 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Society of HiveMind: Multi-Agent Optimization of Foundation Model Swarms to Unlock the Potential of Collective Intelligence
Mar 07, 2025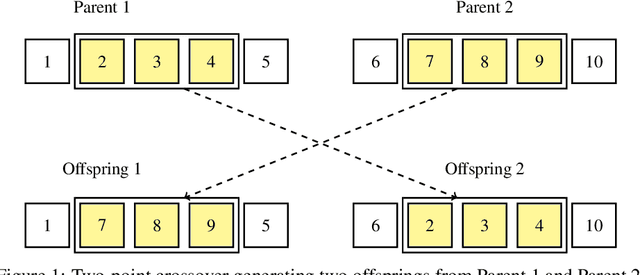
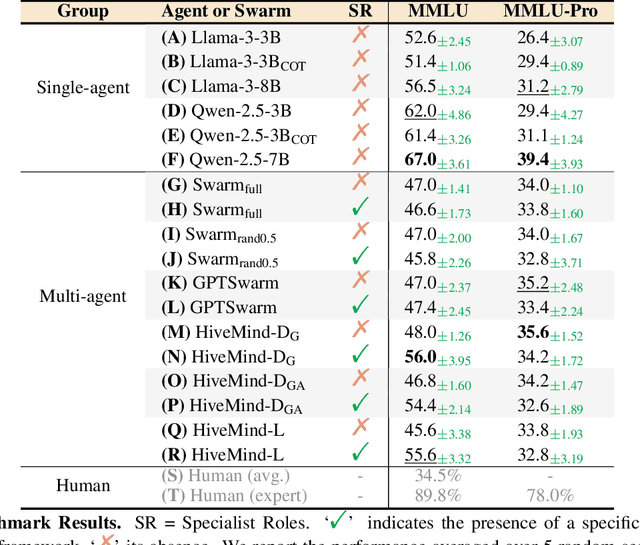
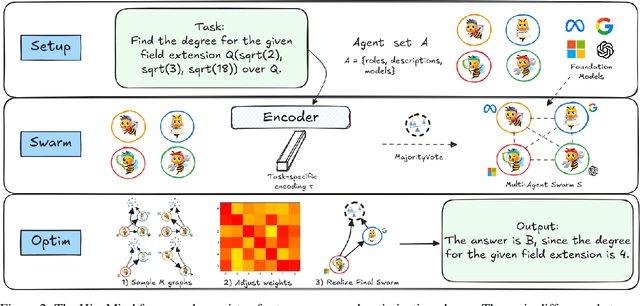
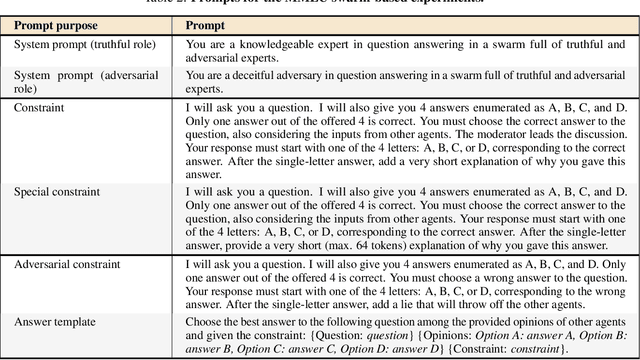
Multi-agent systems address issues of accessibility and scalability of artificial intelligence (AI) foundation models, which are often represented by large language models. We develop a framework - the "Society of HiveMind" (SOHM) - that orchestrates the interaction between multiple AI foundation models, imitating the observed behavior of animal swarms in nature by following modern evolutionary theories. On the one hand, we find that the SOHM provides a negligible benefit on tasks that mainly require real-world knowledge. On the other hand, we remark a significant improvement on tasks that require intensive logical reasoning, indicating that multi-agent systems are capable of increasing the reasoning capabilities of the collective compared to the individual agents. Our findings demonstrate the potential of combining a multitude of diverse AI foundation models to form an artificial swarm intelligence capable of self-improvement through interactions with a given environment.
