 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Boxes: Mask-Guided Spatio-Temporal Feature Aggregation for Video Object Detection
Dec 06, 2024

The primary challenge in Video Object Detection (VOD) is effectively exploiting temporal information to enhance object representations. Traditional strategies, such as aggregating region proposals, often suffer from feature variance due to the inclusion of background information. We introduce a novel instance mask-based feature aggregation approach, significantly refining this process and deepening the understanding of object dynamics across video frames. We present FAIM, a new VOD method that enhances temporal Feature Aggregation by leveraging Instance Mask features. In particular, we propose the lightweight Instance Feature Extraction Module (IFEM) to learn instance mask features and the Temporal Instance Classification Aggregation Module (TICAM) to aggregate instance mask and classification features across video frames. Using YOLOX as a base detector, FAIM achieves 87.9% mAP on the ImageNet VID dataset at 33 FPS on a single 2080Ti GPU, setting a new benchmark for the speed-accuracy trade-off. Additional experiments on multiple datasets validate that our approach is robust, method-agnostic, and effective in multi-object tracking, demonstrating its broader applicability to video understanding tasks.
UnSupDLA: Towards Unsupervised Document Layout Analysis
Jun 10, 2024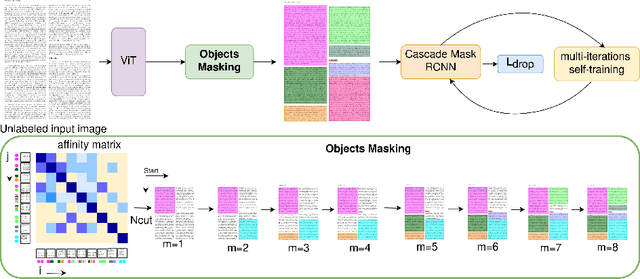


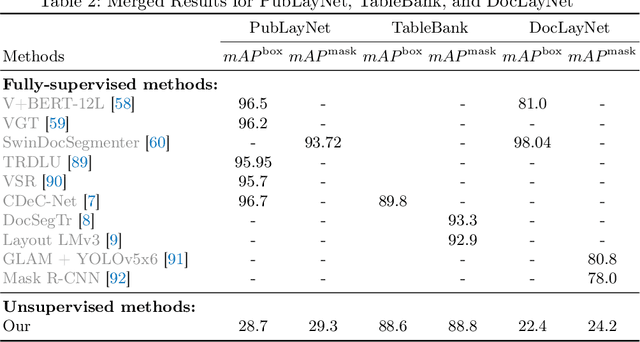
Document layout analysis is a key area in document research, involving techniques like text mining and visual analysis. Despite various methods developed to tackle layout analysis, a critical but frequently overlooked problem is the scarcity of labeled data needed for analyses. With the rise of internet use, an overwhelming number of documents are now available online, making the process of accurately labeling them for research purposes increasingly challenging and labor-intensive. Moreover, the diversity of documents online presents a unique set of challenges in maintaining the quality and consistency of these labels, further complicating document layout analysis in the digital era. To address this, we employ a vision-based approach for analyzing document layouts designed to train a network without labels. Instead, we focus on pre-training, initially generating simple object masks from the unlabeled document images. These masks are then used to train a detector, enhancing object detection and segmentation performance. The model's effectiveness is further amplified through several unsupervised training iterations, continuously refining its performance. This approach significantly advances document layout analysis, particularly precision and efficiency, without labels.
Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised Object Detection
Apr 02, 2024In this paper, we address the limitations of the DETR-based semi-supervised object detection (SSOD) framework, particularly focusing on the challenges posed by the quality of object queries. In DETR-based SSOD, the one-to-one assignment strategy provides inaccurate pseudo-labels, while the one-to-many assignments strategy leads to overlapping predictions. These issues compromise training efficiency and degrade model performance, especially in detecting small or occluded objects. We introduce Sparse Semi-DETR, a novel transformer-based, end-to-end semi-supervised object detection solution to overcome these challenges. Sparse Semi-DETR incorporates a Query Refinement Module to enhance the quality of object queries, significantly improving detection capabilities for small and partially obscured objects. Additionally, we integrate a Reliable Pseudo-Label Filtering Module that selectively filters high-quality pseudo-labels, thereby enhancing detection accuracy and consistency. On the MS-COCO and Pascal VOC object detection benchmarks, Sparse Semi-DETR achieves a significant improvement over current state-of-the-art methods that highlight Sparse Semi-DETR's effectiveness in semi-supervised object detection, particularly in challenging scenarios involving small or partially obscured objects.
FeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision
Aug 07, 2023

