 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
Analyzing the Efficacy of an LLM-Only Approach for Image-based Document Question Answering
Sep 25, 2023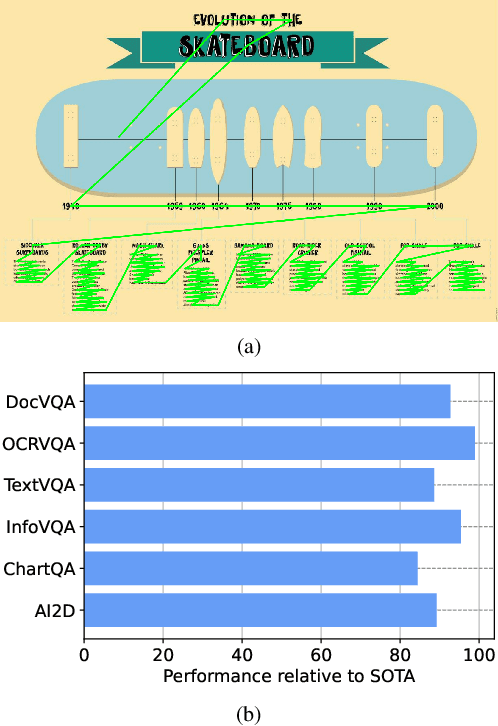
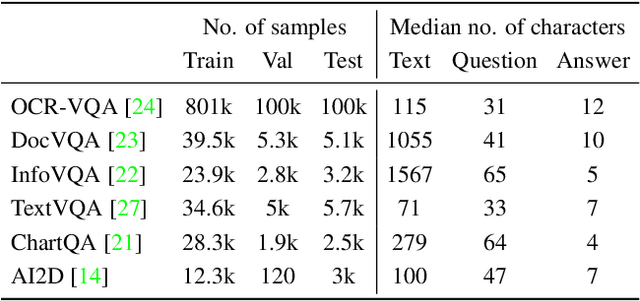
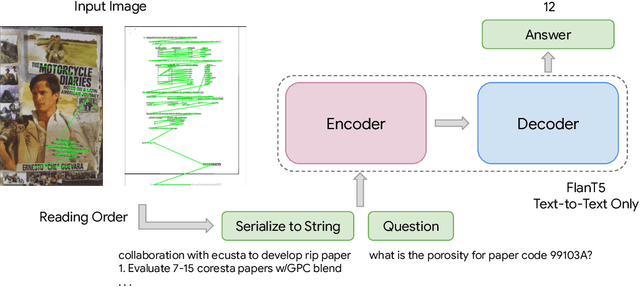

Recent document question answering models consist of two key components: the vision encoder, which captures layout and visual elements in images, and a Large Language Model (LLM) that helps contextualize questions to the image and supplements them with external world knowledge to generate accurate answers. However, the relative contributions of the vision encoder and the language model in these tasks remain unclear. This is especially interesting given the effectiveness of instruction-tuned LLMs, which exhibit remarkable adaptability to new tasks. To this end, we explore the following aspects in this work: (1) The efficacy of an LLM-only approach on document question answering tasks (2) strategies for serializing textual information within document images and feeding it directly to an instruction-tuned LLM, thus bypassing the need for an explicit vision encoder (3) thorough quantitative analysis on the feasibility of such an approach. Our comprehensive analysis encompasses six diverse benchmark datasets, utilizing LLMs of varying scales. Our findings reveal that a strategy exclusively reliant on the LLM yields results that are on par with or closely approach state-of-the-art performance across a range of datasets. We posit that this evaluation framework will serve as a guiding resource for selecting appropriate datasets for future research endeavors that emphasize the fundamental importance of layout and image content information.
