 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me Where You Are: Multimodal LLMs Meet Place Recognition
Jun 25, 2024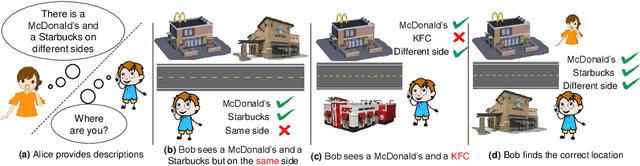
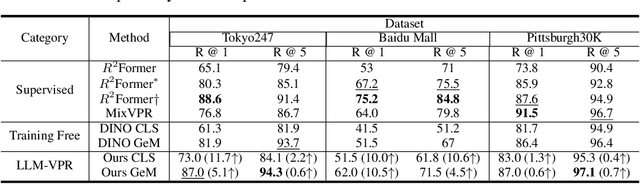
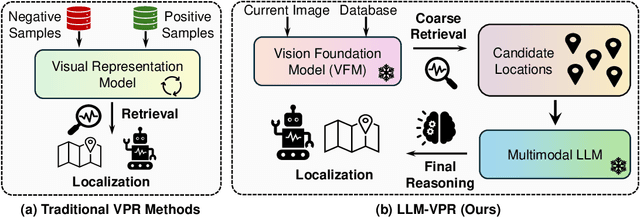
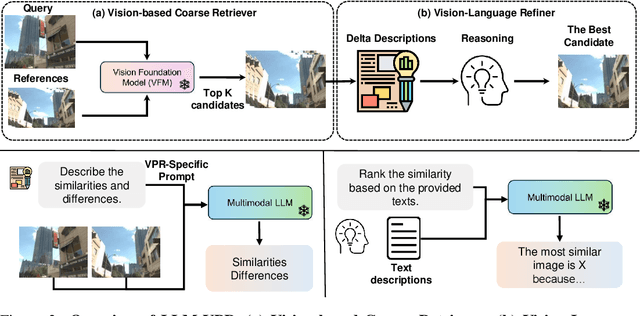
Large language models (LLMs) exhibit a variety of promising capabilities in robotics, including long-horizon planning and commonsense reasoning. However, their performance in place recognition is still underexplored. In this work, we introduce multimodal LLMs (MLLMs) to visual place recognition (VPR), where a robot must localize itself using visual observations. Our key design is to use vision-based retrieval to propose several candidates and then leverage language-based reasoning to carefully inspect each candidate for a final decision. Specifically, we leverage the robust visual features produced by off-the-shelf vision foundation models (VFMs) to obtain several candidate locations. We then prompt an MLLM to describe the differences between the current observation and each candidate in a pairwise manner, and reason about the best candidate based on these descriptions. Our results on three datasets demonstrate that integrating the general-purpose visual features from VFMs with the reasoning capabilities of MLLMs already provides an effective place recognition solution, without any VPR-specific supervised training. We believe our work can inspire new possibilities for applying and designing foundation models, i.e., VFMs, LLMs, and MLLMs, to enhance the localization and navigation of mobile robots.
