 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Noisy Preferences: A Semi-Supervised Learning Approach to Direct Preference Optimization
Apr 27, 2026Human visual preferences are inherently multi-dimensional, encompassing aesthetics, detail fidelity, and semantic alignment. However, existing datasets provide only single, holistic annotations, resulting in severe label noise: images that excel in some dimensions but are deficient in others are simply marked as winner or loser. We theoretically demonstrate that compressing multi-dimensional preferences into binary labels generates conflicting gradient signals that misguide Diffusion Direct Preference Optimization (DPO). To address this, we propose Semi-DPO, a semi-supervised approach that treats consistent pairs as clean labeled data and conflicting ones as noisy unlabeled data. Our method starts by training on a consensus-filtered clean subset, then uses this model as an implicit classifier to generate pseudo-labels for the noisy set for iterative refinement. Experimental results demonstrate that Semi-DPO achieves state-of-the-art performance and significantly improves alignment with complex human preferences, without requiring additional human annotation or explicit reward models during training. We will release our code and models at: https://github.com/L-CodingSpace/semi-dpo
Geo$^\textbf{2}$: Geometry-Guided Cross-view Geo-Localization and Image Synthesis
Mar 26, 2026Cross-view geo-spatial learning consists of two important tasks: Cross-View Geo-Localization (CVGL) and Cross-View Image Synthesis (CVIS), both of which rely on establishing geometric correspondences between ground and aerial views. Recent Geometric Foundation Models (GFMs) have demonstrated strong capabilities in extracting generalizable 3D geometric features from images, but their potential in cross-view geo-spatial tasks remains underexplored. In this work, we present Geo^2, a unified framework that leverages Geometric priors from GFMs (e.g., VGGT) to jointly perform geo-spatial tasks, CVGL and bidirectional CVIS. Despite the 3D reconstruction ability of GFMs, directly applying them to CVGL and CVIS remains challenging due to the large viewpoint gap between ground and aerial imagery. We propose GeoMap, which embeds ground and aerial features into a shared 3D-aware latent space, effectively reducing cross-view discrepancies for localization. This shared latent space naturally bridges cross-view image synthesis in both directions. To exploit this, we propose GeoFlow, a flow-matching model conditioned on geometry-aware latent embeddings. We further introduce a consistency loss to enforce latent alignment between the two synthesis directions, ensuring bidirectional coherence. Extensive experiments on standard benchmarks, including CVUSA, CVACT, and VIGOR, demonstrate that Geo^2 achieves state-of-the-art performance in both localization and synthesis, highlighting the effectiveness of 3D geometric priors for cross-view geo-spatial learning.
CPO: Condition Preference Optimization for Controllable Image Generation
Nov 06, 2025To enhance controllability in text-to-image generation, ControlNet introduces image-based control signals, while ControlNet++ improves pixel-level cycle consistency between generated images and the input control signal. To avoid the prohibitive cost of back-propagating through the sampling process, ControlNet++ optimizes only low-noise timesteps (e.g., $t < 200$) using a single-step approximation, which not only ignores the contribution of high-noise timesteps but also introduces additional approximation errors. A straightforward alternative for optimizing controllability across all timesteps is Direct Preference Optimization (DPO), a fine-tuning method that increases model preference for more controllable images ($I^{w}$) over less controllable ones ($I^{l}$). However, due to uncertainty in generative models, it is difficult to ensure that win--lose image pairs differ only in controllability while keeping other factors, such as image quality, fixed. To address this, we propose performing preference learning over control conditions rather than generated images. Specifically, we construct winning and losing control signals, $\mathbf{c}^{w}$ and $\mathbf{c}^{l}$, and train the model to prefer $\mathbf{c}^{w}$. This method, which we term \textit{Condition Preference Optimization} (CPO), eliminates confounding factors and yields a low-variance training objective. Our approach theoretically exhibits lower contrastive loss variance than DPO and empirically achieves superior results. Moreover, CPO requires less computation and storage for dataset curation. Extensive experiments show that CPO significantly improves controllability over the state-of-the-art ControlNet++ across multiple control types: over $10\%$ error rate reduction in segmentation, $70$--$80\%$ in human pose, and consistent $2$--$5\%$ reductions in edge and depth maps.
