 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiHateLoc: Towards Temporal Localisation of Multimodal Hate Content in Online Videos
Dec 11, 2025The rapid growth of video content on platforms such as TikTok and YouTube has intensified the spread of multimodal hate speech, where harmful cues emerge subtly and asynchronously across visual, acoustic, and textual streams. Existing research primarily focuses on video-level classification, leaving the practically crucial task of temporal localisation, identifying when hateful segments occur, largely unaddressed. This challenge is even more noticeable under weak supervision, where only video-level labels are available, and static fusion or classification-based architectures struggle to capture cross-modal and temporal dynamics. To address these challenges, we propose MultiHateLoc, the first framework designed for weakly-supervised multimodal hate localisation. MultiHateLoc incorporates (1) modality-aware temporal encoders to model heterogeneous sequential patterns, including a tailored text-based preprocessing module for feature enhancement; (2) dynamic cross-modal fusion to adaptively emphasise the most informative modality at each moment and a cross-modal contrastive alignment strategy to enhance multimodal feature consistency; (3) a modality-aware MIL objective to identify discriminative segments under video-level supervision. Despite relying solely on coarse labels, MultiHateLoc produces fine-grained, interpretable frame-level predictions. Experiments on HateMM and MultiHateClip show that our method achieves state-of-the-art performance in the localisation task.
Structure-Aware Feature Rectification with Region Adjacency Graphs for Training-Free Open-Vocabulary Semantic Segmentation
Dec 08, 2025

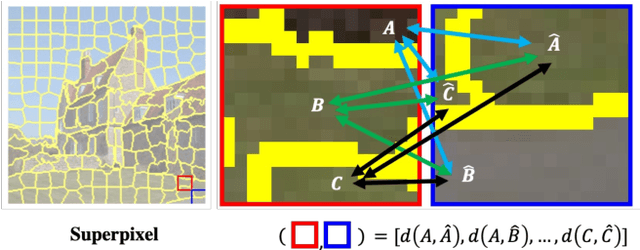

Benefiting from the inductive biases learned from large-scale datasets, open-vocabulary semantic segmentation (OVSS) leverages the power of vision-language models, such as CLIP, to achieve remarkable progress without requiring task-specific training. However, due to CLIP's pre-training nature on image-text pairs, it tends to focus on global semantic alignment, resulting in suboptimal performance when associating fine-grained visual regions with text. This leads to noisy and inconsistent predictions, particularly in local areas. We attribute this to a dispersed bias stemming from its contrastive training paradigm, which is difficult to alleviate using CLIP features alone. To address this, we propose a structure-aware feature rectification approach that incorporates instance-specific priors derived directly from the image. Specifically, we construct a region adjacency graph (RAG) based on low-level features (e.g., colour and texture) to capture local structural relationships and use it to refine CLIP features by enhancing local discrimination. Extensive experiments show that our method effectively suppresses segmentation noise, improves region-level consistency, and achieves strong performance on multiple open-vocabulary segmentation benchmarks.
Exploring Image Representation with Decoupled Classical Visual Descriptors
Oct 16, 2025Exploring and understanding efficient image representations is a long-standing challenge in computer vision. While deep learning has achieved remarkable progress across image understanding tasks, its internal representations are often opaque, making it difficult to interpret how visual information is processed. In contrast, classical visual descriptors (e.g. edge, colour, and intensity distribution) have long been fundamental to image analysis and remain intuitively understandable to humans. Motivated by this gap, we ask a central question: Can modern learning benefit from these classical cues? In this paper, we answer it with VisualSplit, a framework that explicitly decomposes images into decoupled classical descriptors, treating each as an independent but complementary component of visual knowledge. Through a reconstruction-driven pre-training scheme, VisualSplit learns to capture the essence of each visual descriptor while preserving their interpretability. By explicitly decomposing visual attributes, our method inherently facilitates effective attribute control in various advanced visual tasks, including image generation and editing, extending beyond conventional classification and segmentation, suggesting the effectiveness of this new learning approach for visual understanding. Project page: https://chenyuanqu.com/VisualSplit/.
An Exploratory Study on Abstract Images and Visual Representations Learned from Them
Sep 17, 2025Imagine living in a world composed solely of primitive shapes, could you still recognise familiar objects? Recent studies have shown that abstract images-constructed by primitive shapes-can indeed convey visual semantic information to deep learning models. However, representations obtained from such images often fall short compared to those derived from traditional raster images. In this paper, we study the reasons behind this performance gap and investigate how much high-level semantic content can be captured at different abstraction levels. To this end, we introduce the Hierarchical Abstraction Image Dataset (HAID), a novel data collection that comprises abstract images generated from normal raster images at multiple levels of abstraction. We then train and evaluate conventional vision systems on HAID across various tasks including classification, segmentation, and object detection, providing a comprehensive study between rasterised and abstract image representations. We also discuss if the abstract image can be considered as a potentially effective format for conveying visual semantic information and contributing to vision tasks.