Is it an i or an l: Test-time Adaptation of Text Line Recognition Models
Aug 29, 2023



Recognizing text lines from images is a challenging problem, especially for handwritten documents due to large variations in writing styles. While text line recognition models are generally trained on large corpora of real and synthetic data, such models can still make frequent mistakes if the handwriting is inscrutable or the image acquisition process adds corruptions, such as noise, blur, compression, etc. Writing style is generally quite consistent for an individual, which can be leveraged to correct mistakes made by such models. Motivated by this, we introduce the problem of adapting text line recognition models during test time. We focus on a challenging and realistic setting where, given only a single test image consisting of multiple text lines, the task is to adapt the model such that it performs better on the image, without any labels. We propose an iterative self-training approach that uses feedback from the language model to update the optical model, with confident self-labels in each iteration. The confidence measure is based on an augmentation mechanism that evaluates the divergence of the prediction of the model in a local region. We perform rigorous evaluation of our method on several benchmark datasets as well as their corrupted versions. Experimental results on multiple datasets spanning multiple scripts show that the proposed adaptation method offers an absolute improvement of up to 8% in character error rate with just a few iterations of self-training at test time.
Weakly supervised information extraction from inscrutable handwritten document images
Jun 12, 2023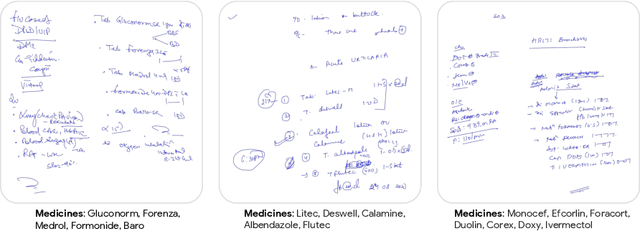

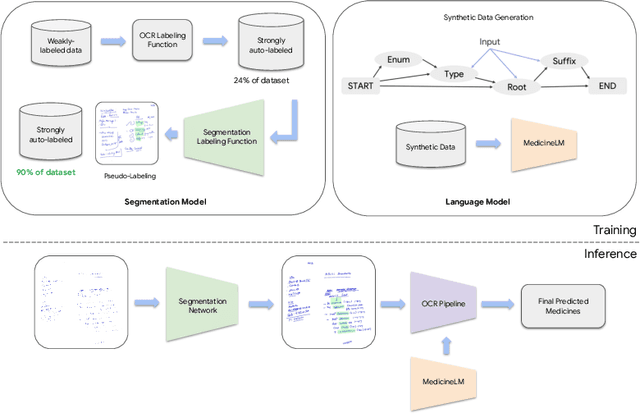
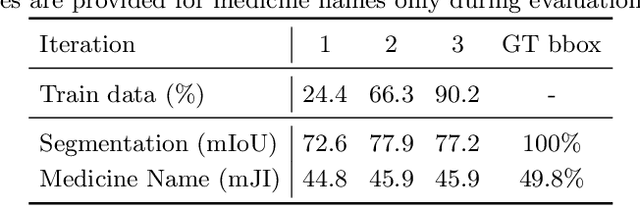
State-of-the-art information extraction methods are limited by OCR errors. They work well for printed text in form-like documents, but unstructured, handwritten documents still remain a challenge. Adapting existing models to domain-specific training data is quite expensive, because of two factors, 1) limited availability of the domain-specific documents (such as handwritten prescriptions, lab notes, etc.), and 2) annotations become even more challenging as one needs domain-specific knowledge to decode inscrutable handwritten document images. In this work, we focus on the complex problem of extracting medicine names from handwritten prescriptions using only weakly labeled data. The data consists of images along with the list of medicine names in it, but not their location in the image. We solve the problem by first identifying the regions of interest, i.e., medicine lines from just weak labels and then injecting a domain-specific medicine language model learned using only synthetically generated data. Compared to off-the-shelf state-of-the-art methods, our approach performs >2.5x better in medicine names extraction from prescriptions.
GAN-MPC: Training Model Predictive Controllers with Parameterized Cost Functions using Demonstrations from Non-identical Experts
Jun 07, 2023



Model predictive control (MPC) is a popular approach for trajectory optimization in practical robotics applications. MPC policies can optimize trajectory parameters under kinodynamic and safety constraints and provide guarantees on safety, optimality, generalizability, interpretability, and explainability. However, some behaviors are complex and it is difficult to hand-craft an MPC objective function. A special class of MPC policies called Learnable-MPC addresses this difficulty using imitation learning from expert demonstrations. However, they require the demonstrator and the imitator agents to be identical which is hard to satisfy in many real world applications of robotics. In this paper, we address the practical problem of training Learnable-MPC policies when the demonstrator and the imitator do not share the same dynamics and their state spaces may have a partial overlap. We propose a novel approach that uses a generative adversarial network (GAN) to minimize the Jensen-Shannon divergence between the state-trajectory distributions of the demonstrator and the imitator. We evaluate our approach on a variety of simulated robotics tasks of DeepMind Control suite and demonstrate the efficacy of our approach at learning the demonstrator's behavior without having to copy their actions.