Collaborative Visual Place Recognition
Oct 09, 2023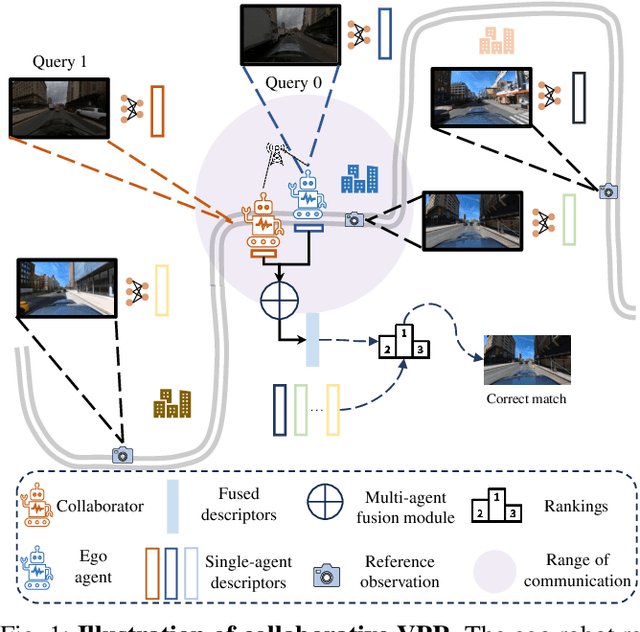
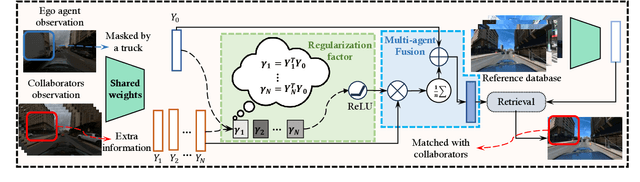
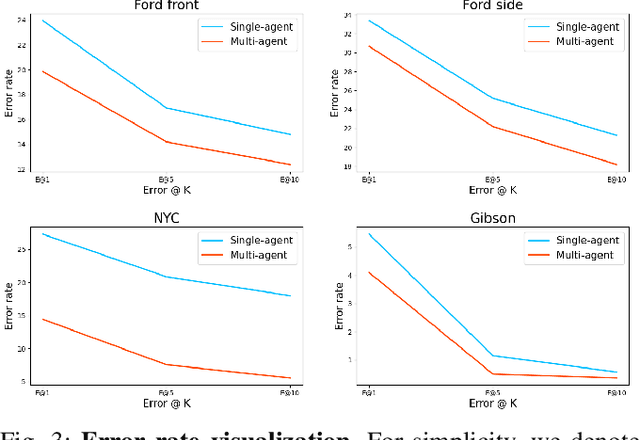

Visual place recognition (VPR) capabilities enable autonomous robots to navigate complex environments by discovering the environment's topology based on visual input. Most research efforts focus on enhancing the accuracy and robustness of single-robot VPR but often encounter issues such as occlusion due to individual viewpoints. Despite a number of research on multi-robot metric-based localization, there is a notable gap in research concerning more robust and efficient place-based localization with a multi-robot system. This work proposes collaborative VPR, where multiple robots share abstracted visual features to enhance place recognition capabilities. We also introduce a novel collaborative VPR framework based on similarity-regularized information fusion, reducing irrelevant noise while harnessing valuable data from collaborators. This framework seamlessly integrates with well-established single-robot VPR techniques and supports end-to-end training with a weakly-supervised contrastive loss. We conduct experiments in urban, rural, and indoor scenes, achieving a notable improvement over single-agent VPR in urban environments (~12\%), along with consistent enhancements in rural (~3\%) and indoor (~1\%) scenarios. Our work presents a promising solution to the pressing challenges of VPR, representing a substantial step towards safe and robust autonomous systems.
BRIGHT -- Graph Neural Networks in Real-Time Fraud Detection
May 25, 2022
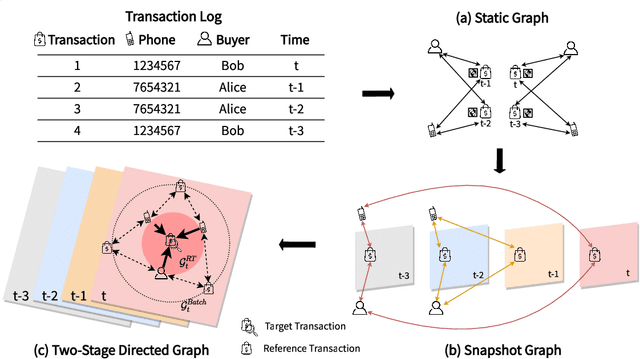

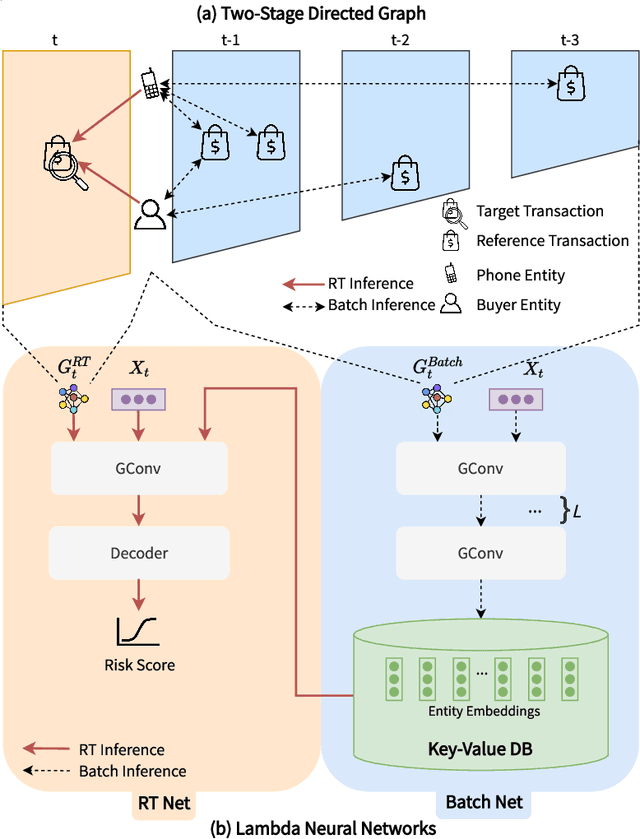
Detecting fraudulent transactions is an essential component to control risk in e-commerce marketplaces. Apart from rule-based and machine learning filters that are already deployed in production, we want to enable efficient real-time inference with graph neural networks (GNNs), which is useful to catch multihop risk propagation in a transaction graph. However, two challenges arise in the implementation of GNNs in production. First, future information