 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Performance Benchmarking of TinyML Models in Embedded Systems (PICO: Performance of Inference, CPU, and Operations)
Sep 05, 2025



This paper presents PICO-TINYML-BENCHMARK, a modular and platform-agnostic framework for benchmarking the real-time performance of TinyML models on resource-constrained embedded systems. Evaluating key metrics such as inference latency, CPU utilization, memory efficiency, and prediction stability, the framework provides insights into computational trade-offs and platform-specific optimizations. We benchmark three representative TinyML models -- Gesture Classification, Keyword Spotting, and MobileNet V2 -- on two widely adopted platforms, BeagleBone AI64 and Raspberry Pi 4, using real-world datasets. Results reveal critical trade-offs: the BeagleBone AI64 demonstrates consistent inference latency for AI-specific tasks, while the Raspberry Pi 4 excels in resource efficiency and cost-effectiveness. These findings offer actionable guidance for optimizing TinyML deployments, bridging the gap between theoretical advancements and practical applications in embedded systems.
Multimodal Event Detection: Current Approaches and Defining the New Playground through LLMs and VLMs
May 16, 2025In this paper, we study the challenges of detecting events on social media, where traditional unimodal systems struggle due to the rapid and multimodal nature of data dissemination. We employ a range of models, including unimodal ModernBERT and ConvNeXt-V2, multimodal fusion techniques, and advanced generative models like GPT-4o, and LLaVA. Additionally, we also study the effect of providing multimodal generative models (such as GPT-4o) with a single modality to assess their efficacy. Our results indicate that while multimodal approaches notably outperform unimodal counterparts, generative approaches despite having a large number of parameters, lag behind supervised methods in precision. Furthermore, we also found that they lag behind instruction-tuned models because of their inability to generate event classes correctly. During our error analysis, we discovered that common social media issues such as leet speak, text elongation, etc. are effectively handled by generative approaches but are hard to tackle using supervised approaches.
DG16M: A Large-Scale Dataset for Dual-Arm Grasping with Force-Optimized Grasps
Mar 11, 2025

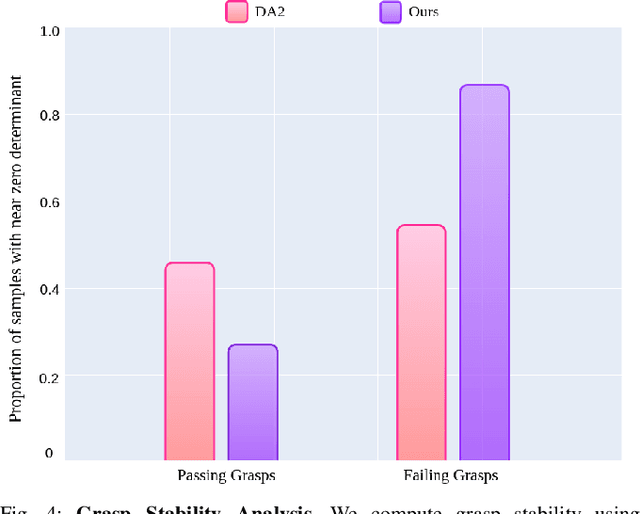

Dual-arm robotic grasping is crucial for handling large objects that require stable and coordinated manipulation. While single-arm grasping has been extensively studied, datasets tailored for dual-arm settings remain scarce. We introduce a large-scale dataset of 16 million dual-arm grasps, evaluated under improved force-closure constraints. Additionally, we develop a benchmark dataset containing 300 objects with approximately 30,000 grasps, evaluated in a physics simulation environment, providing a better grasp quality assessment for dual-arm grasp synthesis methods. Finally, we demonstrate the effectiveness of our dataset by training a Dual-Arm Grasp Classifier network that outperforms the state-of-the-art methods by 15\%, achieving higher grasp success rates and improved generalization across objects.
Agricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
SceneComplete: Open-World 3D Scene Completion in Complex Real World Environments for Robot Manipulation
Oct 31, 2024



