 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataComp-VLM: Improved Open Datasets for Vision-Language Models
Jun 30, 2026Building performant Vision-Language Models (VLMs) requires carefully curating large-scale training datasets, yet the community lacks systematic benchmarks for evaluating such curation strategies. We introduce DataComp for VLMs (DCVLM), a benchmark for controlled data-centric experiments to improve VLM training. As part of DCVLM, we collect 160 datasets spanning four data types -- image-caption pairs, multimodal interleaved documents, text-only, and instruction-tuning data -- into a corpus of 6T multimodal tokens. DCVLM allows participants to test curation strategies (filtering, mixing, formatting, sampling) across 1B-8B models and 6.25B-200B token budgets. Models are then evaluated on a carefully selected suite of up to 52 downstream benchmarks across 9 domains. We conduct extensive experiments on DCVLM and find that data mixing, not filtering, is key to a high-quality training dataset: instruction-heavy mixtures scale better than caption-heavy ones, with gains widening at larger scales. The resulting dataset, DCVLM-Baseline, enables training an 8B VLM to 63.6% accuracy on our 33-task core suite with 200B training tokens. Compared to FineVision, the state-of-the-art open VLM training dataset, this represents an improvement of +5.4pp. DCVLM and all accompanying artifacts will be made publicly available at https://www.datacomp.ai/dcvlm/.
Segmenting, Fast and Slow: Real-Time Open-Vocabulary Video Instance Segmentation with Dual-Path Processing
Jun 30, 2026Object-centric models inspired by DETR have become the dominant paradigm for open-vocabulary video instance segmentation (OV-VIS). While recent efforts have reduced the computational cost of pixel decoding, textual modality fusion, and object decoding to make these architectures more suitable for mobile devices, real-time on-device inference at high frame rates remains an open challenge. In this paper, we introduce SegFS, a dual-stream fast-slow framework that significantly improves efficiency without sacrificing accuracy. On sparse keyframes, an open-vocabulary object-based model predicts instance-level representations. These representations are then projected back into the backbone feature space to condition a lightweight fast network, which efficiently relocalizes and segments the instances in subsequent frames. By shifting instance propagation from object decoding to feature-space conditioning, our approach decouples multimodal semantic understanding from dense mask prediction and enables efficient temporal propagation. The proposed fast branch achieves up to 14x lower latency than the mobile-oriented MOBIUS model, while maintaining competitive segmentation performance on standard OV-VIS benchmarks.
PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
May 28, 2026Large Vision-Language Models (LVLMs) map visual inputs into dense token sequences, imposing a quadratic computational bottleneck for inference. Elastic visual-token compression addresses this by training a single model that can run at multiple visual-token budgets. However, existing approaches struggle under aggressive compression. Spatial-only compression, as in nested pooling, behaves as an imperfect low-pass filter and induces spectral aliasing that obscures fine-grained detail. Query-only compression, as in nested query resampling, replaces explicit grid-aligned tokens with non-local summaries and substantially degrades spatial grounding. To resolve this representational conflict, we introduce PARCEL (Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding), a visual tokenization architecture that dynamically partitions the labor of feature extraction. PARCEL establishes spatial pool tokens as low-frequency layout anchors and conditions elastic query tokens on these anchors through Pool-Conditioned Query Resampling. This encourages query tokens to focus on complementary visual features rather than redundant spatial mapping. Extensive evaluations across 27 benchmarks show that PARCEL improves the performance-efficiency Pareto frontier, consistently outperforming existing matryoshka baselines across visual-token budgets while preserving the "train once, deploy anywhere" paradigm.
