 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Retrieval in Sponsored Search by Leveraging Query Context Signals
Jul 19, 2024



Accurately retrieving relevant bid keywords for user queries is critical in Sponsored Search but remains challenging, particularly for short, ambiguous queries. Existing dense and generative retrieval models often fail to capture nuanced user intent in these cases. To address this, we propose an approach to enhance query understanding by augmenting queries with rich contextual signals derived from web search results and large language models, stored in an online cache. Specifically, we use web search titles and snippets to ground queries in real-world information and utilize GPT-4 to generate query rewrites and explanations that clarify user intent. These signals are efficiently integrated through a Fusion-in-Decoder based Unity architecture, enabling both dense and generative retrieval with serving costs on par with traditional context-free models. To address scenarios where context is unavailable in the cache, we introduce context glancing, a curriculum learning strategy that improves model robustness and performance even without contextual signals during inference. Extensive offline experiments demonstrate that our context-aware approach substantially outperforms context-free models. Furthermore, online A/B testing on a prominent search engine across 160+ countries shows significant improvements in user engagement and revenue.
Analyzing the Efficacy of an LLM-Only Approach for Image-based Document Question Answering
Sep 25, 2023
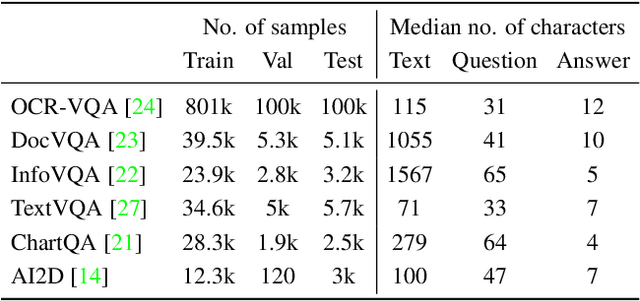
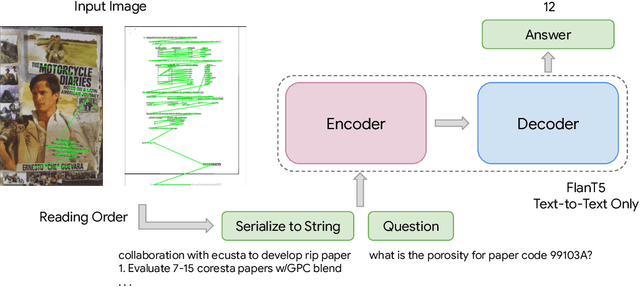

Recent document question answering models consist of two key components: the vision encoder, which captures layout and visual elements in images, and a Large Language Model (LLM) that helps contextualize questions to the image and supplements them with external world knowledge to generate accurate answers. However, the relative contributions of the vision encoder and the language model in these tasks remain unclear. This is especially interesting given the effectiveness of instruction-tuned LLMs, which exhibit remarkable adaptability to new tasks. To this end, we explore the following aspects in this work: (1) The efficacy of an LLM-only approach on document question answering tasks (2) strategies for serializing textual information within document images and feeding it directly to an instruction-tuned LLM, thus bypassing the need for an explicit vision encoder (3) thorough quantitative analysis on the feasibility of such an approach. Our comprehensive analysis encompasses six diverse benchmark datasets, utilizing LLMs of varying scales. Our findings reveal that a strategy exclusively reliant on the LLM yields results that are on par with or closely approach state-of-the-art performance across a range of datasets. We posit that this evaluation framework will serve as a guiding resource for selecting appropriate datasets for future research endeavors that emphasize the fundamental importance of layout and image content information.
