 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Efficacy of an LLM-Only Approach for Image-based Document Question Answering
Paper and Code
Sep 25, 2023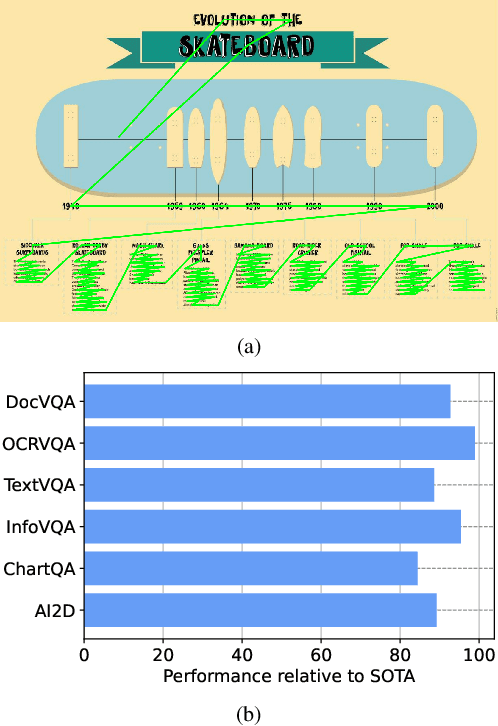
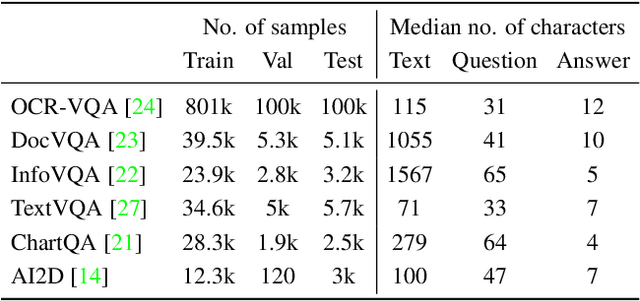
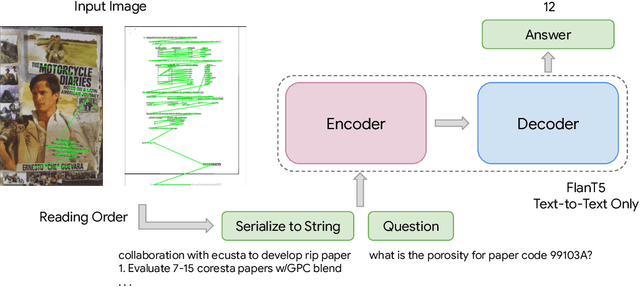

Recent document question answering models consist of two key components: the vision encoder, which captures layout and visual elements in images, and a Large Language Model (LLM) that helps contextualize questions to the image and supplements them with external world knowledge to generate accurate answers. However, the relative contributions of the vision encoder and the language model in these tasks remain unclear. This is especially interesting given the effectiveness of instruction-tuned LLMs, which exhibit remarkable adaptability to new tasks. To this end, we explore the following aspects in this work: (1) The efficacy of an LLM-only approach on document question answering tasks (2) strategies for serializing textual information within document images and feeding it directly to an instruction-tuned LLM, thus bypassing the need for an explicit vision encoder (3) thorough quantitative analysis on the feasibility of such an approach. Our comprehensive analysis encompasses six diverse benchmark datasets, utilizing LLMs of varying scales. Our findings reveal that a strategy exclusively reliant on the LLM yields results that are on par with or closely approach state-of-the-art performance across a range of datasets. We posit that this evaluation framework will serve as a guiding resource for selecting appropriate datasets for future research endeavors that emphasize the fundamental importance of layout and image content information.