A Contextual Bandit Approach for Learning to Plan in Environments with Probabilistic Goal Configurations
Nov 29, 2022



Object-goal navigation (Object-nav) entails searching, recognizing and navigating to a target object. Object-nav has been extensively studied by the Embodied-AI community, but most solutions are often restricted to considering static objects (e.g., television, fridge, etc.). We propose a modular framework for object-nav that is able to efficiently search indoor environments for not just static objects but also movable objects (e.g. fruits, glasses, phones, etc.) that frequently change their positions due to human intervention. Our contextual-bandit agent efficiently explores the environment by showing optimism in the face of uncertainty and learns a model of the likelihood of spotting different objects from each navigable location. The likelihoods are used as rewards in a weighted minimum latency solver to deduce a trajectory for the robot. We evaluate our algorithms in two simulated environments and a real-world setting, to demonstrate high sample efficiency and reliability.
Private and Efficient Meta-Learning with Low Rank and Sparse Decomposition
Oct 07, 2022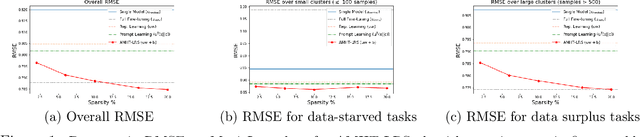
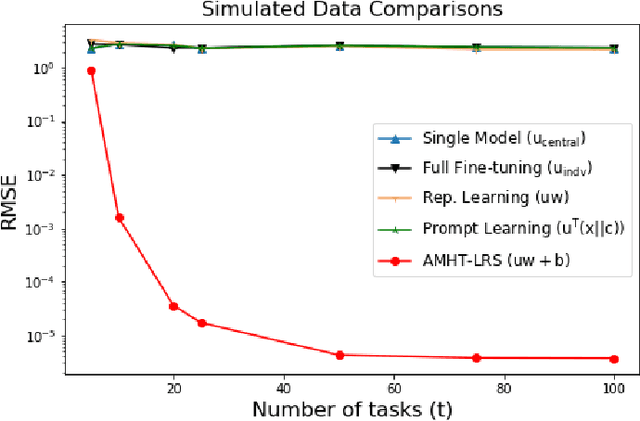
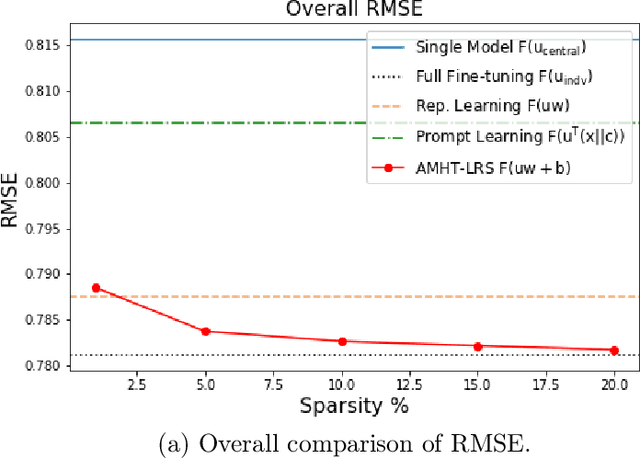
Meta-learning is critical for a variety of practical ML systems -- like personalized recommendations systems -- that are required to generalize to new tasks despite a small number of task-specific training points. Existing meta-learning techniques use two complementary approaches of either learning a low-dimensional representation of points for all tasks, or task-specific fine-tuning of a global model trained using all the tasks. In this work, we propose a novel meta-learning framework that combines both the techniques to enable handling of a large number of data-starved tasks. Our framework models network weights as a sum of low-rank and sparse matrices. This allows us to capture information from multiple domains together in the low-rank part while still allowing task specific personalization using the sparse part. We instantiate and study the framework in the linear setting, where the problem reduces to that of estimating the sum of a rank-$r$ and a $k$-column sparse matrix using a small number of linear measurements. We propose an alternating minimization method with hard thresholding -- AMHT-LRS -- to learn the low-rank and sparse part effectively and efficiently. For the realizable, Gaussian data setting, we show that AMHT-LRS indeed solves the problem efficiently with nearly optimal samples. We extend AMHT-LRS to ensure that it preserves privacy of each individual user in the dataset, while still ensuring strong generalization with nearly optimal number of samples. Finally, on multiple datasets, we demonstrate that the framework allows personalized models to obtain superior performance in the data-scarce regime.