Is it an i or an l: Test-time Adaptation of Text Line Recognition Models
Aug 29, 2023



Recognizing text lines from images is a challenging problem, especially for handwritten documents due to large variations in writing styles. While text line recognition models are generally trained on large corpora of real and synthetic data, such models can still make frequent mistakes if the handwriting is inscrutable or the image acquisition process adds corruptions, such as noise, blur, compression, etc. Writing style is generally quite consistent for an individual, which can be leveraged to correct mistakes made by such models. Motivated by this, we introduce the problem of adapting text line recognition models during test time. We focus on a challenging and realistic setting where, given only a single test image consisting of multiple text lines, the task is to adapt the model such that it performs better on the image, without any labels. We propose an iterative self-training approach that uses feedback from the language model to update the optical model, with confident self-labels in each iteration. The confidence measure is based on an augmentation mechanism that evaluates the divergence of the prediction of the model in a local region. We perform rigorous evaluation of our method on several benchmark datasets as well as their corrupted versions. Experimental results on multiple datasets spanning multiple scripts show that the proposed adaptation method offers an absolute improvement of up to 8% in character error rate with just a few iterations of self-training at test time.
Weakly supervised information extraction from inscrutable handwritten document images
Jun 12, 2023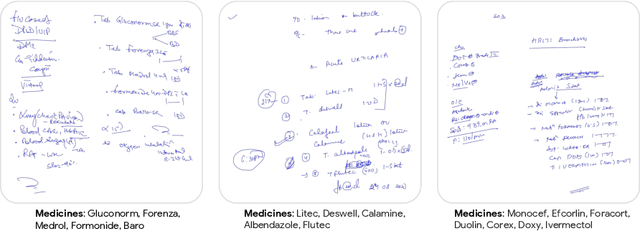

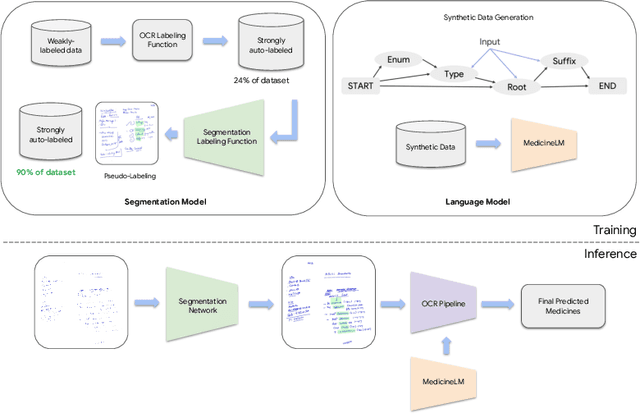
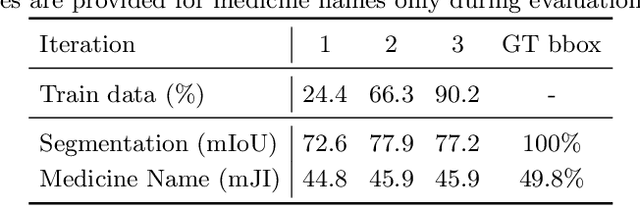
State-of-the-art information extraction methods are limited by OCR errors. They work well for printed text in form-like documents, but unstructured, handwritten documents still remain a challenge. Adapting existing models to domain-specific training data is quite expensive, because of two factors, 1) limited availability of the domain-specific documents (such as handwritten prescriptions, lab notes, etc.), and 2) annotations become even more challenging as one needs domain-specific knowledge to decode inscrutable handwritten document images. In this work, we focus on the complex problem of extracting medicine names from handwritten prescriptions using only weakly labeled data. The data consists of images along with the list of medicine names in it, but not their location in the image. We solve the problem by first identifying the regions of interest, i.e., medicine lines from just weak labels and then injecting a domain-specific medicine language model learned using only synthetically generated data. Compared to off-the-shelf state-of-the-art methods, our approach performs >2.5x better in medicine names extraction from prescriptions.
A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
Mar 30, 2023



There has been a recent explosion of computer vision models which perform many tasks and are composed of an image encoder (usually a ViT) and an autoregressive decoder (usually a Transformer). However, most of this work simply presents one system and its results, leaving many questions regarding design decisions and trade-offs of such systems unanswered. In this work, we aim to provide such answers. We take a close look at autoregressive decoders for multi-task learning in multimodal computer vision, including classification, captioning, visual question answering, and optical character recognition. Through extensive systematic experiments, we study the effects of task and data mixture, training and regularization hyperparameters, conditioning type and specificity, modality combination, and more. Importantly, we compare these to well-tuned single-task baselines to highlight the cost incurred by multi-tasking. A key finding is that a small decoder learned on top of a frozen pretrained encoder works surprisingly well. We call this setup locked-image tuning with decoder (LiT-decoder). It can be seen as teaching a decoder to interact with a pretrained vision model via natural language.