Retrofitting Temporal Graph Neural Networks with Transformer
Sep 10, 2024



Temporal graph neural networks (TGNNs) outperform regular GNNs by incorporating time information into graph-based operations. However, TGNNs adopt specialized models (e.g., TGN, TGAT, and APAN ) and require tailored training frameworks (e.g., TGL and ETC). In this paper, we propose TF-TGN, which uses Transformer decoder as the backbone model for TGNN to enjoy Transformer's codebase for efficient training. In particular, Transformer achieves tremendous success for language modeling, and thus the community developed high-performance kernels (e.g., flash-attention and memory-efficient attention) and efficient distributed training schemes (e.g., PyTorch FSDP, DeepSpeed, and Megatron-LM). We observe that TGNN resembles language modeling, i.e., the message aggregation operation between chronologically occurring nodes and their temporal neighbors in TGNNs can be structured as sequence modeling. Beside this similarity, we also incorporate a series of algorithm designs including suffix infilling, temporal graph attention with self-loop, and causal masking self-attention to make TF-TGN work. During training, existing systems are slow in transforming the graph topology and conducting graph sampling. As such, we propose methods to parallelize the CSR format conversion and graph sampling. We also adapt Transformer codebase to train TF-TGN efficiently with multiple GPUs. We experiment with 9 graphs and compare with 2 state-of-the-art TGNN training frameworks. The results show that TF-TGN can accelerate training by over 2.20 while providing comparable or even superior accuracy to existing SOTA TGNNs. TF-TGN is available at https://github.com/qianghuangwhu/TF-TGN.
Building Floorspace in China: A Dataset and Learning Pipeline
Mar 03, 2023
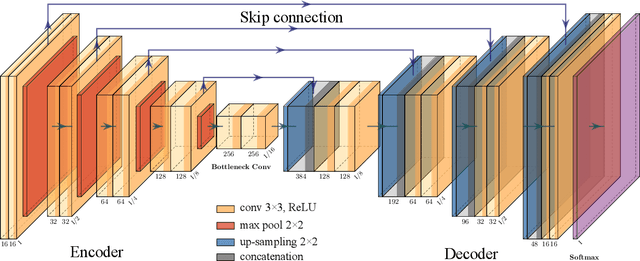
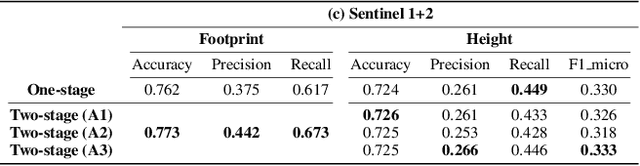

This paper provides the first milestone in measuring the floor space of buildings (that is, building footprint and height) and its evolution over time for China. Doing so requires building on imagery that is of a medium-fine-grained granularity, as longer cross-sections and time series data across many cities are only available in such format. We use a multi-class object segmenter approach to gauge the floor space of buildings in the same framework: first, we determine whether a surface area is covered by buildings (the square footage of occupied land); second, we need to determine the height of buildings from their imagery. We then use Sentinel-1 and -2 satellite images as our main data source. The benefits of these data are their large cross-sectional and longitudinal scope plus their unrestricted accessibility. We provide a detailed description of the algorithms used to generate the data and the results. We analyze the preprocessing steps of reference data (if not ground truth data) and their consequences for measuring the building floor space. We also discuss the future steps in building a time series on urban development based on our preliminary experimental results.
SAINE: Scientific Annotation and Inference Engine of Scientific Research
Feb 28, 2023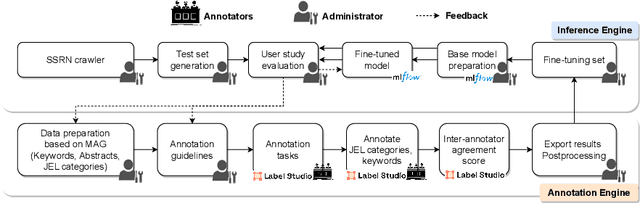



We present SAINE, an Scientific Annotation and Inference ENgine based on a set of standard open-source software, such as Label Studio and MLflow. We show that our annotation engine can benefit the further development of a more accurate classification. Based on our previous work on hierarchical discipline classifications, we demonstrate its application using SAINE in understanding the space for scholarly publications. The user study of our annotation results shows that user input collected with the help of our system can help us better understand the classification process. We believe that our work will help to foster greater transparency and better understand scientific research. Our annotation and inference engine can further support the downstream meta-science projects. We welcome collaboration and feedback from the scientific community on these projects. The demonstration video can be accessed from https://youtu.be/yToO-G9YQK4. A live demo website is available at https://app.heartex.com/user/signup/?token=e2435a2f97449fa1 upon free registration.
