 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRepCLIP: Contrastive Multimodal Pretraining on BRep Primitives for CAD Understanding
Jun 03, 2026Learning representations of CAD models is a largely open problem. While 3D representation learning has flourished around point clouds and meshes, the native format of CAD - boundary representations BReps, which encodes exact parametric surfaces, curves, and their topology, has received little attention as a representation learning substrate. We introduce BRepCLIP, the first framework to align BRep geometry with language and image embeddings through contrastive pretraining. We model each CAD object as a sequence of face and edge tokens with separate discrete vocabularies for surface and curve geometry, augmented with spatial and semantic descriptors that capture surface types (e.g., cylindrical, torus, NURBS) and curve primitives (e.g., line, arc, B-spline). A transformer encoder aggregates these tokens into a global BRep embedding, aligned with CLIP's text and image encoders via a joint contrastive objective. BRepCLIP generates more discriminative and semantically grounded embeddings than existing point-based alternatives, improving Top-1 retrieval over OpenShape by 40.4%, 22.0%, and 23.9% on ABC, CADParser, and Automate, respectively, and improving zero-shot classification on FabWave by 15% in Top-1 score. We further demonstrate its utility as a CAD-aware similarity metric for evaluating text and image-conditioned CAD generation, establishing the importance of structure-aware pretraining for multimodal CAD understanding. Project page is available at https://muhammadusama100.github.io/BrepClip2026/
ReConText3D: Replay-based Continual Text-to-3D Generation
Apr 15, 2026Continual learning enables models to acquire new knowledge over time while retaining previously learned capabilities. However, its application to text-to-3D generation remains unexplored. We present ReConText3D, the first framework for continual text-to-3D generation. We first demonstrate that existing text-to-3D models suffer from catastrophic forgetting under incremental training. ReConText3D enables generative models to incrementally learn new 3D categories from textual descriptions while preserving the ability to synthesize previously seen assets. Our method constructs a compact and diverse replay memory through text-embedding k-Center selection, allowing representative rehearsal of prior knowledge without modifying the underlying architecture. To systematically evaluate continual text-to-3D learning, we introduce Toys4K-CL, a benchmark derived from the Toys4K dataset that provides balanced and semantically diverse class-incremental splits. Extensive experiments on the Toys4K-CL benchmark show that ReConText3D consistently outperforms all baselines across different generative backbones, maintaining high-quality generation for both old and new classes. To the best of our knowledge, this work establishes the first continual learning framework and benchmark for text-to-3D generation, opening a new direction for incremental 3D generative modeling. Project page is available at: https://mauk95.github.io/ReConText3D/.
NURBGen: High-Fidelity Text-to-CAD Generation through LLM-Driven NURBS Modeling
Nov 15, 2025



Generating editable 3D CAD models from natural language remains challenging, as existing text-to-CAD systems either produce meshes or rely on scarce design-history data. We present NURBGen, the first framework to generate high-fidelity 3D CAD models directly from text using Non-Uniform Rational B-Splines (NURBS). To achieve this, we fine-tune a large language model (LLM) to translate free-form texts into JSON representations containing NURBS surface parameters (\textit{i.e}, control points, knot vectors, degrees, and rational weights) which can be directly converted into BRep format using Python. We further propose a hybrid representation that combines untrimmed NURBS with analytic primitives to handle trimmed surfaces and degenerate regions more robustly, while reducing token complexity. Additionally, we introduce partABC, a curated subset of the ABC dataset consisting of individual CAD components, annotated with detailed captions using an automated annotation pipeline. NURBGen demonstrates strong performance on diverse prompts, surpassing prior methods in geometric fidelity and dimensional accuracy, as confirmed by expert evaluations. Code and dataset will be released publicly.
Beyond Boxes: Mask-Guided Spatio-Temporal Feature Aggregation for Video Object Detection
Dec 06, 2024

The primary challenge in Video Object Detection (VOD) is effectively exploiting temporal information to enhance object representations. Traditional strategies, such as aggregating region proposals, often suffer from feature variance due to the inclusion of background information. We introduce a novel instance mask-based feature aggregation approach, significantly refining this process and deepening the understanding of object dynamics across video frames. We present FAIM, a new VOD method that enhances temporal Feature Aggregation by leveraging Instance Mask features. In particular, we propose the lightweight Instance Feature Extraction Module (IFEM) to learn instance mask features and the Temporal Instance Classification Aggregation Module (TICAM) to aggregate instance mask and classification features across video frames. Using YOLOX as a base detector, FAIM achieves 87.9% mAP on the ImageNet VID dataset at 33 FPS on a single 2080Ti GPU, setting a new benchmark for the speed-accuracy trade-off. Additional experiments on multiple datasets validate that our approach is robust, method-agnostic, and effective in multi-object tracking, demonstrating its broader applicability to video understanding tasks.