Private and Efficient Meta-Learning with Low Rank and Sparse Decomposition
Oct 07, 2022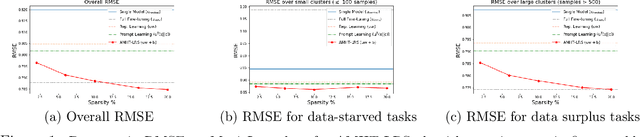
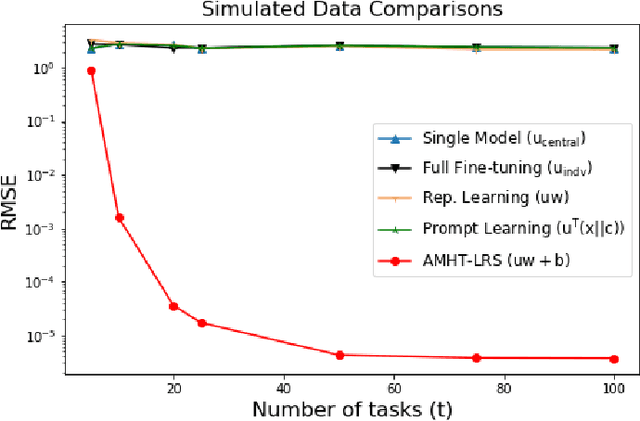
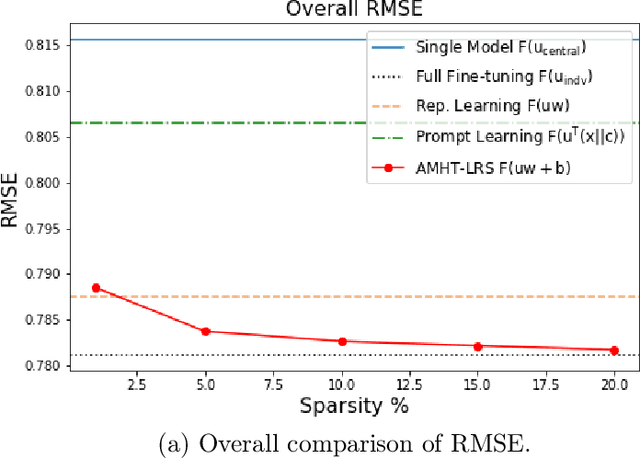
Meta-learning is critical for a variety of practical ML systems -- like personalized recommendations systems -- that are required to generalize to new tasks despite a small number of task-specific training points. Existing meta-learning techniques use two complementary approaches of either learning a low-dimensional representation of points for all tasks, or task-specific fine-tuning of a global model trained using all the tasks. In this work, we propose a novel meta-learning framework that combines both the techniques to enable handling of a large number of data-starved tasks. Our framework models network weights as a sum of low-rank and sparse matrices. This allows us to capture information from multiple domains together in the low-rank part while still allowing task specific personalization using the sparse part. We instantiate and study the framework in the linear setting, where the problem reduces to that of estimating the sum of a rank-$r$ and a $k$-column sparse matrix using a small number of linear measurements. We propose an alternating minimization method with hard thresholding -- AMHT-LRS -- to learn the low-rank and sparse part effectively and efficiently. For the realizable, Gaussian data setting, we show that AMHT-LRS indeed solves the problem efficiently with nearly optimal samples. We extend AMHT-LRS to ensure that it preserves privacy of each individual user in the dataset, while still ensuring strong generalization with nearly optimal number of samples. Finally, on multiple datasets, we demonstrate that the framework allows personalized models to obtain superior performance in the data-scarce regime.