Careful robot manipulation in every-day cluttered environments requires an accurate understanding of the 3D scene, in order to grasp and place objects stably and reliably and to avoid mistakenly colliding with other objects. In general, we must construct such a 3D interpretation of a complex scene based on limited input, such as a single RGB-D image. We describe SceneComplete, a system for constructing a complete, segmented, 3D model of a scene from a single view. It provides a novel pipeline for composing general-purpose pretrained perception modules (vision-language, segmentation, image-inpainting, image-to-3D, and pose-estimation) to obtain high-accuracy results. We demonstrate its accuracy and effectiveness with respect to ground-truth models in a large benchmark dataset and show that its accurate whole-object reconstruction enables robust grasp proposal generation, including for a dexterous hand.
DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance Control
Oct 25, 2024



Dual-arm manipulation is an area of growing interest in the robotics community. Enabling robots to perform tasks that require the coordinated use of two arms, is essential for complex manipulation tasks such as handling large objects, assembling components, and performing human-like interactions. However, achieving effective dual-arm manipulation is challenging due to the need for precise coordination, dynamic adaptability, and the ability to manage interaction forces between the arms and the objects being manipulated. We propose a novel pipeline that combines the advantages of policy learning based on environment feedback and gradient-based optimization to learn controller gains required for the control outputs. This allows the robotic system to dynamically modulate its impedance in response to task demands, ensuring stability and dexterity in dual-arm operations. We evaluate our pipeline on a trajectory-tracking task involving a variety of large, complex objects with different masses and geometries. The performance is then compared to three other established methods for controlling dual-arm robots, demonstrating superior results.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024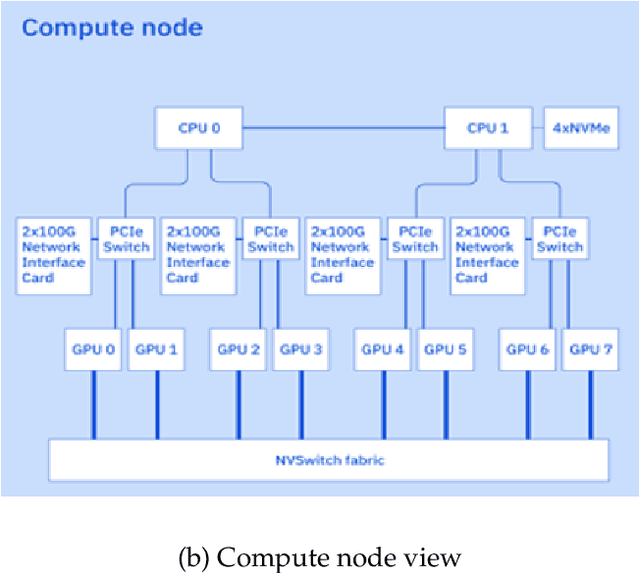
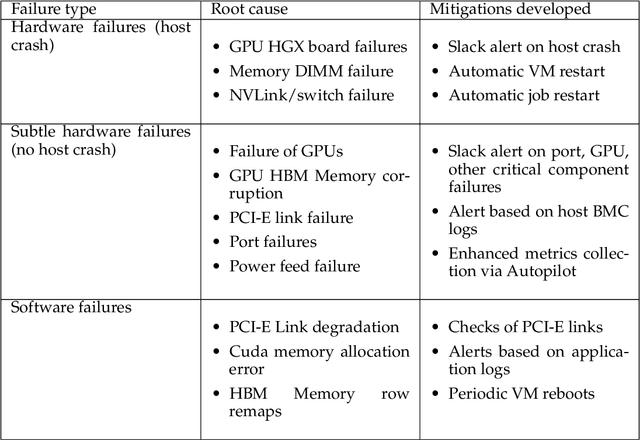
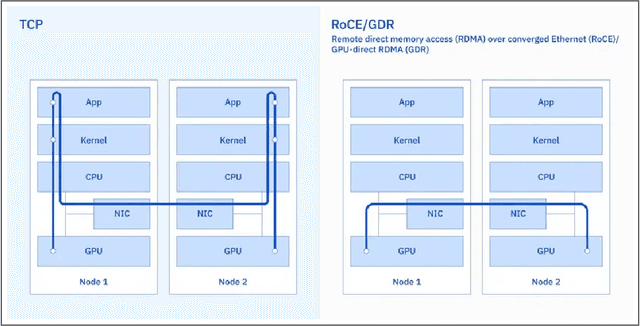
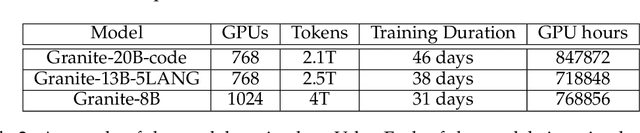
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
On Hardware-efficient Inference in Probabilistic Circuits
May 22, 2024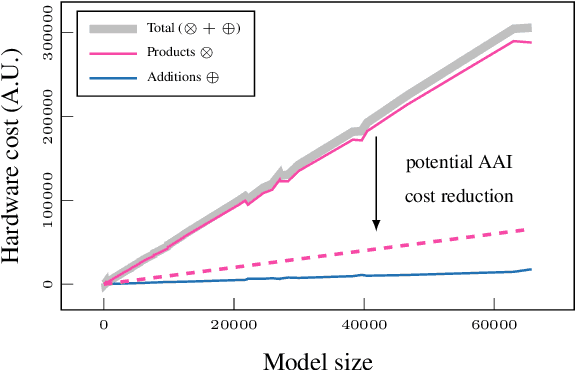
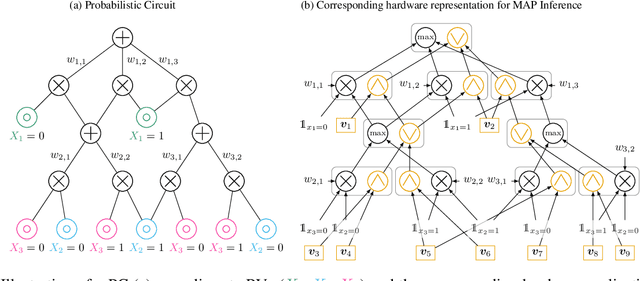

