 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Jet: A Modern Transformer-Based Normalizing Flow
Dec 19, 2024



In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute log-likelihood of the input data, fast generation and simple overall structure. Normalizing flows remained a topic of active research but later fell out of favor, as visual quality of the samples was not competitive with other model classes, such as GANs, VQ-VAE-based approaches or diffusion models. In this paper we revisit the design of the coupling-based normalizing flow models by carefully ablating prior design choices and using computational blocks based on the Vision Transformer architecture, not convolutional neural networks. As a result, we achieve state-of-the-art quantitative and qualitative performance with a much simpler architecture. While the overall visual quality is still behind the current state-of-the-art models, we argue that strong normalizing flow models can help advancing research frontier by serving as building components of more powerful generative models.
PaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
JetFormer: An Autoregressive Generative Model of Raw Images and Text
Nov 29, 2024



Removing modeling constraints and unifying architectures across domains has been a key driver of the recent progress in training large multimodal models. However, most of these models still rely on many separately trained components such as modality-specific encoders and decoders. In this work, we further streamline joint generative modeling of images and text. We propose an autoregressive decoder-only transformer - JetFormer - which is trained to directly maximize the likelihood of raw data, without relying on any separately pretrained components, and can understand and generate both text and images. Specifically, we leverage a normalizing flow model to obtain a soft-token image representation that is jointly trained with an autoregressive multimodal transformer. The normalizing flow model serves as both an image encoder for perception tasks and an image decoder for image generation tasks during inference. JetFormer achieves text-to-image generation quality competitive with recent VQ-VAE- and VAE-based baselines. These baselines rely on pretrained image autoencoders, which are trained with a complex mixture of losses, including perceptual ones. At the same time, JetFormer demonstrates robust image understanding capabilities. To the best of our knowledge, JetFormer is the first model that is capable of generating high-fidelity images and producing strong log-likelihood bounds.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024



Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
Mar 30, 2023



There has been a recent explosion of computer vision models which perform many tasks and are composed of an image encoder (usually a ViT) and an autoregressive decoder (usually a Transformer). However, most of this work simply presents one system and its results, leaving many questions regarding design decisions and trade-offs of such systems unanswered. In this work, we aim to provide such answers. We take a close look at autoregressive decoders for multi-task learning in multimodal computer vision, including classification, captioning, visual question answering, and optical character recognition. Through extensive systematic experiments, we study the effects of task and data mixture, training and regularization hyperparameters, conditioning type and specificity, modality combination, and more. Importantly, we compare these to well-tuned single-task baselines to highlight the cost incurred by multi-tasking. A key finding is that a small decoder learned on top of a frozen pretrained encoder works surprisingly well. We call this setup locked-image tuning with decoder (LiT-decoder). It can be seen as teaching a decoder to interact with a pretrained vision model via natural language.
Tuning computer vision models with task rewards
Feb 16, 2023
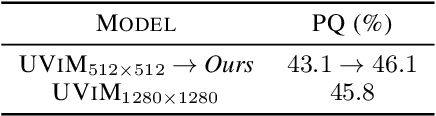
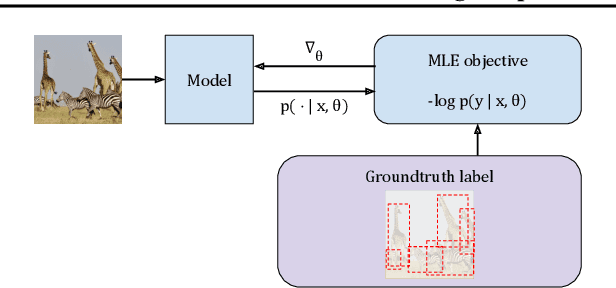

Misalignment between model predictions and intended usage can be detrimental for the deployment of computer vision models. The issue is exacerbated when the task involves complex structured outputs, as it becomes harder to design procedures which address this misalignment. In natural language processing, this is often addressed using reinforcement learning techniques that align models with a task reward. We adopt this approach and show its surprising effectiveness across multiple computer vision tasks, such as object detection, panoptic segmentation, colorization and image captioning. We believe this approach has the potential to be widely useful for better aligning models with a diverse range of computer vision tasks.
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
May 27, 2022