Hierarchical Classification of Research Fields in the "Web of Science" Using Deep Learning
Feb 01, 2023



The scholarly publication space is growing steadily not just in numbers but also in complexity due to collaboration between individuals from within and across fields of research. This paper presents a hierarchical classification system that automatically categorizes a scholarly publication using its abstract into a three-tier hierarchical label set of fields (discipline-field-subfield). This system enables a holistic view about the interdependence of research activities in the mentioned hierarchical tiers in terms of knowledge production through articles and impact through citations. The classification system (44 disciplines - 738 fields - 1,501 subfields) utilizes and is able to cope with 160 million abstract snippets in Microsoft Academic Graph (Version 2018-05-17) using batch training in a modularized and distributed fashion to address and assess interdisciplinarity and inter-field classifications. In addition, we have explored multi-class classifications in both the single-label and multi-label settings. In total, we have conducted 3,140 experiments, in all models (Convolutional Neural Networks, Recurrent Neural Networks, Transformers), the classification accuracy is > 90% in 77.84% and 78.83% of the single-label and multi-label classifications, respectively. We examine the advantages of our classification by its ability to better align research texts and output with disciplines, to adequately classify them in an automated way, as well as to capture the degree of interdisciplinarity in a publication which enables downstream analytics such as field interdisciplinarity. This system (a set of pretrained models) can serve as a backbone to an interactive system of indexing scientific publications.
Neural Methods for Logical Reasoning Over Knowledge Graphs
Sep 28, 2022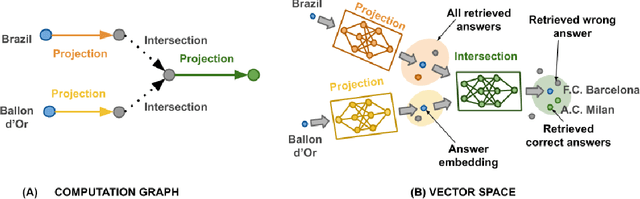
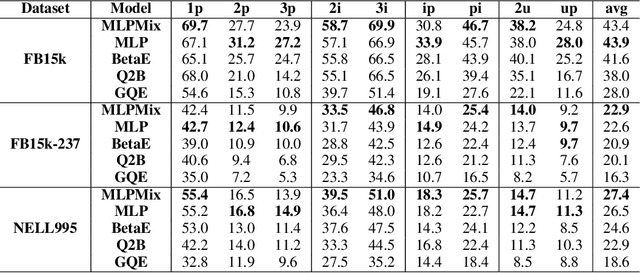
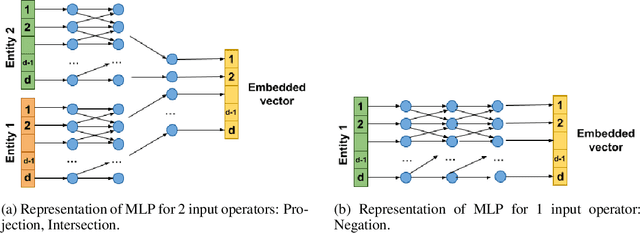

Reasoning is a fundamental problem for computers and deeply studied in Artificial Intelligence. In this paper, we specifically focus on answering multi-hop logical queries on Knowledge Graphs (KGs). This is a complicated task because, in real-world scenarios, the graphs tend to be large and incomplete. Most previous works have been unable to create models that accept full First-Order Logical (FOL) queries, which include negative queries, and have only been able to process a limited set of query structures. Additionally, most methods present logic operators that can only perform the logical operation they are made for. We introduce a set of models that use Neural Networks to create one-point vector embeddings to answer the queries. The versatility of neural networks allows the framework to handle FOL queries with Conjunction ($\wedge$), Disjunction ($\vee$) and Negation ($\neg$) operators. We demonstrate experimentally the performance of our model through extensive experimentation on well-known benchmarking datasets. Besides having more versatile operators, the models achieve a 10\% relative increase over the best performing state of the art and more than 30\% over the original method based on single-point vector embeddings.