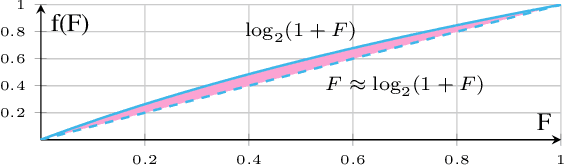
Probabilistic circuits (PCs) offer a promising avenue to perform embedded reasoning under uncertainty. They support efficient and exact computation of various probabilistic inference tasks by design. Hence, hardware-efficient computation of PCs is highly interesting for edge computing applications. As computations in PCs are based on arithmetic with probability values, they are typically performed in the log domain to avoid underflow. Unfortunately, performing the log operation on hardware is costly. Hence, prior work has focused on computations in the linear domain, resulting in high resolution and energy requirements. This work proposes the first dedicated approximate computing framework for PCs that allows for low-resolution logarithm computations. We leverage Addition As Int, resulting in linear PC computation with simple hardware elements. Further, we provide a theoretical approximation error analysis and present an error compensation mechanism. Empirically, our method obtains up to 357x and 649x energy reduction on custom hardware for evidence and MAP queries respectively with little or no computational error.
Enhancing Decision-Making in Optimization through LLM-Assisted Inference: A Neural Networks Perspective
May 12, 2024