in a dynamic graph should not be considered in message passing to predict the past. Second, the latency of graph query and GNN model inference is usually up to hundreds of milliseconds, which is costly for some critical online services. To tackle these challenges, we propose a Batch and Real-time Inception GrapH Topology (BRIGHT) framework to conduct an end-to-end GNN learning that allows efficient online real-time inference. BRIGHT framework consists of a graph transformation module (Two-Stage Directed Graph) and a corresponding GNN architecture (Lambda Neural Network). The Two-Stage Directed Graph guarantees that the information passed through neighbors is only from the historical payment transactions. It consists of two subgraphs representing historical relationships and real-time links, respectively. The Lambda Neural Network decouples inference into two stages: batch inference of entity embeddings and real-time inference of transaction prediction. Our experiments show that BRIGHT outperforms the baseline models by >2\% in average w.r.t.~precision. Furthermore, BRIGHT is computationally efficient for real-time fraud detection. Regarding end-to-end performance (including neighbor query and inference), BRIGHT can reduce the P99 latency by >75\%. For the inference stage, our speedup is on average 7.8$\times$ compared to the traditional GNN.
Graph Neural Networks in Real-Time Fraud Detection with Lambda Architecture
Oct 09, 2021
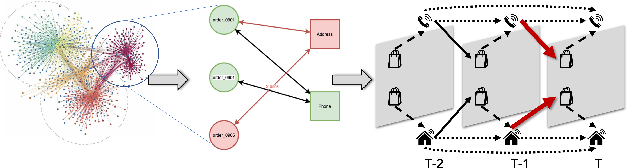

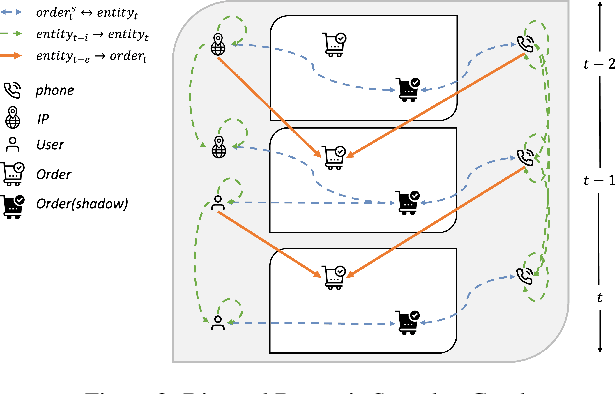
Transaction checkout fraud detection is an essential risk control components for E-commerce marketplaces. In order to leverage graph networks to decrease fraud rate efficiently and guarantee the information flow passed through neighbors only from the past of the checkouts, we first present a novel Directed Dynamic Snapshot (DDS) linkage design for graph construction and a Lambda Neural Networks (LNN) architecture for effective inference with Graph Neural Networks embeddings. Experiments show that our LNN on DDS graph, outperforms baseline models significantly and is computational efficient for real-time fraud detection.