Novel Class Discovery without Forgetting
Jul 21, 2022

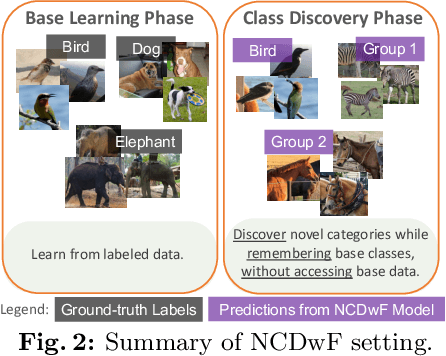
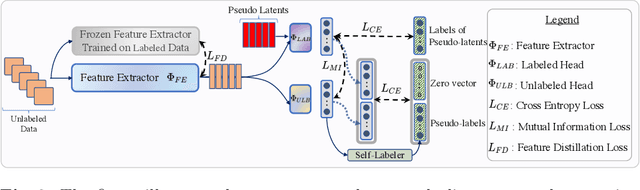
Humans possess an innate ability to identify and differentiate instances that they are not familiar with, by leveraging and adapting the knowledge that they have acquired so far. Importantly, they achieve this without deteriorating the performance on their earlier learning. Inspired by this, we identify and formulate a new, pragmatic problem setting of NCDwF: Novel Class Discovery without Forgetting, which tasks a machine learning model to incrementally discover novel categories of instances from unlabeled data, while maintaining its performance on the previously seen categories. We propose 1) a method to generate pseudo-latent representations which act as a proxy for (no longer available) labeled data, thereby alleviating forgetting, 2) a mutual-information based regularizer which enhances unsupervised discovery of novel classes, and 3) a simple Known Class Identifier which aids generalized inference when the testing data contains instances form both seen and unseen categories. We introduce experimental protocols based on CIFAR-10, CIFAR-100 and ImageNet-1000 to measure the trade-off between knowledge retention and novel class discovery. Our extensive evaluations reveal that existing models catastrophically forget previously seen categories while identifying novel categories, while our method is able to effectively balance between the competing objectives. We hope our work will attract further research into this newly identified pragmatic problem setting.
All Mistakes Are Not Equal: Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP)
Jun 17, 2022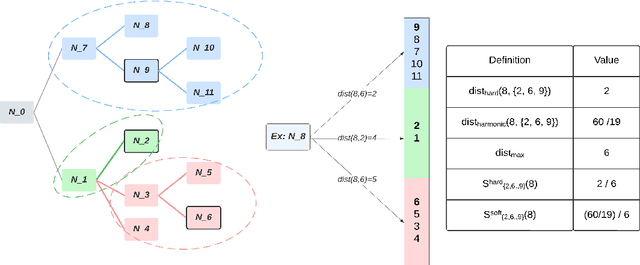
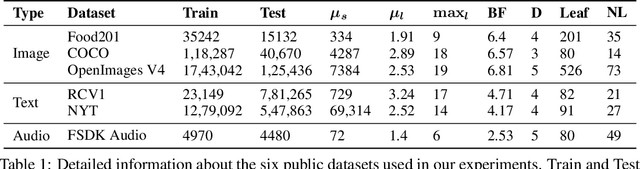
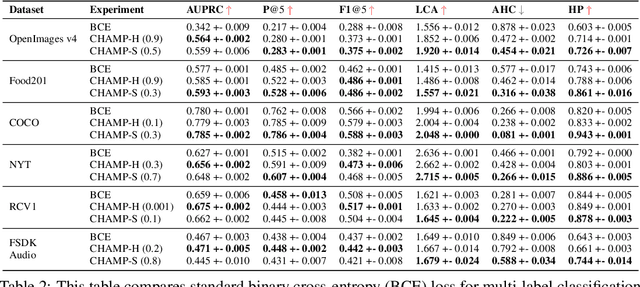
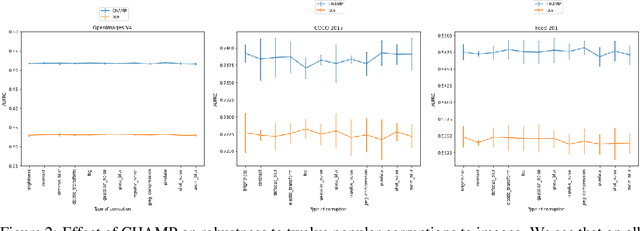
This paper considers the problem of Hierarchical Multi-Label Classification (HMC), where (i) several labels can be present for each example, and (ii) labels are related via a domain-specific hierarchy tree. Guided by the intuition that all mistakes are not equal, we present Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP), a framework that penalizes a