 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT or Human? Detect and Explain. Explaining Decisions of Machine Learning Model for Detecting Short ChatGPT-generated Text
Paper and Code
Jan 30, 2023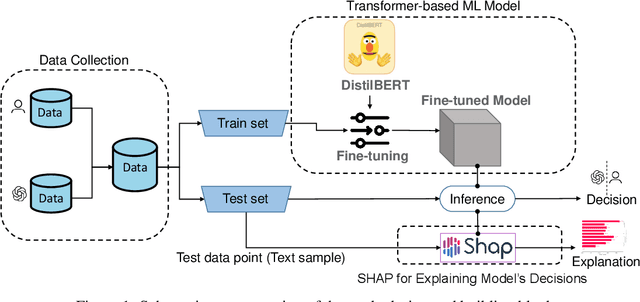
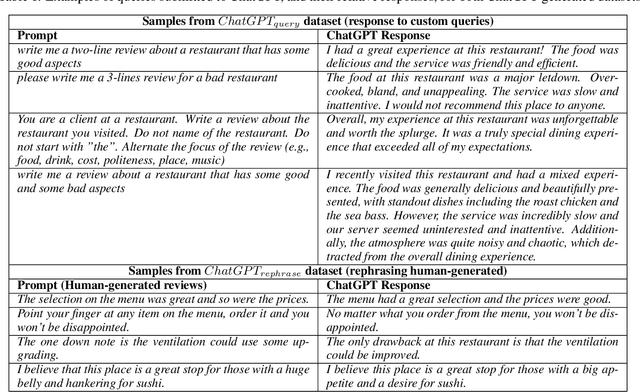
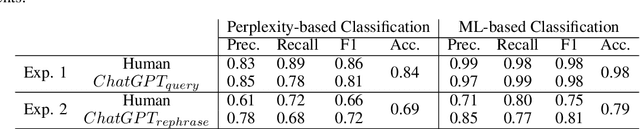
ChatGPT has the ability to generate grammatically flawless and seemingly-human replies to different types of questions from various domains. The number of its users and of its applications is growing at an unprecedented rate. Unfortunately, use and abuse come hand in hand. In this paper, we study whether a machine learning model can be effectively trained to accurately distinguish between original human and seemingly human (that is, ChatGPT-generated) text, especially when this text is short. Furthermore, we employ an explainable artificial intelligence framework to gain insight into the reasoning behind the model trained to differentiate between ChatGPT-generated and human-generated text. The goal is to analyze model's decisions and determine if any specific patterns or characteristics can be identified. Our study focuses on short online reviews, conducting two experiments comparing human-generated and ChatGPT-generated text. The first experiment involves ChatGPT text generated from custom queries, while the second experiment involves text generated by rephrasing original human-generated reviews. We fine-tune a Transformer-based model and use it to make predictions, which are then explained using SHAP. We compare our model with a perplexity score-based approach and find that disambiguation between human and ChatGPT-generated reviews is more challenging for the ML model when using rephrased text. However, our proposed approach still achieves an accuracy of 79%. Using explainability, we observe that ChatGPT's writing is polite, without specific details, using fancy and atypical vocabulary, impersonal, and typically it does not express feelings.