 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre the LLMs Capable of Maintaining at Least the Language Genus?
Oct 24, 2025Large Language Models (LLMs) display notable variation in multilingual behavior, yet the role of genealogical language structure in shaping this variation remains underexplored. In this paper, we investigate whether LLMs exhibit sensitivity to linguistic genera by extending prior analyses on the MultiQ dataset. We first check if models prefer to switch to genealogically related languages when prompt language fidelity is not maintained. Next, we investigate whether knowledge consistency is better preserved within than across genera. We show that genus-level effects are present but strongly conditioned by training resource availability. We further observe distinct multilingual strategies across LLMs families. Our findings suggest that LLMs encode aspects of genus-level structure, but training data imbalances remain the primary factor shaping their multilingual performance.
ChatGPT or Human? Detect and Explain. Explaining Decisions of Machine Learning Model for Detecting Short ChatGPT-generated Text
Jan 30, 2023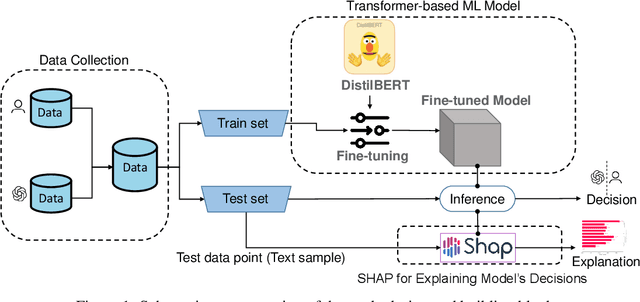
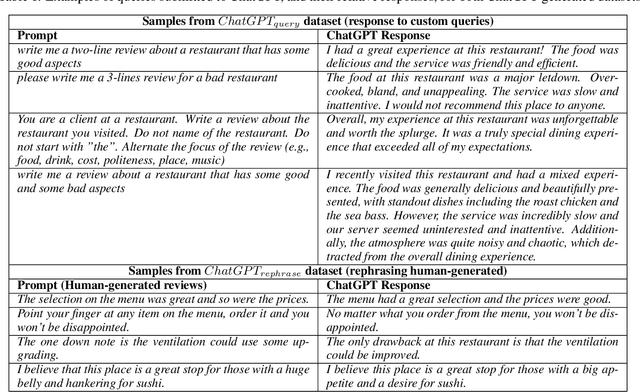
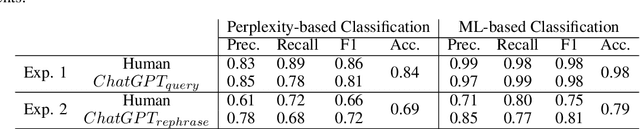
ChatGPT has the ability to generate grammatically flawless and seemingly-human replies to different types of questions from various domains. The number of its users and of its applications is growing at an unprecedented rate. Unfortunately, use and abuse come hand in hand. In this paper, we study whether a machine learning model can be effectively trained to accurately distinguish between original human and seemingly human (that is, ChatGPT-generated) text, especially when this text is short. Furthermore, we employ an explainable artificial intelligence framework to gain insight into the reasoning behind the model trained to differentiate between ChatGPT-generated and human-generated text. The goal is to analyze model's decisions and determine if any specific patterns or characteristics can be identified. Our study focuses on short online reviews, conducting two experiments comparing human-generated and ChatGPT-generated text. The first experiment involves ChatGPT text generated from custom queries, while the second experiment involves text generated by rephrasing original human-generated reviews. We fine-tune a Transformer-based model and use it to make predictions, which are then explained using SHAP. We compare our model with a perplexity score-based approach and find that disambiguation between human and ChatGPT-generated reviews is more challenging for the ML model when using rephrased text. However, our proposed approach still achieves an accuracy of 79%. Using explainability, we observe that ChatGPT's writing is polite, without specific details, using fancy and atypical vocabulary, impersonal, and typically it does not express feelings.
Keyword Extraction in Scientific Documents
Jul 07, 2022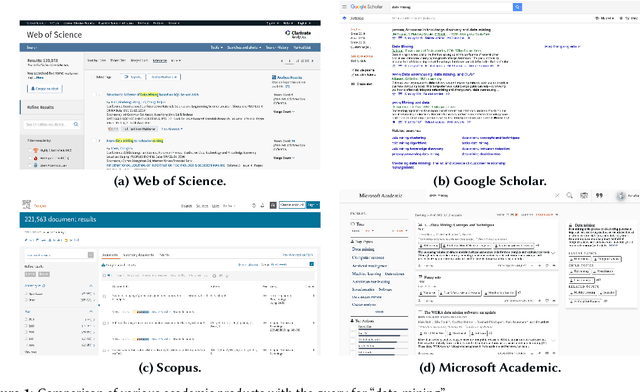


The scientific publication output grows exponentially. Therefore, it is increasingly challenging to keep track of trends and changes. Understanding scientific documents is an important step in downstream tasks such as knowledge graph building, text mining, and discipline classification. In this workshop, we provide a better understanding of keyword and keyphrase extraction from the abstract of scientific publications.