RefAM: Attention Magnets for Zero-Shot Referral Segmentation
Sep 26, 2025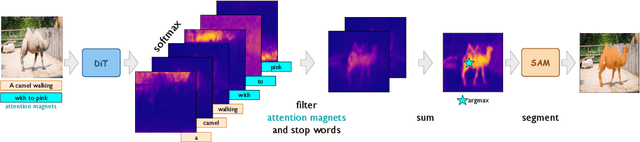
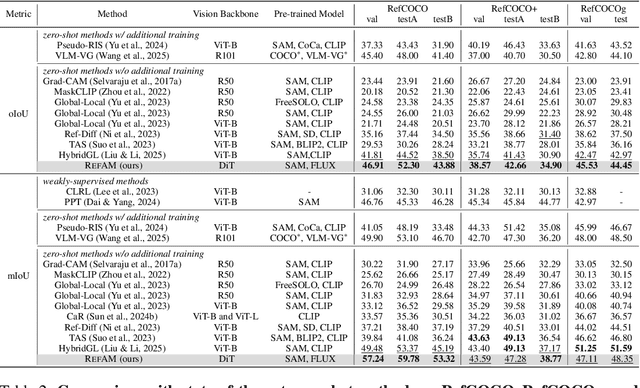

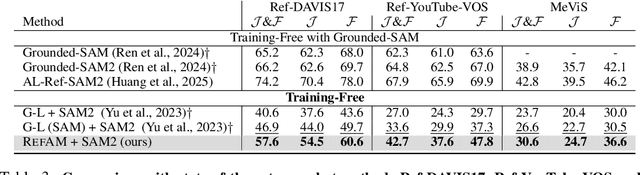
Most existing approaches to referring segmentation achieve strong performance only through fine-tuning or by composing multiple pre-trained models, often at the cost of additional training and architectural modifications. Meanwhile, large-scale generative diffusion models encode rich semantic information, making them attractive as general-purpose feature extractors. In this work, we introduce a new method that directly exploits features, attention scores, from diffusion transformers for downstream tasks, requiring neither architectural modifications nor additional training. To systematically evaluate these features, we extend benchmarks with vision-language grounding tasks spanning both images and videos. Our key insight is that stop words act as attention magnets: they accumulate surplus attention and can be filtered to reduce noise. Moreover, we identify global attention sinks (GAS) emerging in deeper layers and show that they can be safely suppressed or redirected onto auxiliary tokens, leading to sharper and more accurate grounding maps. We further propose an attention redistribution strategy, where appended stop words partition background activations into smaller clusters, yielding sharper and more localized heatmaps. Building on these findings, we develop RefAM, a simple training-free grounding framework that combines cross-attention maps, GAS handling, and redistribution. Across zero-shot referring image and video segmentation benchmarks, our approach consistently outperforms prior methods, establishing a new state of the art without fine-tuning or additional components.
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025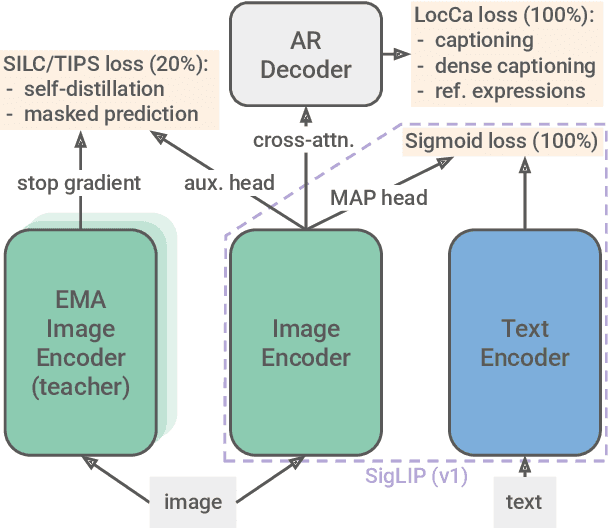
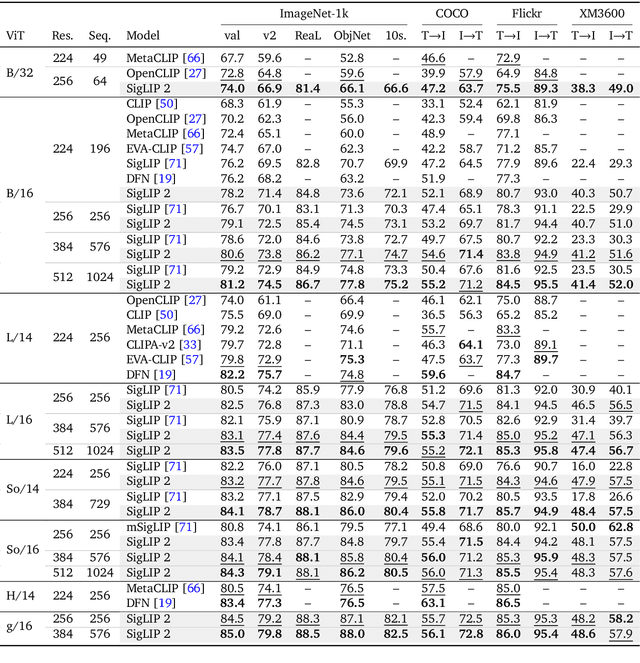
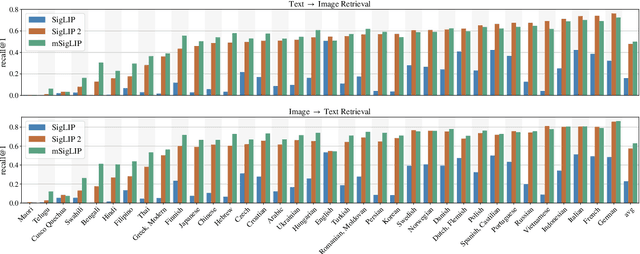
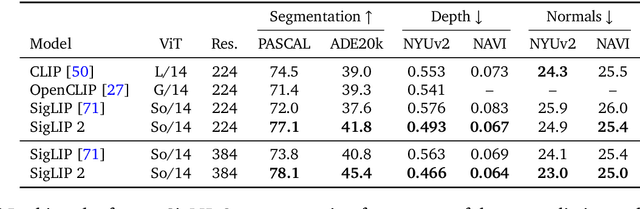
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
Active Data Curation Effectively Distills Large-Scale Multimodal Models
Nov 27, 2024Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective functions, teacher-ensembles, and weight inheritance. In this work we explore an alternative, yet simple approach -- active data curation as effective distillation for contrastive multimodal pretraining. Our simple online batch selection method, ACID, outperforms strong KD baselines across various model-, data- and compute-configurations. Further, we find such an active data curation strategy to in fact be complementary to standard KD, and can be effectively combined to train highly performant inference-efficient models. Our simple and scalable pretraining framework, ACED, achieves state-of-the-art results across 27 zero-shot classification and retrieval tasks with upto 11% less inference FLOPs. We further demonstrate that our ACED models yield strong vision-encoders for training generative multimodal models in the LiT-Decoder setting, outperforming larger vision encoders for image-captioning and visual question-answering tasks.