Tell Me Where You Are: Multimodal LLMs Meet Place Recognition
Jun 25, 2024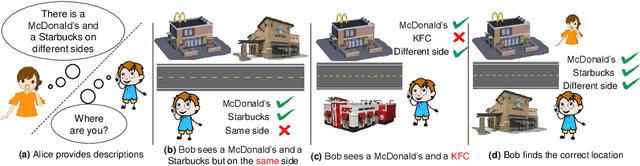
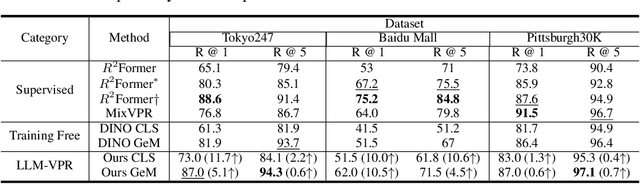
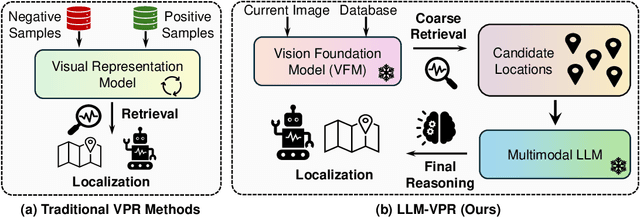
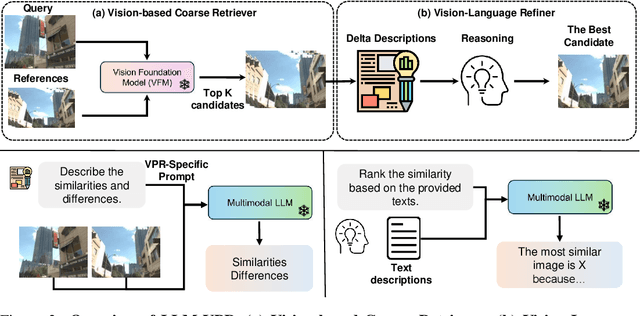
Large language models (LLMs) exhibit a variety of promising capabilities in robotics, including long-horizon planning and commonsense reasoning. However, their performance in place recognition is still underexplored. In this work, we introduce multimodal LLMs (MLLMs) to visual place recognition (VPR), where a robot must localize itself using visual observations. Our key design is to use vision-based retrieval to propose several candidates and then leverage language-based reasoning to carefully inspect each candidate for a final decision. Specifically, we leverage the robust visual features produced by off-the-shelf vision foundation models (VFMs) to obtain several candidate locations. We then prompt an MLLM to describe the differences between the current observation and each candidate in a pairwise manner, and reason about the best candidate based on these descriptions. Our results on three datasets demonstrate that integrating the general-purpose visual features from VFMs with the reasoning capabilities of MLLMs already provides an effective place recognition solution, without any VPR-specific supervised training. We believe our work can inspire new possibilities for applying and designing foundation models, i.e., VFMs, LLMs, and MLLMs, to enhance the localization and navigation of mobile robots.
Multiagent Multitraversal Multimodal Self-Driving: Open MARS Dataset
Jun 13, 2024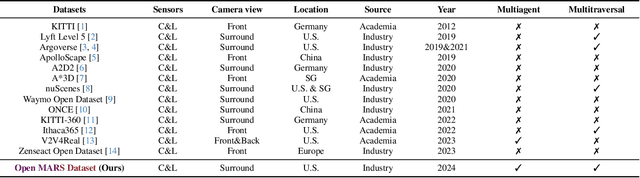


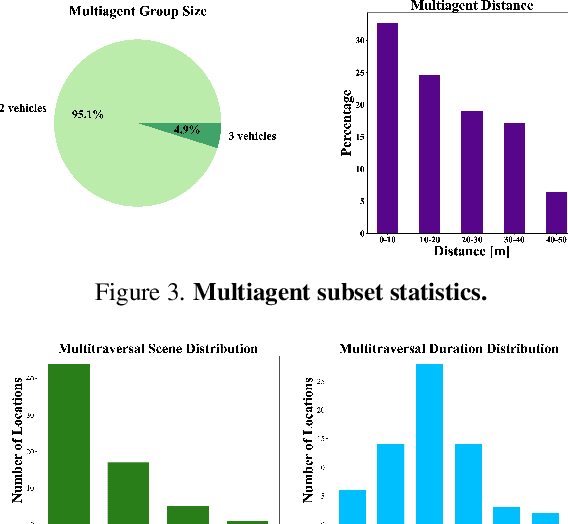
Large-scale datasets have fueled recent advancements in AI-based autonomous vehicle research. However, these datasets are usually collected from a single vehicle's one-time pass of a certain location, lacking multiagent interactions or repeated traversals of the same place. Such information could lead to transformative enhancements in autonomous vehicles' perception, prediction, and planning capabilities. To bridge this gap, in collaboration with the self-driving company May Mobility, we present the MARS dataset which unifies scenarios that enable MultiAgent, multitraveRSal, and multimodal autonomous vehicle research. More specifically, MARS is collected with a fleet of autonomous vehicles driving within a certain geographical area. Each vehicle has its own route and different vehicles may appear at nearby locations. Each vehicle is equipped with a LiDAR and surround-view RGB cameras. We curate two subsets in MARS: one facilitates collaborative driving with multiple vehicles simultaneously present at the same location, and the other enables memory retrospection through asynchronous traversals of the same location by multiple vehicles. We conduct experiments in place recognition and neural reconstruction. More importantly, MARS introduces new research opportunities and challenges such as multitraversal 3D reconstruction, multiagent perception, and unsupervised object discovery. Our data and codes can be found at https://ai4ce.github.io/MARS/.
