 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-based Early Detection of Potato Sprouting Using Electrophysiological Signals
Jul 01, 2025Accurately predicting potato sprouting before the emergence of any visual signs is critical for effective storage management, as sprouting degrades both the commercial and nutritional value of tubers. Effective forecasting allows for the precise application of anti-sprouting chemicals (ASCs), minimizing waste and reducing costs. This need has become even more pressing following the ban on Isopropyl N-(3-chlorophenyl) carbamate (CIPC) or Chlorpropham due to health and environmental concerns, which has led to the adoption of significantly more expensive alternative ASCs. Existing approaches primarily rely on visual identification, which only detects sprouting after morphological changes have occurred, limiting their effectiveness for proactive management. A reliable early prediction method is therefore essential to enable timely intervention and improve the efficiency of post-harvest storage strategies, where early refers to detecting sprouting before any visible signs appear. In this work, we address the problem of early prediction of potato sprouting. To this end, we propose a novel machine learning (ML)-based approach that enables early prediction of potato sprouting using electrophysiological signals recorded from tubers using proprietary sensors. Our approach preprocesses the recorded signals, extracts relevant features from the wavelet domain, and trains supervised ML models for early sprouting detection. Additionally, we incorporate uncertainty quantification techniques to enhance predictions. Experimental results demonstrate promising performance in the early detection of potato sprouting by accurately predicting the exact day of sprouting for a subset of potatoes and while showing acceptable average error across all potatoes. Despite promising results, further refinements are necessary to minimize prediction errors, particularly in reducing the maximum observed deviations.
Differential Privacy for Anomaly Detection: Analyzing the Trade-off Between Privacy and Explainability
Apr 09, 2024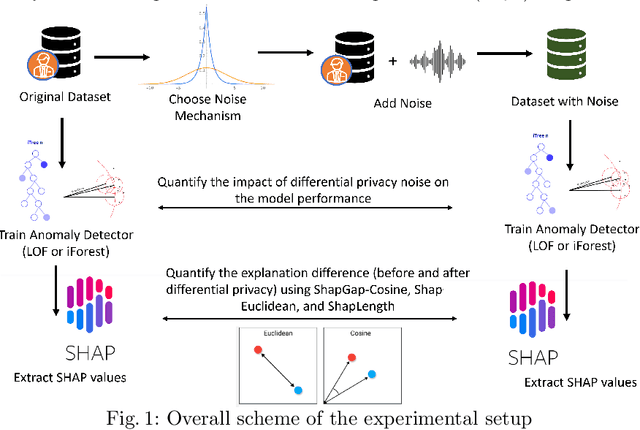
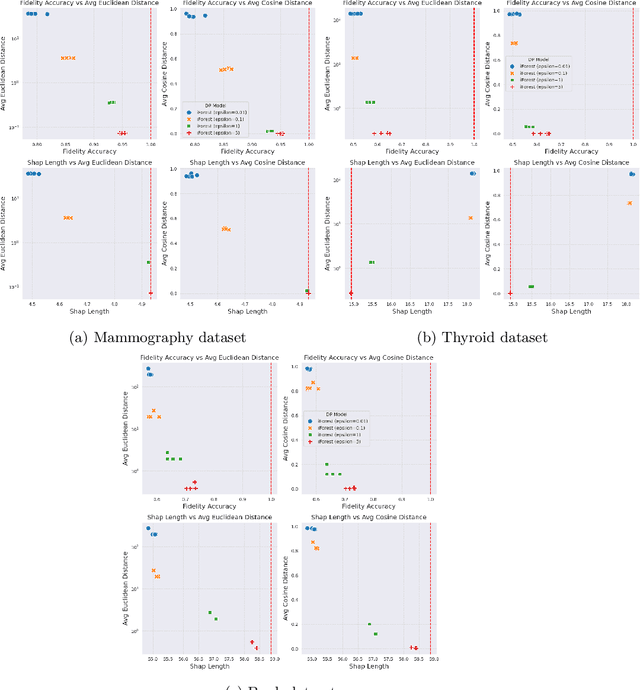
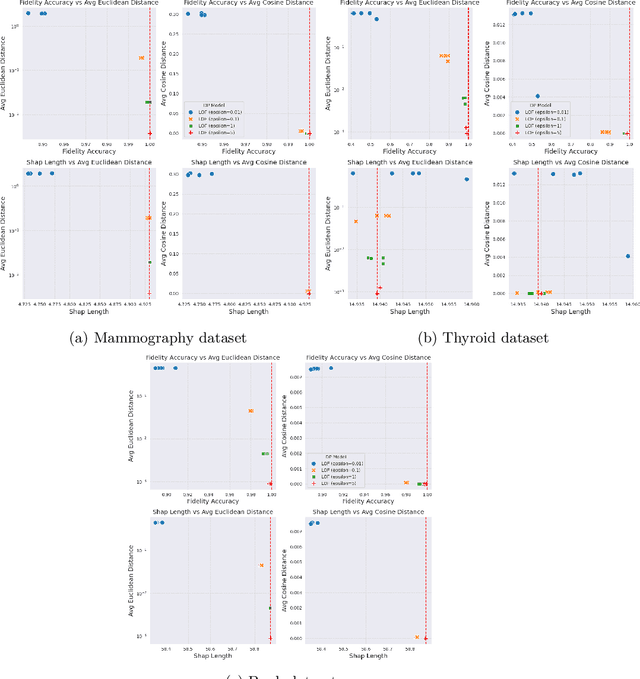
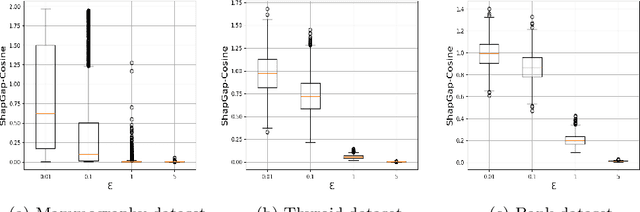