What Can We Learn from Harry Potter? An Exploratory Study of Visual Representation Learning from Atypical Videos
Aug 29, 2025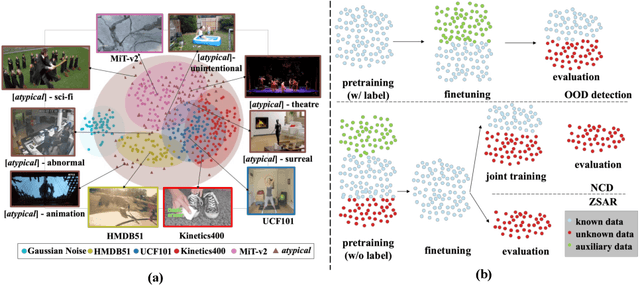
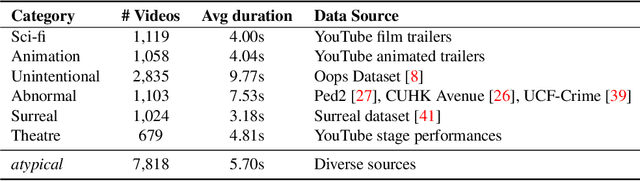

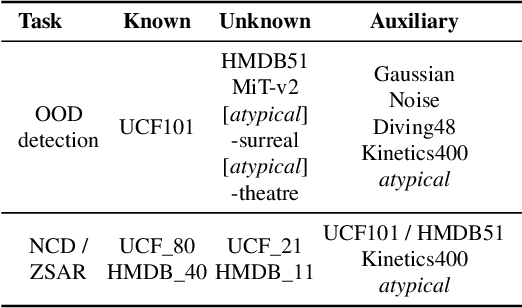
Humans usually show exceptional generalisation and discovery ability in the open world, when being shown uncommon new concepts. Whereas most existing studies in the literature focus on common typical data from closed sets, open-world novel discovery is under-explored in videos. In this paper, we are interested in asking: \textit{What if atypical unusual videos are exposed in the learning process?} To this end, we collect a new video dataset consisting of various types of unusual atypical data (\eg sci-fi, animation, \etc). To study how such atypical data may benefit open-world learning, we feed them into the model training process for representation learning. Focusing on three key tasks in open-world learning: out-of-distribution (OOD) detection, novel category discovery (NCD), and zero-shot action recognition (ZSAR), we found that even straightforward learning approaches with atypical data consistently improve performance across various settings. Furthermore, we found that increasing the categorical diversity of the atypical samples further boosts OOD detection performance. Additionally, in the NCD task, using a smaller yet more semantically diverse set of atypical samples leads to better performance compared to using a larger but more typical dataset. In the ZSAR setting, the semantic diversity of atypical videos helps the model generalise better to unseen action classes. These observations in our extensive experimental evaluations reveal the benefits of atypical videos for visual representation learning in the open world, together with the newly proposed dataset, encouraging further studies in this direction.
Revealing Temporal Label Noise in Multimodal Hateful Video Classification
Aug 06, 2025The rapid proliferation of online multimedia content has intensified the spread of hate speech, presenting critical societal and regulatory challenges. While recent work has advanced multimodal hateful video detection, most approaches rely on coarse, video-level annotations that overlook the temporal granularity of hateful content. This introduces substantial label noise, as videos annotated as hateful often contain long non-hateful segments. In this paper, we investigate the impact of such label ambiguity through a fine-grained approach. Specifically, we trim hateful videos from the HateMM and MultiHateClip English datasets using annotated timestamps to isolate explicitly hateful segments. We then conduct an exploratory analysis of these trimmed segments to examine the distribution and characteristics of both hateful and non-hateful content. This analysis highlights the degree of semantic overlap and the confusion introduced by coarse, video-level annotations. Finally, controlled experiments demonstrated that time-stamp noise fundamentally alters model decision boundaries and weakens classification confidence, highlighting the inherent context dependency and temporal continuity of hate speech expression. Our findings provide new insights into the temporal dynamics of multimodal hateful videos and highlight the need for temporally aware models and benchmarks for improved robustness and interpretability. Code and data are available at https://github.com/Multimodal-Intelligence-Lab-MIL/HatefulVideoLabelNoise.