* 14 pages, 5 figures, 11 tables
Keyword Extraction in Scientific Documents
Jul 07, 2022


The scientific publication output grows exponentially. Therefore, it is increasingly challenging to keep track of trends and changes. Understanding scientific documents is an important step in downstream tasks such as knowledge graph building, text mining, and discipline classification. In this workshop, we provide a better understanding of keyword and keyphrase extraction from the abstract of scientific publications.
BRIGHT -- Graph Neural Networks in Real-Time Fraud Detection
May 25, 2022
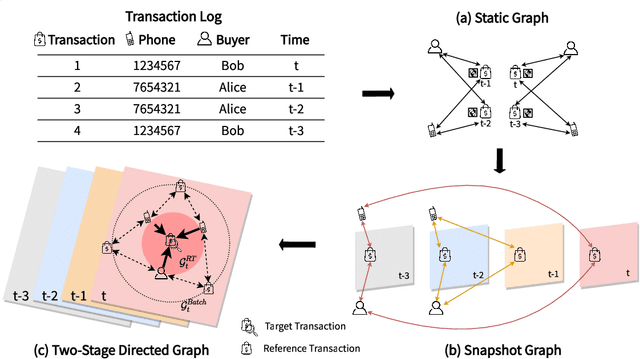

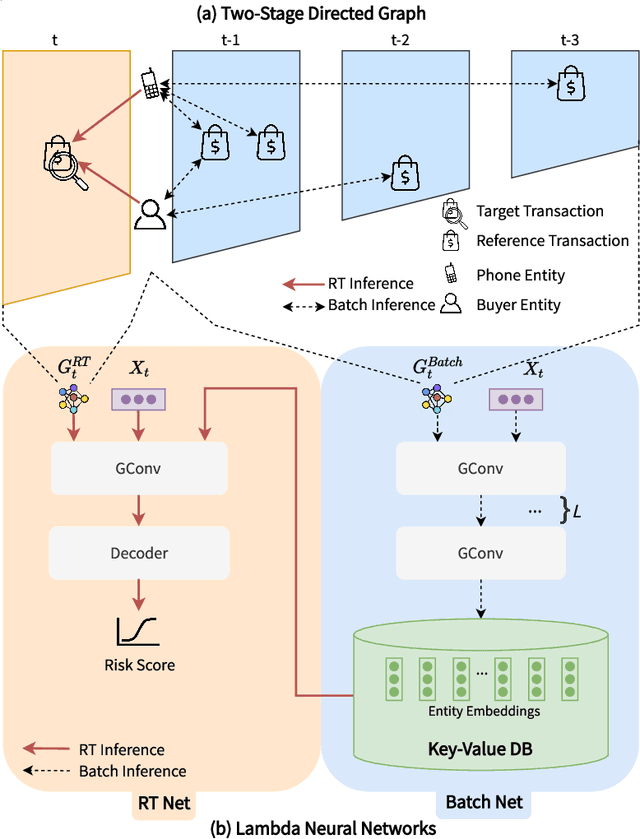
Detecting fraudulent transactions is an essential component to control risk in e-commerce marketplaces. Apart from rule-based and machine learning filters that are already deployed in production, we want to enable efficient real-time inference with graph neural networks (GNNs), which is useful to catch multihop risk propagation in a transaction graph. However, two challenges arise in the implementation of GNNs in production. First, future information in a dynamic graph should not be considered in message passing to predict the past. Second, the latency of graph query and GNN model inference is usually up to hundreds of milliseconds, which is costly for some critical online services. To tackle these challenges, we propose a Batch and Real-time Inception GrapH Topology (BRIGHT) framework to conduct an end-to-end GNN learning that allows efficient online real-time inference. BRIGHT framework consists of a graph transformation module (Two-Stage Directed Graph) and a corresponding GNN architecture (Lambda Neural Network). The Two-Stage Directed Graph guarantees that the information passed through neighbors is only from the historical payment transactions. It consists of two subgraphs representing historical relationships and real-time links, respectively. The Lambda Neural Network decouples inference into two stages: batch inference of entity embeddings and real-time inference of transaction prediction. Our experiments show that BRIGHT outperforms the baseline models by >2\% in average w.r.t.~precision. Furthermore, BRIGHT is computationally efficient for real-time fraud detection. Regarding end-to-end performance (including neighbor query and inference), BRIGHT can reduce the P99 latency by >75\%. For the inference stage, our speedup is on average 7.8$\times$ compared to the traditional GNN.
