 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me Where You Are: Multimodal LLMs Meet Place Recognition
Paper and Code
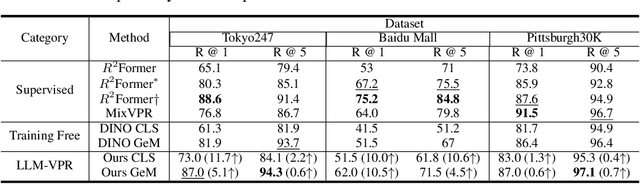
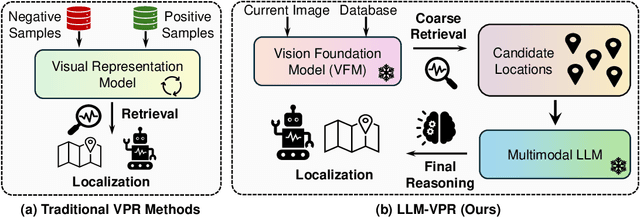
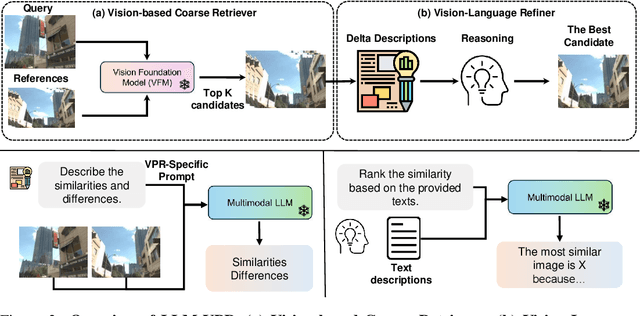
Large language models (LLMs) exhibit a variety of promising capabilities in robotics, including long-horizon planning and commonsense reasoning. However, their performance in place recognition is still underexplored. In this work, we introduce multimodal LLMs (MLLMs) to visual place recognition (VPR), where a robot must localize itself using visual observations. Our key design is to use vision-based retrieval to propose several candidates and then leverage language-based reasoning to carefully inspect each candidate for a final decision. Specifically, we leverage the robust visual features produced by off-the-shelf vision foundation models (VFMs) to obtain several candidate locations. We then prompt an MLLM to describe the differences between the current observation and each candidate in a pairwise manner, and reason about the best candidate based on these descriptions. Our results on three datasets demonstrate that integrating the general-purpose visual features from VFMs with the reasoning capabilities of MLLMs already provides an effective place recognition solution, without any VPR-specific supervised training. We believe our work can inspire new possibilities for applying and designing foundation models, i.e., VFMs, LLMs, and MLLMs, to enhance the localization and navigation of mobile robots.