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Oct 30, 2024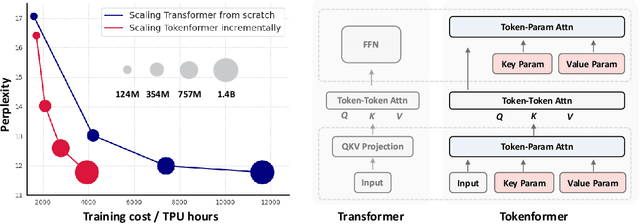
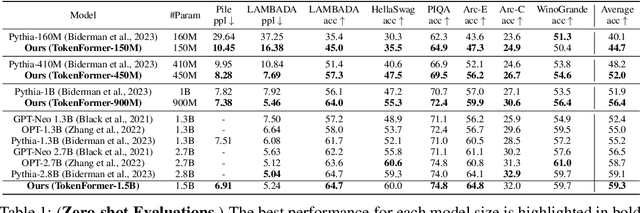
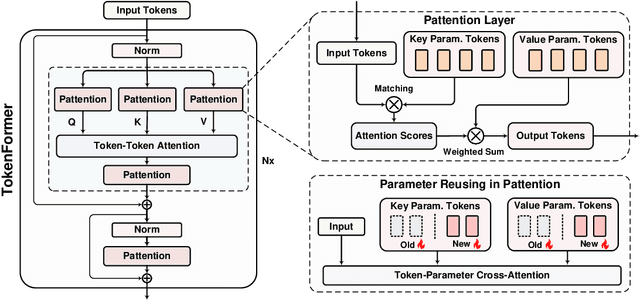
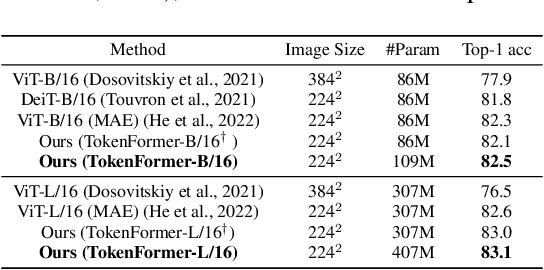
Transformers have become the predominant architecture in foundation models due to their excellent performance across various domains. However, the substantial cost of scaling these models remains a significant concern. This problem arises primarily from their dependence on a fixed number of parameters within linear projections. When architectural modifications (e.g., channel dimensions) are introduced, the entire model typically requires retraining from scratch. As model sizes continue growing, this strategy results in increasingly high computational costs and becomes unsustainable. To overcome this problem, we introduce TokenFormer, a natively scalable architecture that leverages the attention mechanism not only for computations among input tokens but also for interactions between tokens and model parameters, thereby enhancing architectural flexibility. By treating model parameters as tokens, we replace all the linear projections in Transformers with our token-parameter attention layer, where input tokens act as queries and model parameters as keys and values. This reformulation allows for progressive and efficient scaling without necessitating retraining from scratch. Our model scales from 124M to 1.4B parameters by incrementally adding new key-value parameter pairs, achieving performance comparable to Transformers trained from scratch while greatly reducing training costs. Code and models are available at \url{https://github.com/Haiyang-W/TokenFormer}.
Toward a Diffusion-Based Generalist for Dense Vision Tasks
Jun 29, 2024



Building generalized models that can solve many computer vision tasks simultaneously is an intriguing direction. Recent works have shown image itself can be used as a natural interface for general-purpose visual perception and demonstrated inspiring results. In this paper, we explore diffusion-based vision generalists, where we unify different types of dense prediction tasks as conditional image generation and re-purpose pre-trained diffusion models for it. However, directly applying off-the-shelf latent diffusion models leads to a quantization issue. Thus, we propose to perform diffusion in pixel space and provide a recipe for finetuning pre-trained text-to-image diffusion models for dense vision tasks. In experiments, we evaluate our method on four different types of tasks and show competitive performance to the other vision generalists.
How Good is my Video LMM? Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 08, 2024



Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical surgery, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, especially open-source ones, struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.
Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 06, 2024Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical imaging, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, {especially open-source ones,} struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.