MARVEL-40M+: Multi-Level Visual Elaboration for High-Fidelity Text-to-3D Content Creation
Nov 26, 2024Generating high-fidelity 3D content from text prompts remains a significant challenge in computer vision due to the limited size, diversity, and annotation depth of the existing datasets. To address this, we introduce MARVEL-40M+, an extensive dataset with 40 million text annotations for over 8.9 million 3D assets aggregated from seven major 3D datasets. Our contribution is a novel multi-stage annotation pipeline that integrates open-source pretrained multi-view VLMs and LLMs to automatically produce multi-level descriptions, ranging from detailed (150-200 words) to concise semantic tags (10-20 words). This structure supports both fine-grained 3D reconstruction and rapid prototyping. Furthermore, we incorporate human metadata from source datasets into our annotation pipeline to add domain-specific information in our annotation and reduce VLM hallucinations. Additionally, we develop MARVEL-FX3D, a two-stage text-to-3D pipeline. We fine-tune Stable Diffusion with our annotations and use a pretrained image-to-3D network to generate 3D textured meshes within 15s. Extensive evaluations show that MARVEL-40M+ significantly outperforms existing datasets in annotation quality and linguistic diversity, achieving win rates of 72.41% by GPT-4 and 73.40% by human evaluators.
Classroom-Inspired Multi-Mentor Distillation with Adaptive Learning Strategies
Sep 30, 2024We propose ClassroomKD, a novel multi-mentor knowledge distillation framework inspired by classroom environments to enhance knowledge transfer between student and multiple mentors. Unlike traditional methods that rely on fixed mentor-student relationships, our framework dynamically selects and adapts the teaching strategies of diverse mentors based on their effectiveness for each data sample. ClassroomKD comprises two main modules: the Knowledge Filtering (KF) Module and the Mentoring Module. The KF Module dynamically ranks mentors based on their performance for each input, activating only high-quality mentors to minimize error accumulation and prevent information loss. The Mentoring Module adjusts the distillation strategy by tuning each mentor's influence according to the performance gap between the student and mentors, effectively modulating the learning pace. Extensive experiments on image classification (CIFAR-100 and ImageNet) and 2D human pose estimation (COCO Keypoints and MPII Human Pose) demonstrate that ClassroomKD significantly outperforms existing knowledge distillation methods. Our results highlight that a dynamic and adaptive approach to mentor selection and guidance leads to more effective knowledge transfer, paving the way for enhanced model performance through distillation.
Continual Human Pose Estimation for Incremental Integration of Keypoints and Pose Variations
Sep 30, 2024This paper reformulates cross-dataset human pose estimation as a continual learning task, aiming to integrate new keypoints and pose variations into existing models without losing accuracy on previously learned datasets. We benchmark this formulation against established regularization-based methods for mitigating catastrophic forgetting, including EWC, LFL, and LwF. Moreover, we propose a novel regularization method called Importance-Weighted Distillation (IWD), which enhances conventional LwF by introducing a layer-wise distillation penalty and dynamic temperature adjustment based on layer importance for previously learned knowledge. This allows for a controlled adaptation to new tasks that respects the stability-plasticity balance critical in continual learning. Through extensive experiments across three datasets, we demonstrate that our approach outperforms existing regularization-based continual learning strategies. IWD shows an average improvement of 3.60\% over the state-of-the-art LwF method. The results highlight the potential of our method to serve as a robust framework for real-world applications where models must evolve with new data without forgetting past knowledge.
Text2CAD: Generating Sequential CAD Models from Beginner-to-Expert Level Text Prompts
Sep 25, 2024



Prototyping complex computer-aided design (CAD) models in modern softwares can be very time-consuming. This is due to the lack of intelligent systems that can quickly generate simpler intermediate parts. We propose Text2CAD, the first AI framework for generating text-to-parametric CAD models using designer-friendly instructions for all skill levels. Furthermore, we introduce a data annotation pipeline for generating text prompts based on natural language instructions for the DeepCAD dataset using Mistral and LLaVA-NeXT. The dataset contains $\sim170$K models and $\sim660$K text annotations, from abstract CAD descriptions (e.g., generate two concentric cylinders) to detailed specifications (e.g., draw two circles with center $(x,y)$ and radius $r_{1}$, $r_{2}$, and extrude along the normal by $d$...). Within the Text2CAD framework, we propose an end-to-end transformer-based auto-regressive network to generate parametric CAD models from input texts. We evaluate the performance of our model through a mixture of metrics, including visual quality, parametric precision, and geometrical accuracy. Our proposed framework shows great potential in AI-aided design applications. Our source code and annotations will be publicly available.