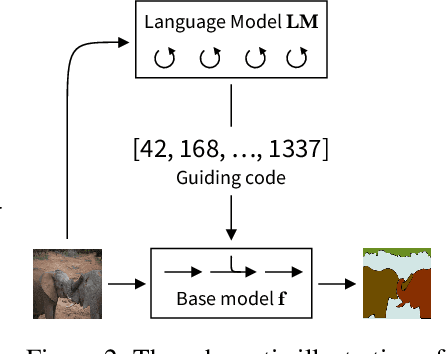

We introduce UViM, a unified approach capable of modeling a wide range of computer vision tasks. In contrast to previous models, UViM has the same functional form for all tasks; it requires no task-specific modifications which require extensive human expertise. The approach involves two components: (I) a base model (feed-forward) which is trained to directly predict raw vision outputs, guided by a learned discrete code and (II) a language model (autoregressive) that is trained to generate the guiding code. These components complement each other: the language model is well-suited to modeling structured interdependent data, while the base model is efficient at dealing with high-dimensional outputs. We demonstrate the effectiveness of UViM on three diverse and challenging vision tasks: panoptic segmentation, depth prediction and image colorization, where we achieve competitive and near state-of-the-art results. Our experimental results suggest that UViM is a promising candidate for a unified modeling approach in computer vision.
Learning to Merge Tokens in Vision Transformers
Feb 24, 2022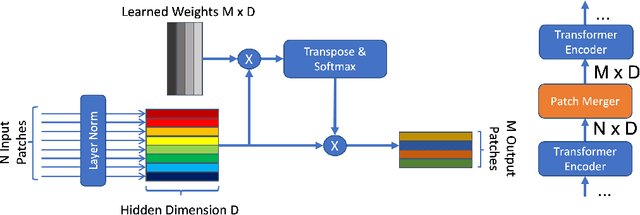
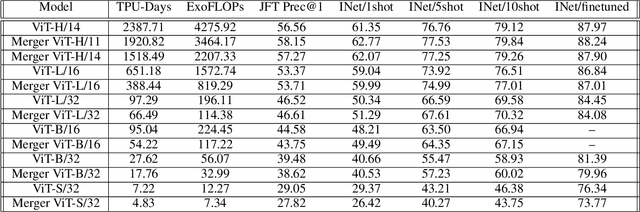
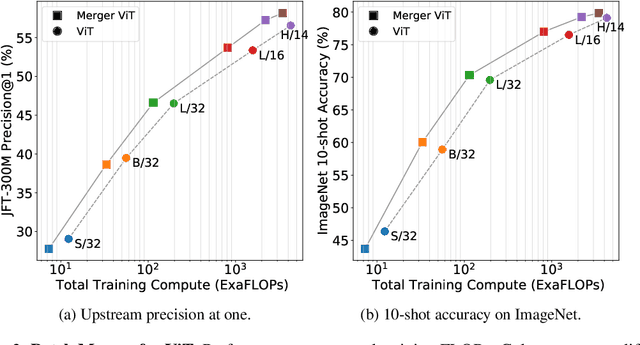
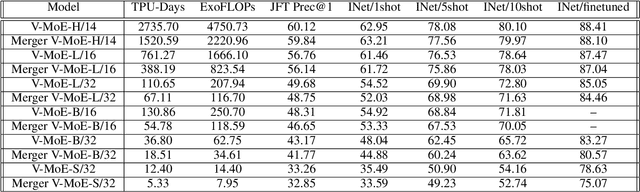
Transformers are widely applied to solve natural language understanding and computer vision tasks. While scaling up these architectures leads to improved performance, it often comes at the expense of much higher computational costs. In order for large-scale models to remain practical in real-world systems, there is a need for reducing their computational overhead. In this work, we present the PatchMerger, a simple module that reduces the number of patches or tokens the network has to process by merging them between two consecutive intermediate layers. We show that the PatchMerger achieves a significant speedup across various model sizes while matching the original performance both upstream and downstream after fine-tuning.