 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025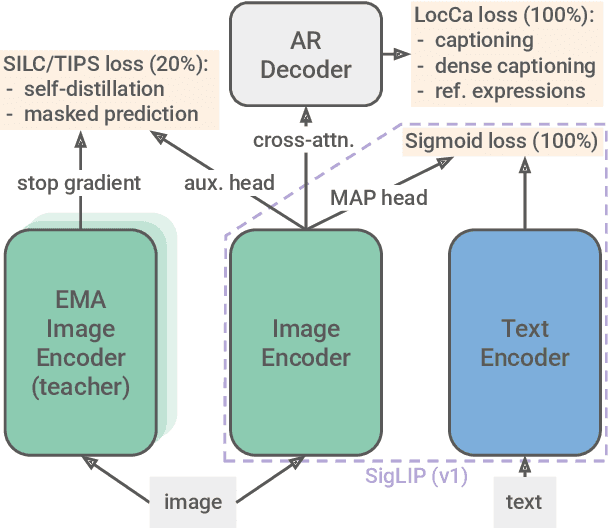
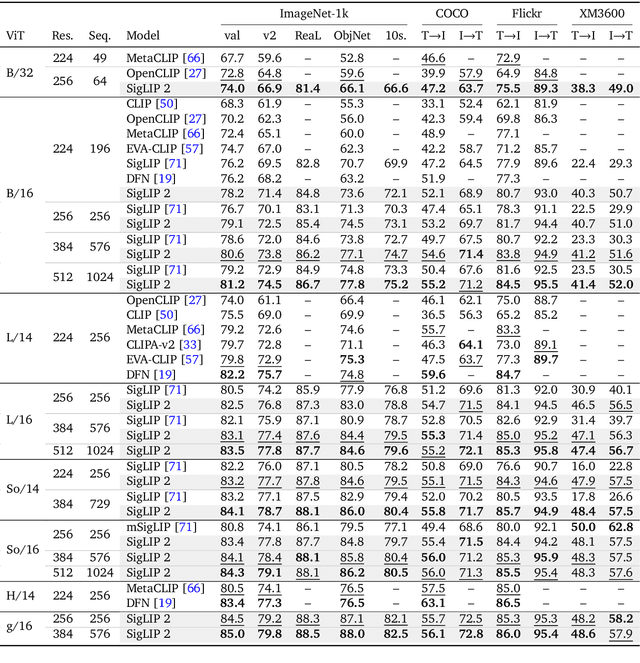
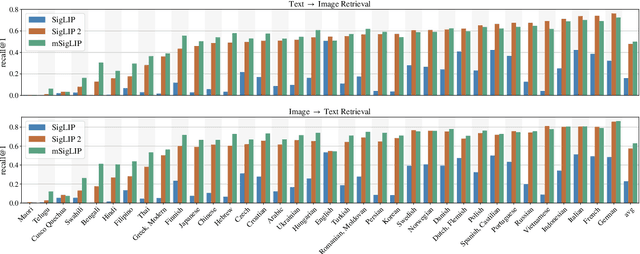
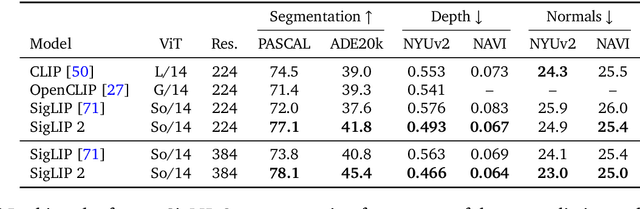
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025



We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
PaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Time-, Memory- and Parameter-Efficient Visual Adaptation
Feb 05, 2024As foundation models become more popular, there is a growing need to efficiently finetune them for downstream tasks. Although numerous adaptation methods have been proposed, they are designed to be efficient only in terms of how many parameters are trained. They, however, typically still require backpropagating gradients throughout the model, meaning that their training-time and -memory cost does not reduce as significantly. We propose an adaptation method which does not backpropagate gradients through the backbone. We achieve this by designing a lightweight network in parallel that operates on features from the frozen, pretrained backbone. As a result, our method is efficient not only in terms of parameters, but also in training-time and memory usage. Our approach achieves state-of-the-art accuracy-parameter trade-offs on the popular VTAB benchmark, and we further show how we outperform prior works with respect to training-time and -memory usage too. We further demonstrate the training efficiency and scalability of our method by adapting a vision transformer backbone of 4 billion parameters for the computationally demanding task of video classification, without any intricate model parallelism. Here, we outperform a prior adaptor-based method which could only scale to a 1 billion parameter backbone, or fully-finetuning a smaller backbone, with the same GPU and less training time.