Shape2.5D: A Dataset of Texture-less Surfaces for Depth and Normals Estimation
Jun 22, 2024



Reconstructing texture-less surfaces poses unique challenges in computer vision, primarily due to the lack of specialized datasets that cater to the nuanced needs of depth and normals estimation in the absence of textural information. We introduce "Shape2.5D," a novel, large-scale dataset designed to address this gap. Comprising 364k frames spanning 2635 3D models and 48 unique objects, our dataset provides depth and surface normal maps for texture-less object reconstruction. The proposed dataset includes synthetic images rendered with 3D modeling software to simulate various lighting conditions and viewing angles. It also includes a real-world subset comprising 4672 frames captured with a depth camera. Our comprehensive benchmarks, performed using a modified encoder-decoder network, showcase the dataset's capability to support the development of algorithms that robustly estimate depth and normals from RGB images. Our open-source data generation pipeline allows the dataset to be extended and adapted for future research. The dataset is publicly available at \url{https://github.com/saifkhichi96/Shape25D}.
Enhanced Bank Check Security: Introducing a Novel Dataset and Transformer-Based Approach for Detection and Verification
Jun 20, 2024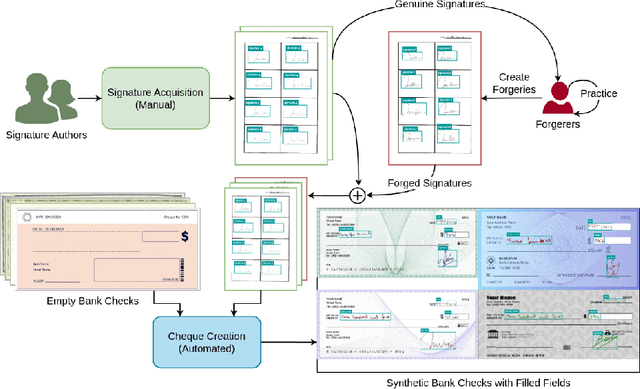
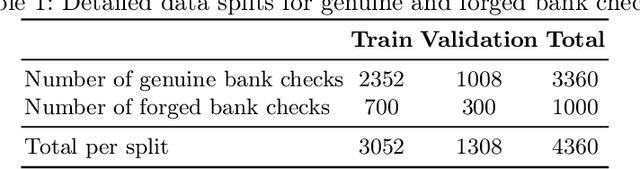
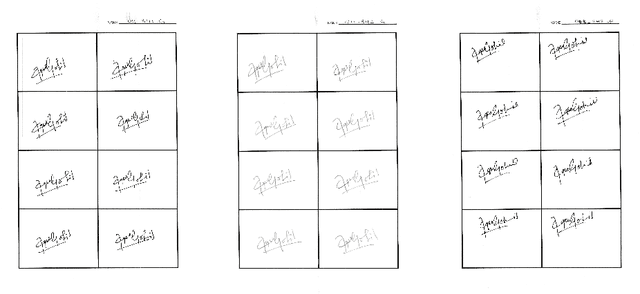
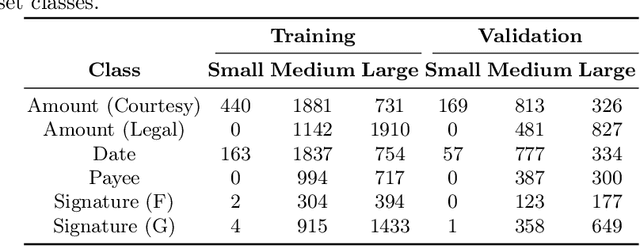
Automated signature verification on bank checks is critical for fraud prevention and ensuring transaction authenticity. This task is challenging due to the coexistence of signatures with other textual and graphical elements on real-world documents. Verification systems must first detect the signature and then validate its authenticity, a dual challenge often overlooked by current datasets and methodologies focusing only on verification. To address this gap, we introduce a novel dataset specifically designed for signature verification on bank checks. This dataset includes a variety of signature styles embedded within typical check elements, providing a realistic testing ground for advanced detection methods. Moreover, we propose a novel approach for writer-independent signature verification using an object detection network. Our detection-based verification method treats genuine and forged signatures as distinct classes within an object detection framework, effectively handling both detection and verification. We employ a DINO-based network augmented with a dilation module to detect and verify signatures on check images simultaneously. Our approach achieves an AP of 99.2 for genuine and 99.4 for forged signatures, a significant improvement over the DINO baseline, which scored 93.1 and 89.3 for genuine and forged signatures, respectively. This improvement highlights our dilation module's effectiveness in reducing both false positives and negatives. Our results demonstrate substantial advancements in detection-based signature verification technology, offering enhanced security and efficiency in financial document processing.