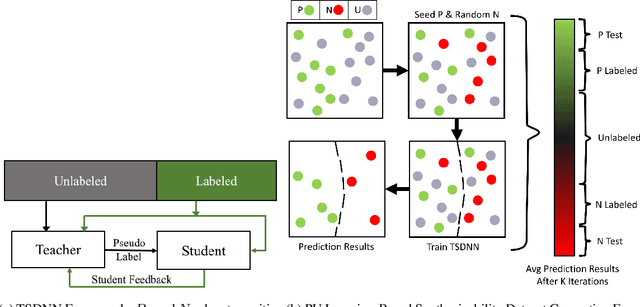
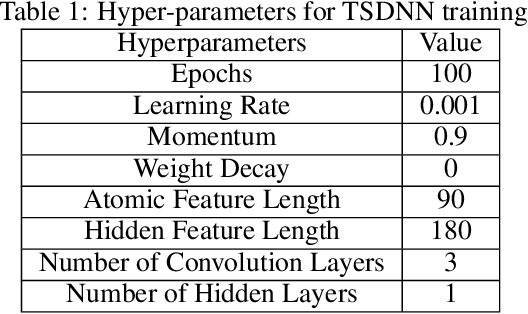


Data driven generative machine learning models have recently emerged as one of the most promising approaches for new materials discovery. While the generator models can generate millions of candidates, it is critical to train fast and accurate machine learning models to filter out stable, synthesizable materials with desired properties. However, such efforts to build supervised regression or classification screening models have been severely hindered by the lack of unstable or unsynthesizable samples, which usually are not collected and deposited in materials databases such as ICSD and Materials Project (MP). At the same time, there are a significant amount of unlabelled data available in these databases. Here we propose a semi-supervised deep neural network (TSDNN) model for high-performance formation energy and synthesizability prediction, which is achieved via its unique teacher-student dual network architecture and its effective exploitation of the large amount of unlabeled data. For formation energy based stability screening, our semi-supervised classifier achieves an absolute 10.3\% accuracy improvement compared to the baseline CGCNN regression model. For synthesizability prediction, our model significantly increases the baseline PU learning's true positive rate from 87.9\% to 97.9\% using 1/49 model parameters. To further prove the effectiveness of our models, we combined our TSDNN-energy and TSDNN-synthesizability models with our CubicGAN generator to discover novel stable cubic structures. Out of 1000 recommended candidate samples by our models, 512 of them have negative formation energies as validated by our DFT formation energy calculations. Our experimental results show that our semi-supervised deep neural networks can significantly improve the screening accuracy in large-scale generative materials design.
Scalable deeper graph neural networks for high-performance materials property prediction
Sep 25, 2021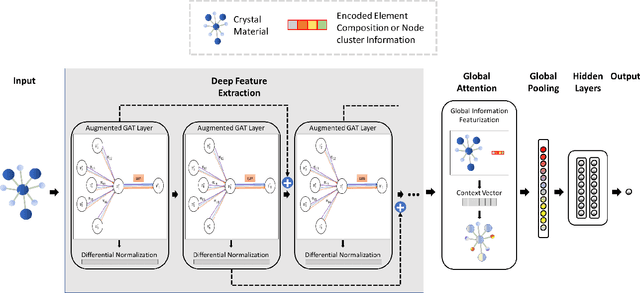
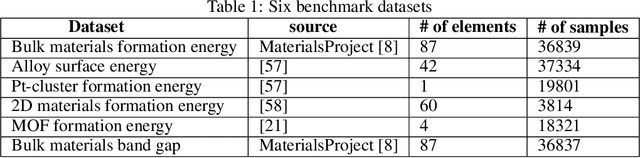
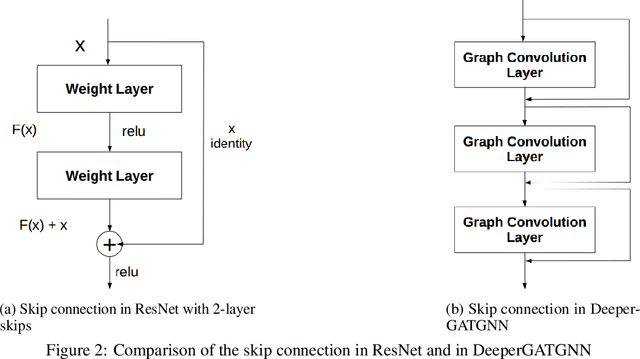
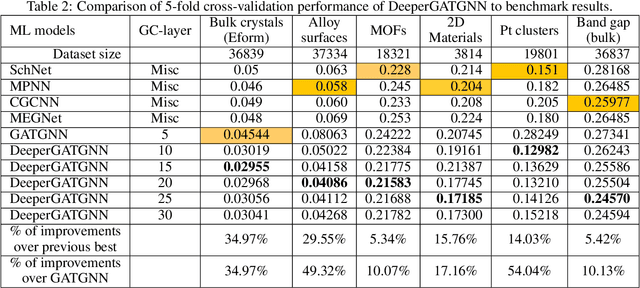
Machine learning (ML) based materials discovery has emerged as one of the most promising approaches for breakthroughs in materials science. While heuristic knowledge based descriptors have been combined with ML algorithms to achieve good performance, the complexity of the physicochemical mechanisms makes it urgently needed to exploit representation learning from either compositions or structures for building highly effective materials machine learning models. Among these methods, the graph neural networks have shown the best performance by its capability to learn high-level features from crystal structures. However, all these models suffer from their inability to scale up the models due to the over-smoothing issue of their message-passing GNN architecture. Here we propose a novel graph attention neural network model DeeperGATGNN with differentiable group normalization and skip-connections, which allows to train very deep graph neural network models (e.g. 30 layers compared to 3-9 layers in previous works). Through systematic benchmark studies over six benchmark datasets for energy and band gap predictions, we show that our scalable DeeperGATGNN model needs little costly hyper-parameter tuning for different datasets and achieves the state-of-the-art prediction performances over five properties out of six with up to 10\% improvement. Our work shows that to deal with the high complexity of mapping the crystal materials structures to their properties, large-scale very deep graph neural networks are needed to achieve robust performances.