LocalDyGS: Multi-view Global Dynamic Scene Modeling via Adaptive Local Implicit Feature Decoupling
Jul 03, 2025Due to the complex and highly dynamic motions in the real world, synthesizing dynamic videos from multi-view inputs for arbitrary viewpoints is challenging. Previous works based on neural radiance field or 3D Gaussian splatting are limited to modeling fine-scale motion, greatly restricting their application. In this paper, we introduce LocalDyGS, which consists of two parts to adapt our method to both large-scale and fine-scale motion scenes: 1) We decompose a complex dynamic scene into streamlined local spaces defined by seeds, enabling global modeling by capturing motion within each local space. 2) We decouple static and dynamic features for local space motion modeling. A static feature shared across time steps captures static information, while a dynamic residual field provides time-specific features. These are combined and decoded to generate Temporal Gaussians, modeling motion within each local space. As a result, we propose a novel dynamic scene reconstruction framework to model highly dynamic real-world scenes more realistically. Our method not only demonstrates competitive performance on various fine-scale datasets compared to state-of-the-art (SOTA) methods, but also represents the first attempt to model larger and more complex highly dynamic scenes. Project page: https://wujh2001.github.io/LocalDyGS/.
CoMBO: Conflict Mitigation via Branched Optimization for Class Incremental Segmentation
Apr 05, 2025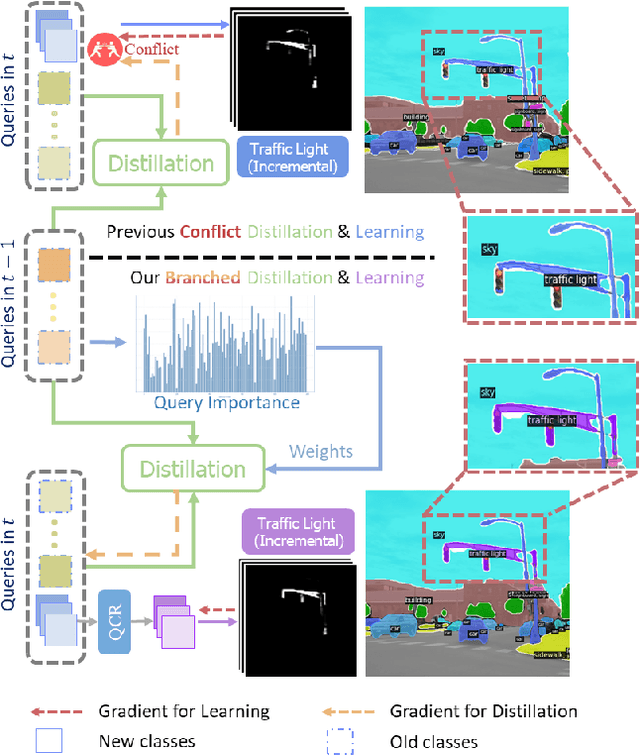
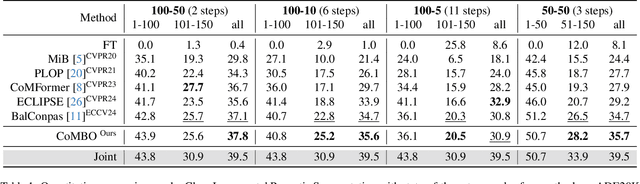
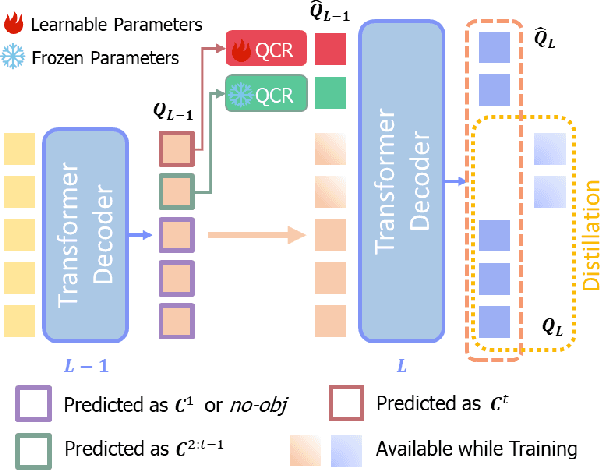
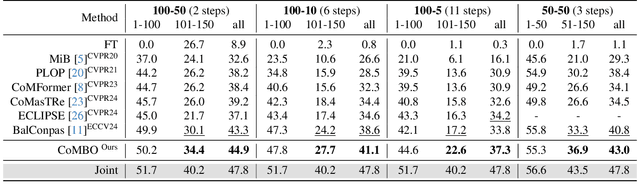
Effective Class Incremental Segmentation (CIS) requires simultaneously mitigating catastrophic forgetting and ensuring sufficient plasticity to integrate new classes. The inherent conflict above often leads to a back-and-forth, which turns the objective into finding the balance between the performance of previous~(old) and incremental~(new) classes. To address this conflict, we introduce a novel approach, Conflict Mitigation via Branched Optimization~(CoMBO). Within this approach, we present the Query Conflict Reduction module, designed to explicitly refine queries for new classes through lightweight, class-specific adapters. This module provides an additional branch for the acquisition of new classes while preserving the original queries for distillation. Moreover, we develop two strategies to further mitigate the conflict following the branched structure, \textit{i.e.}, the Half-Learning Half-Distillation~(HDHL) over classification probabilities, and the Importance-Based Knowledge Distillation~(IKD) over query features. HDHL selectively engages in learning for classification probabilities of queries that match the ground truth of new classes, while aligning unmatched ones to the corresponding old probabilities, thus ensuring retention of old knowledge while absorbing new classes via learning negative samples. Meanwhile, IKD assesses the importance of queries based on their matching degree to old classes, prioritizing the distillation of important features and allowing less critical features to evolve. Extensive experiments in Class Incremental Panoptic and Semantic Segmentation settings have demonstrated the superior performance of CoMBO. Project page: https://guangyu-ryan.github.io/CoMBO.
MVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Mar 11, 2025



3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
CL-MVSNet: Unsupervised Multi-view Stereo with Dual-level Contrastive Learning
Mar 11, 2025
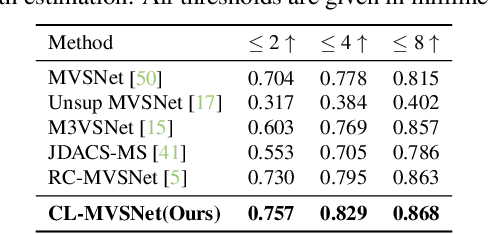
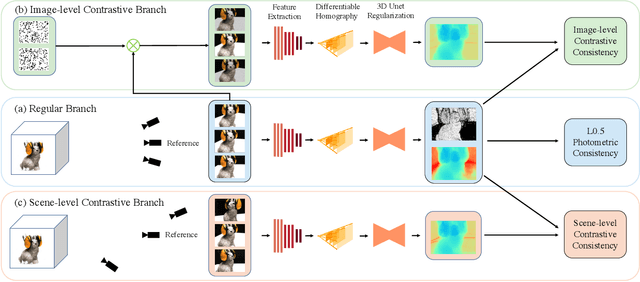
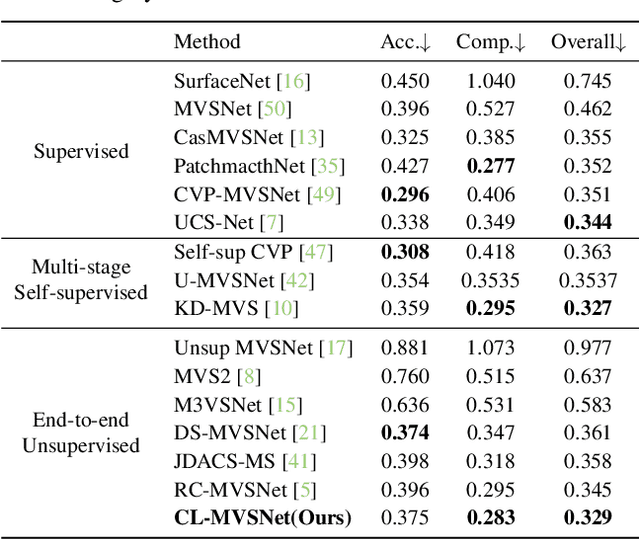
Unsupervised Multi-View Stereo (MVS) methods have achieved promising progress recently. However, previous methods primarily depend on the photometric consistency assumption, which may suffer from two limitations: indistinguishable regions and view-dependent effects, e.g., low-textured areas and reflections. To address these issues, in this paper, we propose a new dual-level contrastive learning approach, named CL-MVSNet. Specifically, our model integrates two contrastive branches into an unsupervised MVS framework to construct additional supervisory signals. On the one hand, we present an image-level contrastive branch to guide the model to acquire more context awareness, thus leading to more complete depth estimation in indistinguishable regions. On the other hand, we exploit a scene-level contrastive branch to boost the representation ability, improving robustness to view-dependent effects. Moreover, to recover more accurate 3D geometry, we introduce an L0.5 photometric consistency loss, which encourages the model to focus more on accurate points while mitigating the gradient penalty of undesirable ones. Extensive experiments on DTU and Tanks&Temples benchmarks demonstrate that our approach achieves state-of-the-art performance among all end-to-end unsupervised MVS frameworks and outperforms its supervised counterpart by a considerable margin without fine-tuning.