Video OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Jul 12, 2023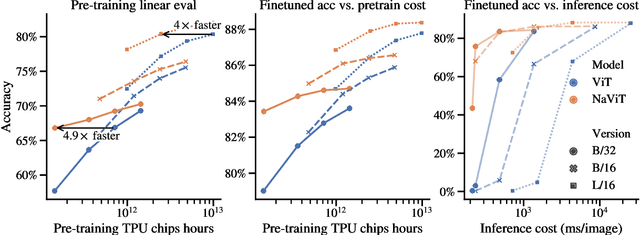
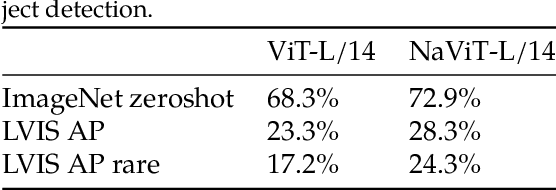
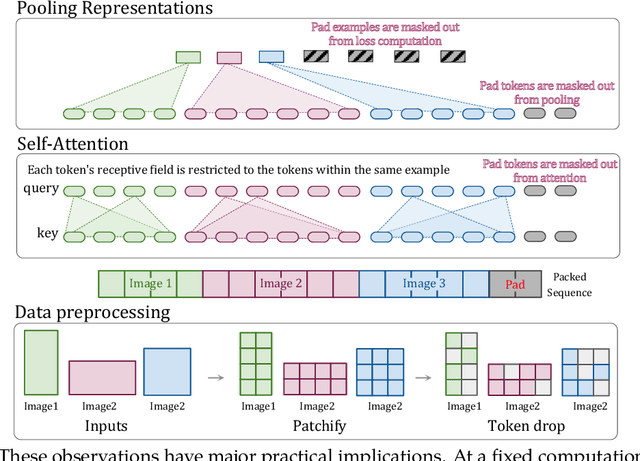
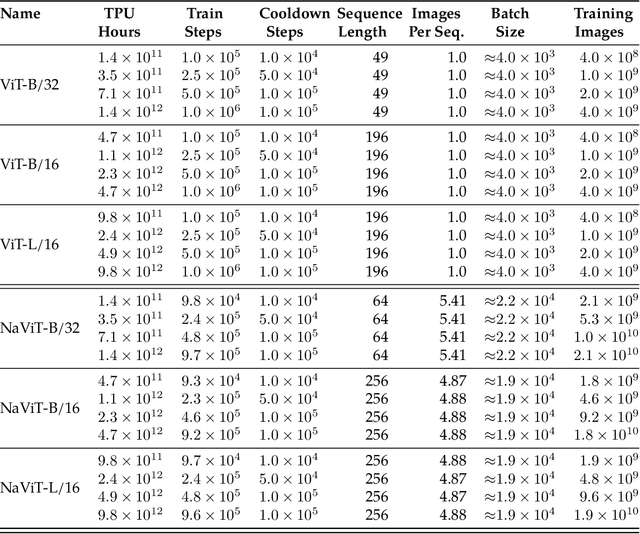
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.
Scaling Open-Vocabulary Object Detection
Jun 16, 2023Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.
End-to-End Spatio-Temporal Action Localisation with Video Transformers
Apr 24, 2023



The most performant spatio-temporal action localisation models use external person proposals and complex external memory banks. We propose a fully end-to-end, purely-transformer based model that directly ingests an input video, and outputs tubelets -- a sequence of bounding boxes and the action classes at each frame. Our flexible model can be trained with either sparse bounding-box supervision on individual frames, or full tubelet annotations. And in both cases, it predicts coherent tubelets as the output. Moreover, our end-to-end model requires no additional pre-processing in the form of proposals, or post-processing in terms of non-maximal suppression. We perform extensive ablation experiments, and significantly advance the state-of-the-art results on four different spatio-temporal action localisation benchmarks with both sparse keyframes and full tubelet annotations.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.