Frame Interpolation with Consecutive Brownian Bridge Diffusion
May 09, 2024



Recent work in Video Frame Interpolation (VFI) tries to formulate VFI as a diffusion-based conditional image generation problem, synthesizing the intermediate frame given a random noise and neighboring frames. Due to the relatively high resolution of videos, Latent Diffusion Models (LDMs) are employed as the conditional generation model, where the autoencoder compresses images into latent representations for diffusion and then reconstructs images from these latent representations. Such a formulation poses a crucial challenge: VFI expects that the output is deterministically equal to the ground truth intermediate frame, but LDMs randomly generate a diverse set of different images when the model runs multiple times. The reason for the diverse generation is that the cumulative variance (variance accumulated at each step of generation) of generated latent representations in LDMs is large. This makes the sampling trajectory random, resulting in diverse rather than deterministic generations. To address this problem, we propose our unique solution: Frame Interpolation with Consecutive Brownian Bridge Diffusion. Specifically, we propose consecutive Brownian Bridge diffusion that takes a deterministic initial value as input, resulting in a much smaller cumulative variance of generated latent representations. Our experiments suggest that our method can improve together with the improvement of the autoencoder and achieve state-of-the-art performance in VFI, leaving strong potential for further enhancement.
Collaborative Visual Place Recognition
Oct 09, 2023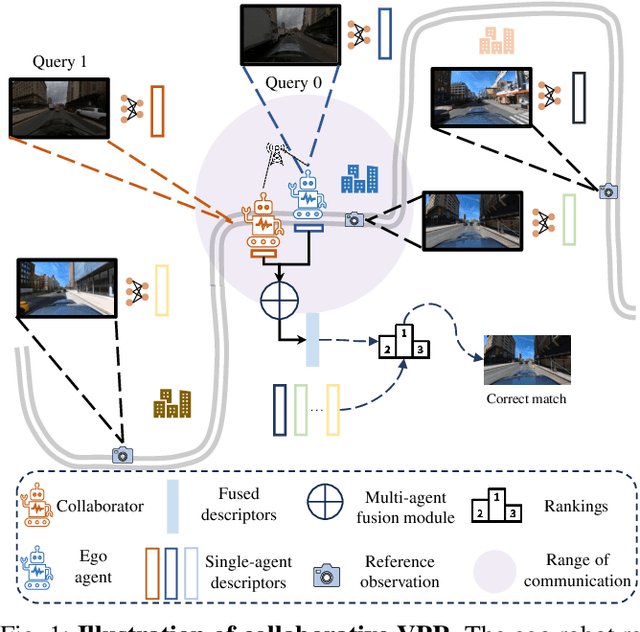
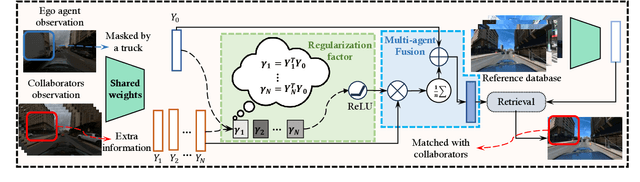
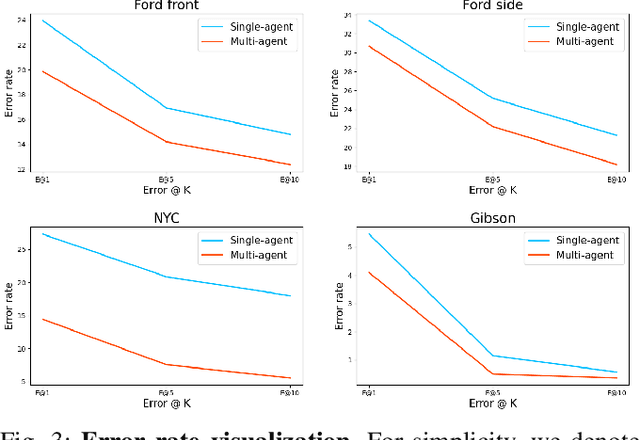

Visual place recognition (VPR) capabilities enable autonomous robots to navigate complex environments by discovering the environment's topology based on visual input. Most research efforts focus on enhancing the accuracy and robustness of single-robot VPR but often encounter issues such as occlusion due to individual viewpoints. Despite a number of research on multi-robot metric-based localization, there is a notable gap in research concerning more robust and efficient place-based localization with a multi-robot system. This work proposes collaborative VPR, where multiple robots share abstracted visual features to enhance place recognition capabilities. We also introduce a novel collaborative VPR framework based on similarity-regularized information fusion, reducing irrelevant noise while harnessing valuable data from collaborators. This framework seamlessly integrates with well-established single-robot VPR techniques and supports end-to-end training with a weakly-supervised contrastive loss. We conduct experiments in urban, rural, and indoor scenes, achieving a notable improvement over single-agent VPR in urban environments (~12\%), along with consistent enhancements in rural (~3\%) and indoor (~1\%) scenarios. Our work presents a promising solution to the pressing challenges of VPR, representing a substantial step towards safe and robust autonomous systems.