misprediction depending on its severity as per the hierarchy tree. While there have been works that apply such an idea to single-label classification, to the best of our knowledge, there are limited such works for multilabel classification focusing on the severity of mistakes. The key reason is that there is no clear way of quantifying the severity of a misprediction a priori in the multilabel setting. In this work, we propose a simple but effective metric to quantify the severity of a mistake in HMC, naturally leading to CHAMP. Extensive experiments on six public HMC datasets across modalities (image, audio, and text) demonstrate that incorporating hierarchical information leads to substantial gains as CHAMP improves both AUPRC (2.6% median percentage improvement) and hierarchical metrics (2.85% median percentage improvement), over stand-alone hierarchical or multilabel classification methods. Compared to standard multilabel baselines, CHAMP provides improved AUPRC in both robustness (8.87% mean percentage improvement ) and less data regimes. Further, our method provides a framework to enhance existing multilabel classification algorithms with better mistakes (18.1% mean percentage increment).
Spacing Loss for Discovering Novel Categories
Apr 22, 2022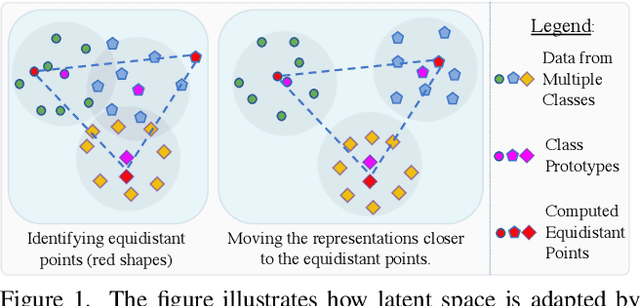
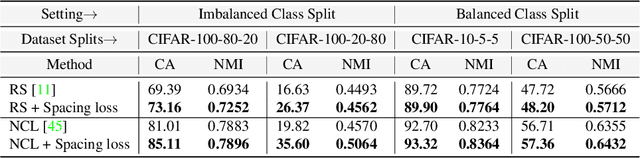
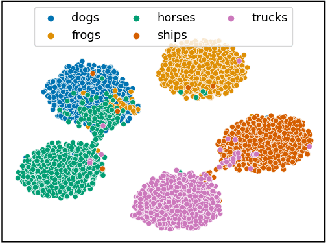
Novel Class Discovery (NCD) is a learning paradigm, where a machine learning model is tasked to semantically group instances from unlabeled data, by utilizing labeled instances from a disjoint set of classes. In this work, we first characterize existing NCD approaches into single-stage and two-stage methods based on whether they require access to labeled and unlabeled data together while discovering new classes. Next, we devise a simple yet powerful loss function that enforces separability in the latent space using cues from multi-dimensional scaling, which we refer to as Spacing Loss. Our proposed formulation can either operate as a standalone method or can be plugged into existing methods to enhance them. We validate the efficacy of Spacing Loss with thorough experimental evaluation across multiple settings on CIFAR-10 and CIFAR-100 datasets.