Anomaly detection (AD), also referred to as outlier detection, is a statistical process aimed at identifying observations within a dataset that significantly deviate from the expected pattern of the majority of the data. Such a process finds wide application in various fields, such as finance and healthcare. While the primary objective of AD is to yield high detection accuracy, the requirements of explainability and privacy are also paramount. The first ensures the transparency of the AD process, while the second guarantees that no sensitive information is leaked to untrusted parties. In this work, we exploit the trade-off of applying Explainable AI (XAI) through SHapley Additive exPlanations (SHAP) and differential privacy (DP). We perform AD with different models and on various datasets, and we thoroughly evaluate the cost of privacy in terms of decreased accuracy and explainability. Our results show that the enforcement of privacy through DP has a significant impact on detection accuracy and explainability, which depends on both the dataset and the considered AD model. We further show that the visual interpretation of explanations is also influenced by the choice of the AD algorithm.
Liquid Neural Network-based Adaptive Learning vs. Incremental Learning for Link Load Prediction amid Concept Drift due to Network Failures
Apr 08, 2024
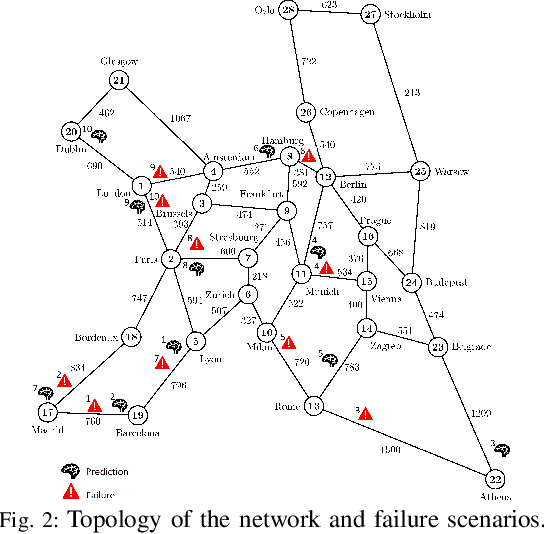
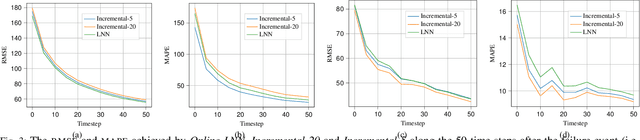
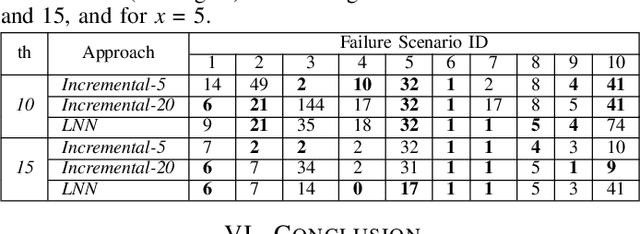
Adapting to concept drift is a challenging task in machine learning, which is usually tackled using incremental learning techniques that periodically re-fit a learning model leveraging newly available data. A primary limitation of these techniques is their reliance on substantial amounts of data for retraining. The necessity of acquiring fresh data introduces temporal delays prior to retraining, potentially rendering the models inaccurate if a sudden concept drift occurs in-between two consecutive retrainings. In communication networks, such issue emerges when performing traffic forecasting following a~failure event: post-failure re-routing may induce a drastic shift in distribution and pattern of traffic data, thus requiring a timely model adaptation. In this work, we address this challenge for the problem of traffic forecasting and propose an approach that exploits adaptive learning algorithms, namely, liquid neural networks, which are capable of self-adaptation to abrupt changes in data patterns without requiring any retraining. Through extensive simulations of failure scenarios, we compare the predictive performance of our proposed approach to that of a reference method based on incremental learning. Experimental results show that our proposed approach outperforms incremental learning-based methods in situations where the shifts in traffic patterns are drastic.