This paper explores the seamless integration of Generative AI (GenAI) and Evolutionary Algorithms (EAs) within the domain of large-scale multi-objective optimization. Focusing on the transformative role of Large Language Models (LLMs), our study investigates the potential of LLM-Assisted Inference to automate and enhance decision-making processes. Specifically, we highlight its effectiveness in illuminating key decision variables in evolutionarily optimized solutions while articulating contextual trade-offs. Tailored to address the challenges inherent in inferring complex multi-objective optimization solutions at scale, our approach emphasizes the adaptive nature of LLMs, allowing them to provide nuanced explanations and align their language with diverse stakeholder expertise levels and domain preferences. Empirical studies underscore the practical applicability and impact of LLM-Assisted Inference in real-world decision-making scenarios.
Constrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm Manipulation
Apr 06, 2024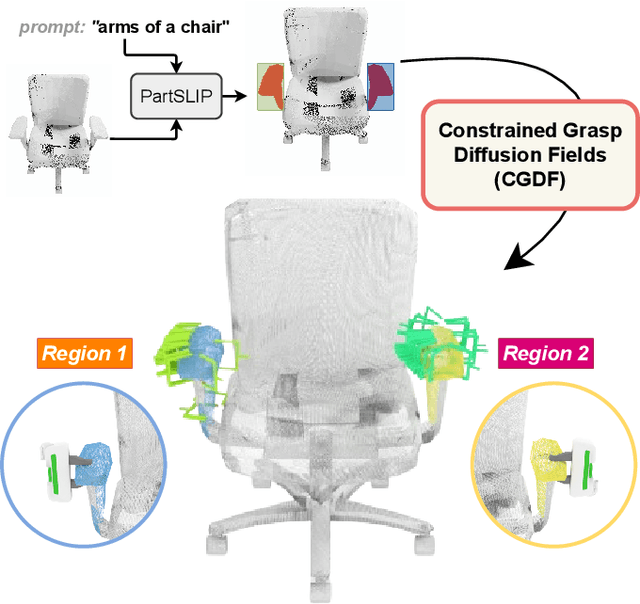
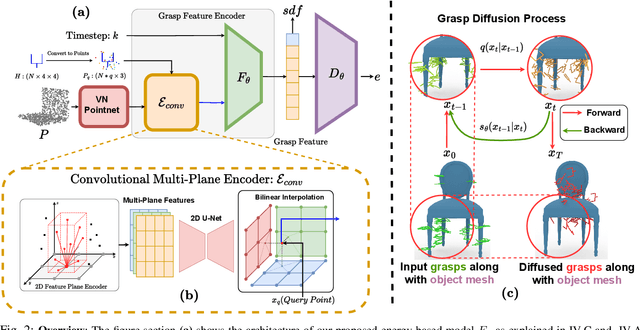
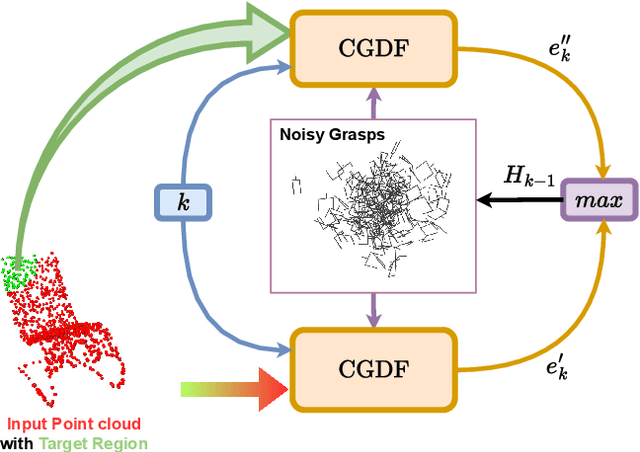
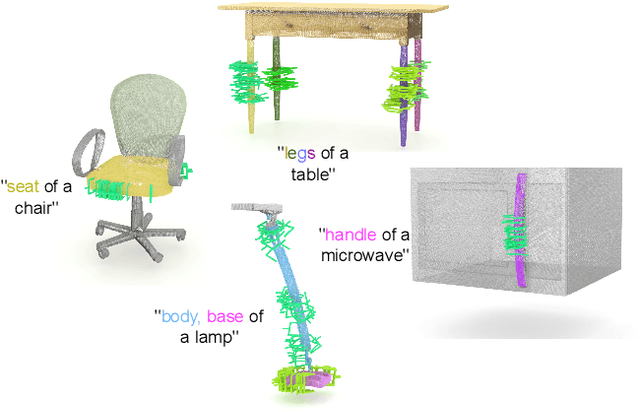
Efficiently generating grasp poses tailored to specific regions of an object is vital for various robotic manipulation tasks, especially in a dual-arm setup. This scenario presents a significant challenge due to the complex geometries involved, requiring a deep understanding of the local geometry to generate grasps efficiently on the specified constrained regions. Existing methods only explore settings involving table-top/small objects and require augmented datasets to train, limiting their performance on complex objects. We propose CGDF: Constrained Grasp Diffusion Fields, a diffusion-based grasp generative model that generalizes to objects with arbitrary geometries, as well as generates dense grasps on the target regions. CGDF uses a part-guided diffusion approach that enables it to get high sample efficiency in constrained grasping without explicitly training on massive constraint-augmented datasets. We provide qualitative and quantitative comparisons using analytical metrics and in simulation, in both unconstrained and constrained settings to show that our method can generalize to generate stable grasps on complex objects, especially useful for dual-arm manipulation settings, while existing methods struggle to do so.