Node-Level Differentially Private Graph Neural Networks
Dec 06, 2021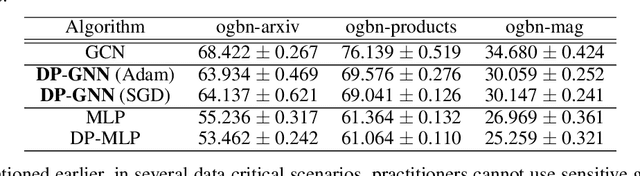
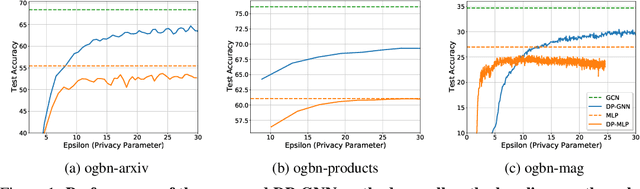
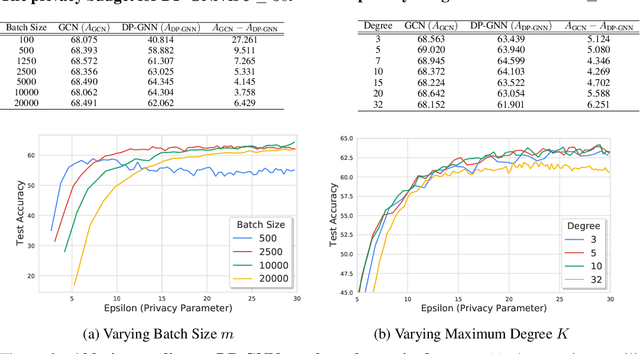
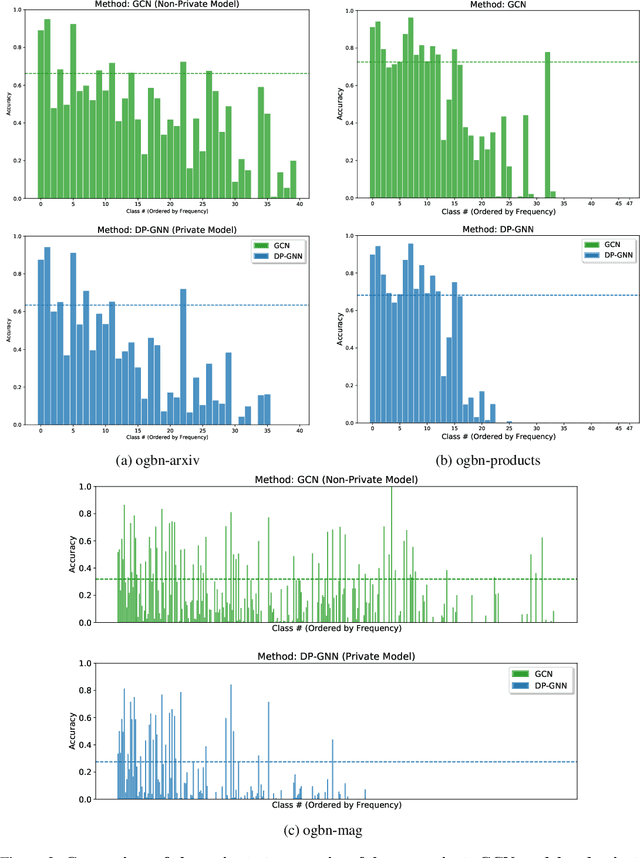
Graph Neural Networks (GNNs) are a popular technique for modelling graph-structured data that compute node-level representations via aggregation of information from the local neighborhood of each node. However, this aggregation implies increased risk of revealing sensitive information, as a node can participate in the inference for multiple nodes. This implies that standard privacy preserving machine learning techniques, such as differentially private stochastic gradient descent (DP-SGD) - which are designed for situations where each data point participates in the inference for one point only - either do not apply, or lead to inaccurate solutions. In this work, we formally define the problem of learning 1-layer GNNs with node-level privacy, and provide an algorithmic solution with a strong differential privacy guarantee. Even though each node can be involved in the inference for multiple nodes, by employing a careful sensitivity analysis anda non-trivial extension of the privacy-by-amplification technique, our method is able to provide accurate solutions with solid privacy parameters. Empirical evaluation on standard benchmarks demonstrates that our method is indeed able to learn accurate privacy preserving GNNs, while still outperforming standard non-private methods that completely ignore graph information.
