 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation-Model Surrogates Enable Data-Efficient Active Learning for Materials Discovery
Mar 17, 2026Active learning (AL) has emerged as a powerful paradigm for accelerating materials discovery by iteratively steering experiments toward promising candidates, reducing the number of costly synthesis-and-characterization cycles needed to identify optimal materials. However, current AL relies predominantly on Gaussian Process (GP) and Random Forest (RF) surrogates, which suffer from complementary limitations: GP underfits complex composition-property landscapes due to rigid kernel assumptions, while RF produces unreliable heuristic uncertainty estimates in small-data regimes. This small-data challenge is pervasive in materials science, making reliable surrogate modeling extremely difficult with models trained from scratch on each new dataset. Here we propose In-Context Active Learning (ICAL), which addresses this bottleneck by replacing conventional surrogates with TabPFN, a transformer-based foundation model (FM) pre-trained on millions of synthetic regression tasks to meta-learn a universal prior over tabular data, upon which TabPFN performs principled Bayesian inference in a single forward pass without dataset-specific retraining, delivering strong small-data regression performance and well-calibrated predictive uncertainty (required for effective AL). We benchmark ICAL against GP and RF across 10 materials datasets and TabPFN wins on 8 out of 10 datasets, achieving a mean saving of 52% in extra evaluations relative to GP and 29.77% relative to RF. Cross-validation analysis confirms that TabPFN's advantage stems from superior uncertainty calibration, achieving the lowest Negative Log-Likelihood and Area Under the Sparsification Error curve among all surrogates. These results demonstrate that pre-trained FMs can serve as effective surrogates for active learning, enabling data-efficient discovery across diverse materials systems and small-data experimental sciences.
Force Policy: Learning Hybrid Force-Position Control Policy under Interaction Frame for Contact-Rich Manipulation
Feb 25, 2026Contact-rich manipulation demands human-like integration of perception and force feedback: vision should guide task progress, while high-frequency interaction control must stabilize contact under uncertainty. Existing learning-based policies often entangle these roles in a monolithic network, trading off global generalization against stable local refinement, while control-centric approaches typically assume a known task structure or learn only controller parameters rather than the structure itself. In this paper, we formalize a physically grounded interaction frame, an instantaneous local basis that decouples force regulation from motion execution, and propose a method to recover it from demonstrations. Based on this, we address both issues by proposing Force Policy, a global-local vision-force policy in which a global policy guides free-space actions using vision, and upon contact, a high-frequency local policy with force feedback estimates the interaction frame and executes hybrid force-position control for stable interaction. Real-world experiments across diverse contact-rich tasks show consistent gains over strong baselines, with more robust contact establishment, more accurate force regulation, and reliable generalization to novel objects with varied geometries and physical properties, ultimately improving both contact stability and execution quality. Project page: https://force-policy.github.io/
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
One-Shot Refiner: Boosting Feed-forward Novel View Synthesis via One-Step Diffusion
Jan 20, 2026We present a novel framework for high-fidelity novel view synthesis (NVS) from sparse images, addressing key limitations in recent feed-forward 3D Gaussian Splatting (3DGS) methods built on Vision Transformer (ViT) backbones. While ViT-based pipelines offer strong geometric priors, they are often constrained by low-resolution inputs due to computational costs. Moreover, existing generative enhancement methods tend to be 3D-agnostic, resulting in inconsistent structures across views, especially in unseen regions. To overcome these challenges, we design a Dual-Domain Detail Perception Module, which enables handling high-resolution images without being limited by the ViT backbone, and endows Gaussians with additional features to store high-frequency details. We develop a feature-guided diffusion network, which can preserve high-frequency details during the restoration process. We introduce a unified training strategy that enables joint optimization of the ViT-based geometric backbone and the diffusion-based refinement module. Experiments demonstrate that our method can maintain superior generation quality across multiple datasets.
MVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Mar 11, 2025



3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
Fast White-Box Adversarial Streaming Without a Random Oracle
Jun 10, 2024Recently, the question of adversarially robust streaming, where the stream is allowed to depend on the randomness of the streaming algorithm, has gained a lot of attention. In this work, we consider a strong white-box adversarial model (Ajtai et al. PODS 2022), in which the adversary has access to all past random coins and the parameters used by the streaming algorithm. We focus on the sparse recovery problem and extend our result to other tasks such as distinct element estimation and low-rank approximation of matrices and tensors. The main drawback of previous work is that it requires a random oracle, which is especially problematic in the streaming model since the amount of randomness is counted in the space complexity of a streaming algorithm. Also, the previous work suffers from large update time. We construct a near-optimal solution for the sparse recovery problem in white-box adversarial streams, based on the subexponentially secure Learning with Errors assumption. Importantly, our solution does not require a random oracle and has a polylogarithmic per item processing time. We also give results in a related white-box adversarially robust distributed model. Our constructions are based on homomorphic encryption schemes satisfying very mild structural properties that are currently satisfied by most known schemes.
A Real-Time Rescheduling Algorithm for Multi-robot Plan Execution
Mar 26, 2024