On Analyzing Annotation Consistency in Online Abusive Behavior Datasets
Jun 24, 2020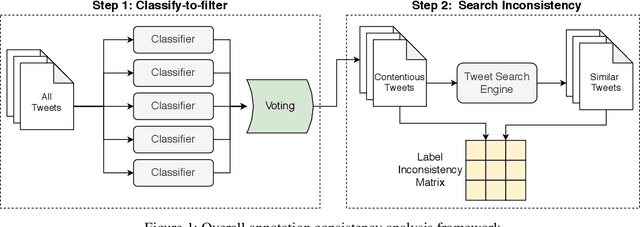

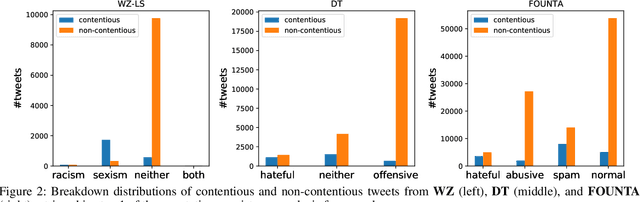
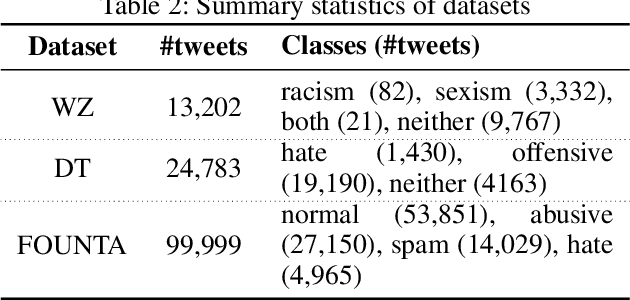
Online abusive behavior is an important issue that breaks the cohesiveness of online social communities and even raises public safety concerns in our societies. Motivated by this rising issue, researchers have proposed, collected, and annotated online abusive content datasets. These datasets play a critical role in facilitating the research on online hate speech and abusive behaviors. However, the annotation of such datasets is a difficult task; it is often contentious on what should be the true label of a given text as the semantic difference of the labels may be blurred (e.g., abusive and hate) and often subjective. In this study, we proposed an analytical framework to study the annotation consistency in online hate and abusive content datasets. We applied our proposed framework to evaluate the consistency of the annotation in three popular datasets that are widely used in online hate speech and abusive behavior studies. We found that there is still a substantial amount of annotation inconsistency in the existing datasets, particularly when the labels are semantically similar.
Predicting Branch Visits and Credit Card Up-selling using Temporal Banking Data
Sep 07, 2016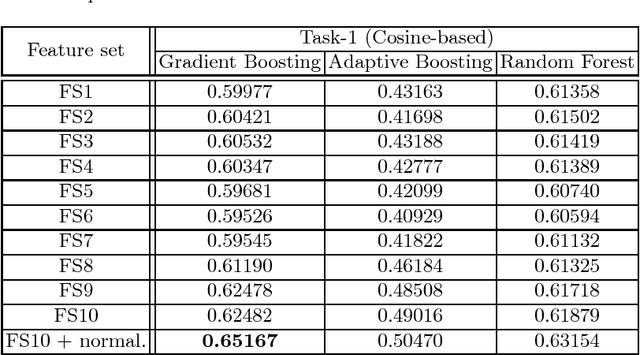
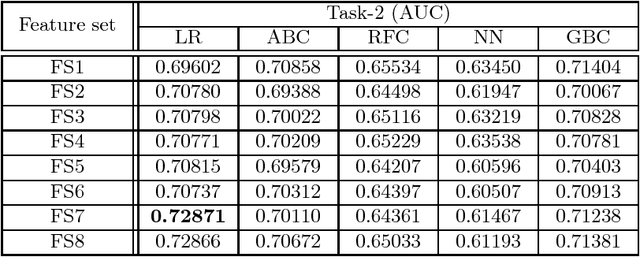
There is an abundance of temporal and non-temporal data in banking (and other industries), but such temporal activity data can not be used directly with classical machine learning models. In this work, we perform extensive feature extraction from the temporal user activity data in an attempt to predict user visits to different branches and credit card up-selling utilizing user information and the corresponding activity data, as part of \emph{ECML/PKDD Discovery Challenge 2016 on Bank Card Usage Analysis}. Our solution ranked \nth{4} for \emph{Task 1} and achieved an AUC of \textbf{$0.7056$} for \emph{Task 2} on public leaderboard.