Block-Value Symmetries in Probabilistic Graphical Models
Jul 08, 2018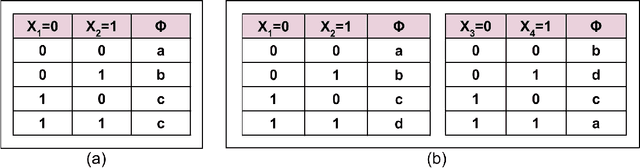

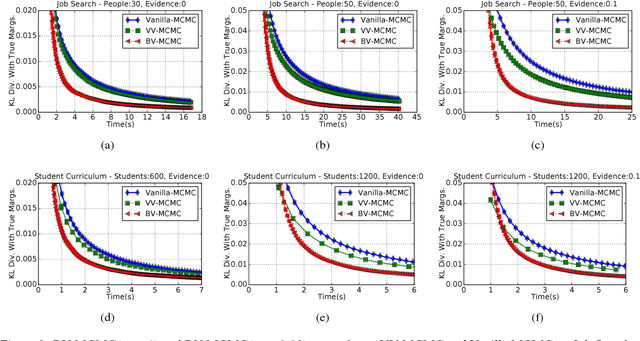
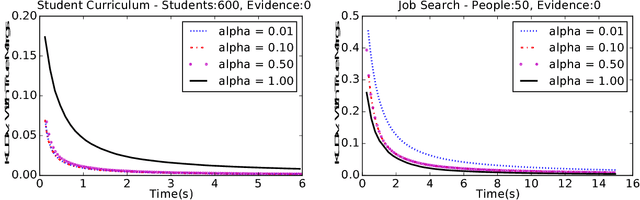
One popular way for lifted inference in probabilistic graphical models is to first merge symmetric states into a single cluster (orbit) and then use these for downstream inference, via variations of orbital MCMC [Niepert, 2012]. These orbits are represented compactly using permutations over variables, and variable-value (VV) pairs, but they can miss several state symmetries in a domain. We define the notion of permutations over block-value (BV) pairs, where a block is a set of variables. BV strictly generalizes VV symmetries, and can compute many more symmetries for increasing block sizes. To operationalize use of BV permutations in lifted inference, we describe 1) an algorithm to compute BV permutations given a block partition of the variables, 2) BV-MCMC, an extension of orbital MCMC that can sample from BV orbits, and 3) a heuristic to suggest good block partitions. Our experiments show that BV-MCMC can mix much faster compared to vanilla MCMC and orbital MCMC.
A Survey of Distant Supervision Methods using PGMs
May 10, 2017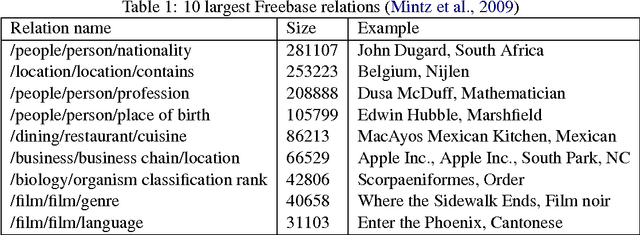
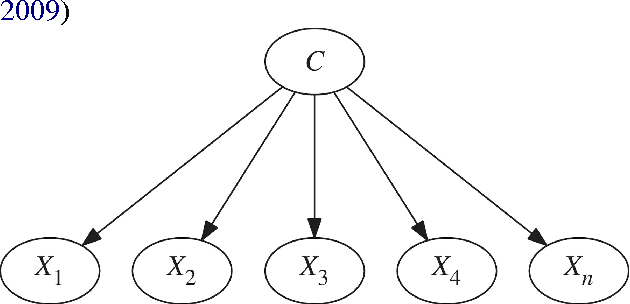