One area of research in multi-agent path finding is to determine how replanning can be efficiently achieved in the case of agents being delayed during execution. One option is to reschedule the passing order of agents, i.e., the sequence in which agents visit the same location. In response, we propose Switchable-Edge Search (SES), an A*-style algorithm designed to find optimal passing orders. We prove the optimality of SES and evaluate its efficiency via simulations. The best variant of SES takes less than 1 second for small- and medium-sized problems and runs up to 4 times faster than baselines for large-sized problems.
Analytic-Splatting: Anti-Aliased 3D Gaussian Splatting via Analytic Integration
Mar 17, 2024



The 3D Gaussian Splatting (3DGS) gained its popularity recently by combining the advantages of both primitive-based and volumetric 3D representations, resulting in improved quality and efficiency for 3D scene rendering. However, 3DGS is not alias-free, and its rendering at varying resolutions could produce severe blurring or jaggies. This is because 3DGS treats each pixel as an isolated, single point rather than as an area, causing insensitivity to changes in the footprints of pixels. Consequently, this discrete sampling scheme inevitably results in aliasing, owing to the restricted sampling bandwidth. In this paper, we derive an analytical solution to address this issue. More specifically, we use a conditioned logistic function as the analytic approximation of the cumulative distribution function (CDF) in a one-dimensional Gaussian signal and calculate the Gaussian integral by subtracting the CDFs. We then introduce this approximation in the two-dimensional pixel shading, and present Analytic-Splatting, which analytically approximates the Gaussian integral within the 2D-pixel window area to better capture the intensity response of each pixel. Moreover, we use the approximated response of the pixel window integral area to participate in the transmittance calculation of volume rendering, making Analytic-Splatting sensitive to the changes in pixel footprint at different resolutions. Experiments on various datasets validate that our approach has better anti-aliasing capability that gives more details and better fidelity.
GS-IR: 3D Gaussian Splatting for Inverse Rendering
Dec 04, 2023



We propose GS-IR, a novel inverse rendering approach based on 3D Gaussian Splatting (GS) that leverages forward mapping volume rendering to achieve photorealistic novel view synthesis and relighting results. Unlike previous works that use implicit neural representations and volume rendering (e.g. NeRF), which suffer from low expressive power and high computational complexity, we extend GS, a top-performance representation for novel view synthesis, to estimate scene geometry, surface material, and environment illumination from multi-view images captured under unknown lighting conditions. There are two main problems when introducing GS to inverse rendering: 1) GS does not support producing plausible normal natively; 2) forward mapping (e.g. rasterization and splatting) cannot trace the occlusion like backward mapping (e.g. ray tracing). To address these challenges, our GS-IR proposes an efficient optimization scheme that incorporates a depth-derivation-based regularization for normal estimation and a baking-based occlusion to model indirect lighting. The flexible and expressive GS representation allows us to achieve fast and compact geometry reconstruction, photorealistic novel view synthesis, and effective physically-based rendering. We demonstrate the superiority of our method over baseline methods through qualitative and quantitative evaluations on various challenging scenes.
HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation
Oct 02, 2023
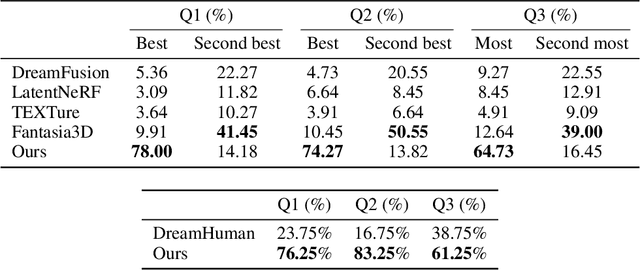


Recent text-to-3D methods employing diffusion models have made significant advancements in 3D human generation. However, these approaches face challenges due to the limitations of the text-to-image diffusion model, which lacks an understanding of 3D structures. Consequently, these methods struggle to achieve high-quality human generation, resulting in smooth geometry and cartoon-like appearances. In this paper, we observed that fine-tuning text-to-image diffusion models with normal maps enables their adaptation into text-to-normal diffusion models, which enhances the 2D perception of 3D geometry while preserving the priors learned from large-scale datasets. Therefore, we propose HumanNorm, a novel approach for high-quality and realistic 3D human generation by learning the normal diffusion model including a normal-adapted diffusion model and a normal-aligned diffusion model. The normal-adapted diffusion model can generate high-fidelity normal maps corresponding to prompts with view-dependent text. The normal-aligned diffusion model learns to generate color images aligned with the normal maps, thereby transforming physical geometry details into realistic appearance. Leveraging the proposed normal diffusion model, we devise a progressive geometry generation strategy and coarse-to-fine texture generation strategy to enhance the efficiency and robustness of 3D human generation. Comprehensive experiments substantiate our method's ability to generate 3D humans with intricate geometry and realistic appearances, significantly outperforming existing text-to-3D methods in both geometry and texture quality. The project page of HumanNorm is https://humannorm.github.io/.