ChatGPT or Human? Detect and Explain. Explaining Decisions of Machine Learning Model for Detecting Short ChatGPT-generated Text
Jan 30, 2023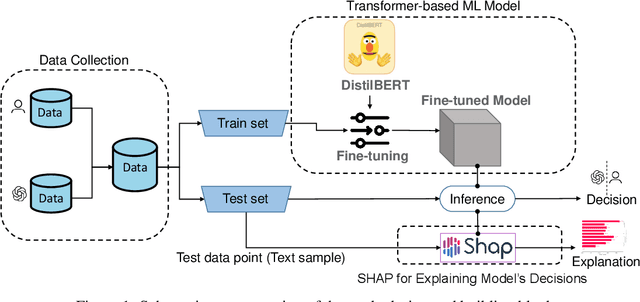
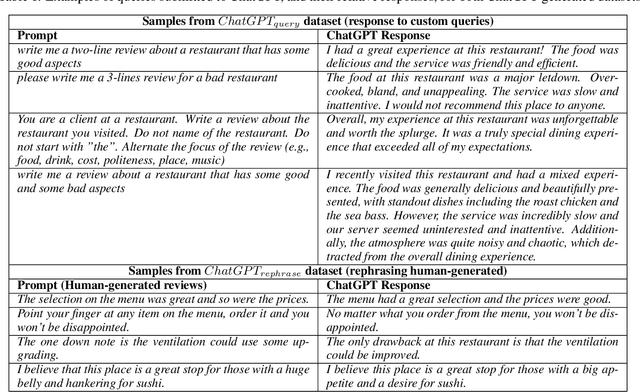
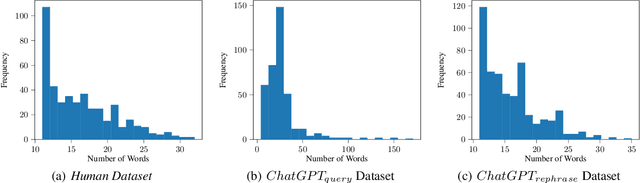
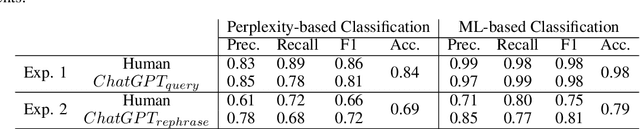
ChatGPT has the ability to generate grammatically flawless and seemingly-human replies to different types of questions from various domains. The number of its users and of its applications is growing at an unprecedented rate. Unfortunately, use and abuse come hand in hand. In this paper, we study whether a machine learning model can be effectively trained to accurately distinguish between original human and seemingly human (that is, ChatGPT-generated) text, especially when this text is short. Furthermore, we employ an explainable artificial intelligence framework to gain insight into the reasoning behind the model trained to differentiate between ChatGPT-generated and human-generated text. The goal is to analyze model's decisions and determine if any specific patterns or characteristics can be identified. Our study focuses on short online reviews, conducting two experiments comparing human-generated and ChatGPT-generated text. The first experiment involves ChatGPT text generated from custom queries, while the second experiment involves text generated by rephrasing original human-generated reviews. We fine-tune a Transformer-based model and use it to make predictions, which are then explained using SHAP. We compare our model with a perplexity score-based approach and find that disambiguation between human and ChatGPT-generated reviews is more challenging for the ML model when using rephrased text. However, our proposed approach still achieves an accuracy of 79%. Using explainability, we observe that ChatGPT's writing is polite, without specific details, using fancy and atypical vocabulary, impersonal, and typically it does not express feelings.