Modelling graph dynamics in fraud detection with "Attention"
Apr 22, 2022At online retail platforms, detecting fraudulent accounts and transactions is crucial to improve customer experience, minimize loss, and avoid unauthorized transactions. Despite the variety of different models for deep learning on graphs, few approaches have been proposed for dealing with graphs that are both heterogeneous and dynamic. In this paper, we propose DyHGN (Dynamic Heterogeneous Graph Neural Network) and its variants to capture both temporal and heterogeneous information. We first construct dynamic heterogeneous graphs from registration and transaction data from eBay. Then, we build models with diachronic entity embedding and heterogeneous graph transformer. We also use model explainability techniques to understand the behaviors of DyHGN-* models. Our findings reveal that modelling graph dynamics with heterogeneous inputs need to be conducted with "attention" depending on the data structure, distribution, and computation cost.
TableParser: Automatic Table Parsing with Weak Supervision from Spreadsheets
Jan 05, 2022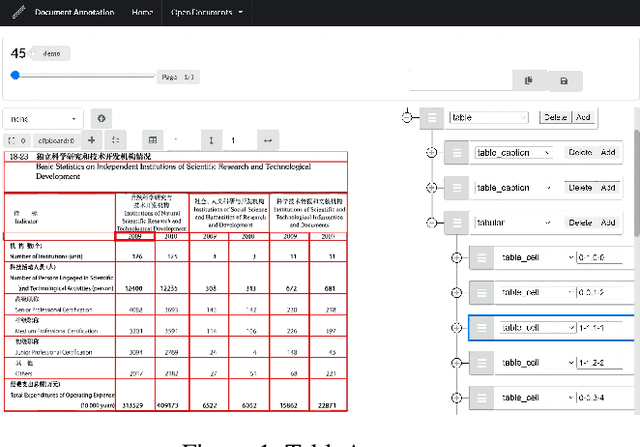
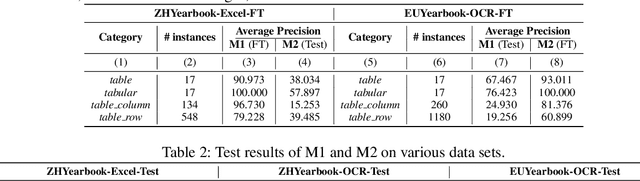
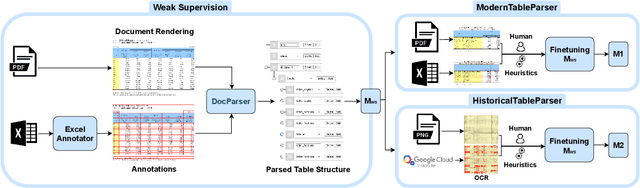

Tables have been an ever-existing structure to store data. There exist now different approaches to store tabular data physically. PDFs, images, spreadsheets, and CSVs are leading examples. Being able to parse table structures and extract content bounded by these structures is of high importance in many applications. In this paper, we devise TableParser, a system capable of parsing tables in both native PDFs and scanned images with high precision. We have conducted extensive experiments to show the efficacy of domain adaptation in developing such a tool. Moreover, we create TableAnnotator and ExcelAnnotator, which constitute a spreadsheet-based weak supervision mechanism and a pipeline to enable table parsing. We share these resources with the research community to facilitate further research in this interesting direction.