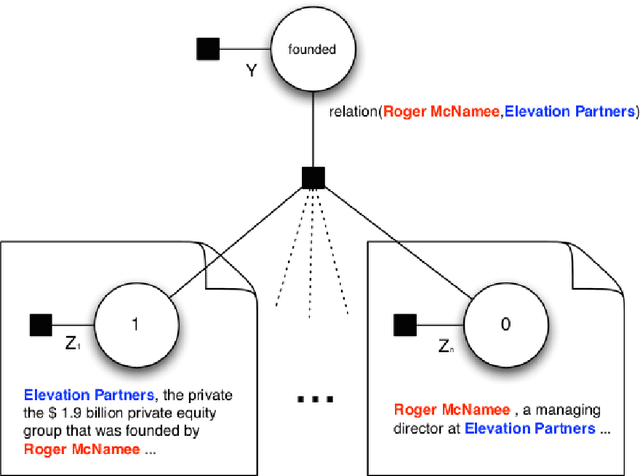
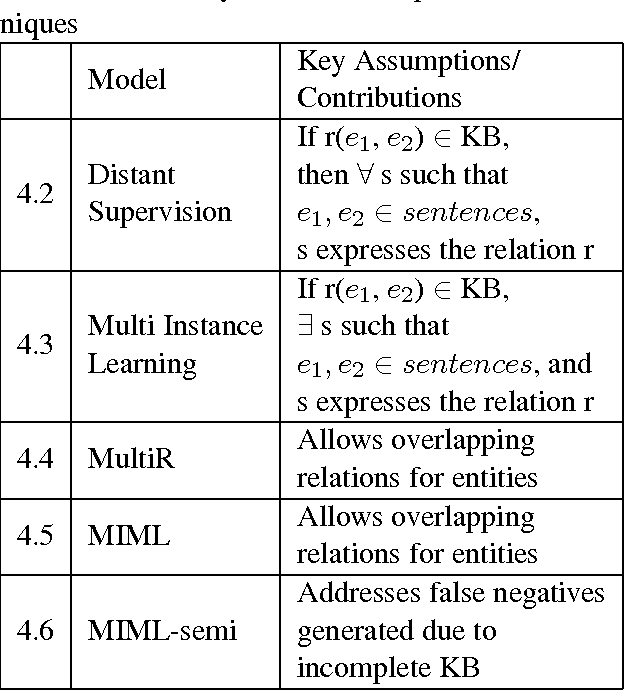
Relation Extraction refers to the task of populating a database with tuples of the form $r(e_1, e_2)$, where $r$ is a relation and $e_1$, $e_2$ are entities. Distant supervision is one such technique which tries to automatically generate training examples based on an existing KB such as Freebase. This paper is a survey of some of the techniques in distant supervision which primarily rely on Probabilistic Graphical Models (PGMs).
Topic Modeling Using Distributed Word Embeddings
Mar 15, 2016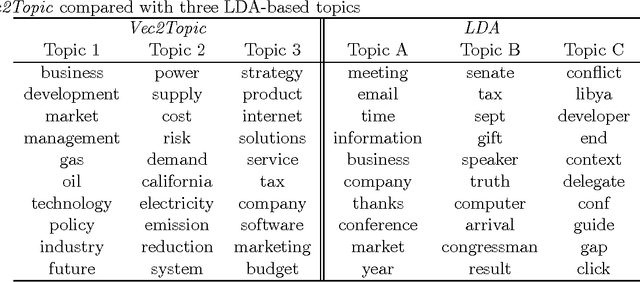

We propose a new algorithm for topic modeling, Vec2Topic, that identifies the main topics in a corpus using semantic information captured via high-dimensional distributed word embeddings. Our technique is unsupervised and generates a list of topics ranked with respect to importance. We find that it works better than existing topic modeling techniques such as Latent Dirichlet Allocation for identifying key topics in user-generated content, such as emails, chats, etc., where topics are diffused across the corpus. We also find that Vec2Topic works equally well for non-user generated content, such as papers, reports, etc., and for small corpora such as a single-document.