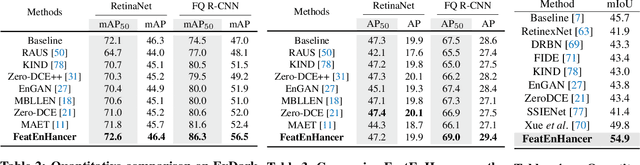

Extracting useful visual cues for the downstream tasks is especially challenging under low-light vision. Prior works create enhanced representations by either correlating visual quality with machine perception or designing illumination-degrading transformation methods that require pre-training on synthetic datasets. We argue that optimizing enhanced image representation pertaining to the loss of the downstream task can result in more expressive representations. Therefore, in this work, we propose a novel module, FeatEnHancer, that hierarchically combines multiscale features using multiheaded attention guided by task-related loss function to create suitable representations. Furthermore, our intra-scale enhancement improves the quality of features extracted at each scale or level, as well as combines features from different scales in a way that reflects their relative importance for the task at hand. FeatEnHancer is a general-purpose plug-and-play module and can be incorporated into any low-light vision pipeline. We show with extensive experimentation that the enhanced representation produced with FeatEnHancer significantly and consistently improves results in several low-light vision tasks, including dark object detection (+5.7 mAP on ExDark), face detection (+1.5 mAPon DARK FACE), nighttime semantic segmentation (+5.1 mIoU on ACDC ), and video object detection (+1.8 mAP on DarkVision), highlighting the effectiveness of enhancing hierarchical features under low-light vision.
Object Detection with Transformers: A Review
Jun 27, 2023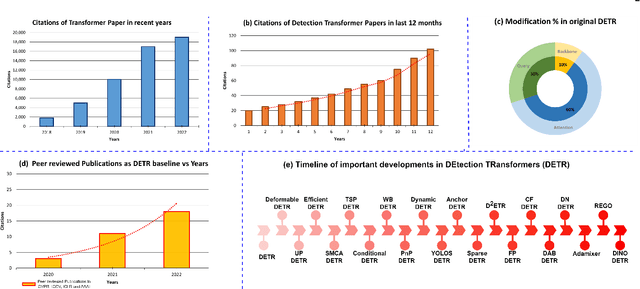
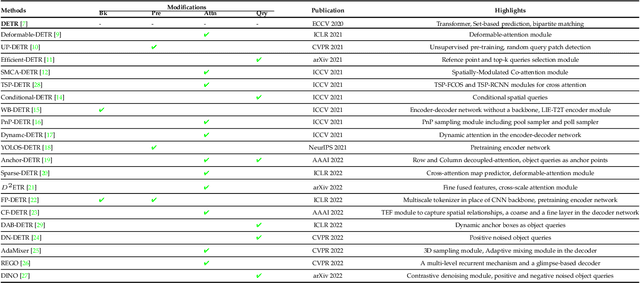
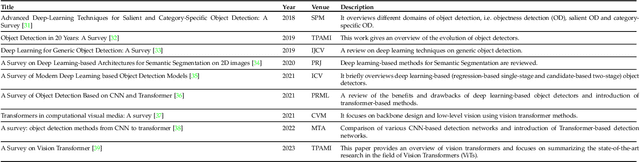
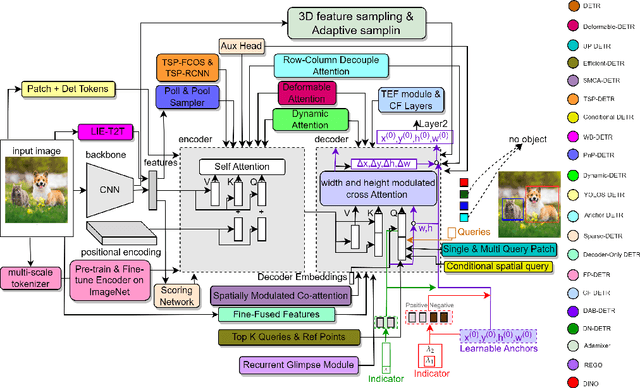
Astounding performance of Transformers in natural language processing (NLP) has delighted researchers to explore their utilization in computer vision tasks. Like other computer vision tasks, DEtection TRansformer (DETR) introduces transformers for object detection tasks by considering the detection as a set prediction problem without needing proposal generation and post-processing steps. It is a state-of-the-art (SOTA) method for object detection, particularly in scenarios where the number of objects in an image is relatively small. Despite the success of DETR, it suffers from slow training convergence and performance drops for small objects. Therefore, many improvements are proposed to address these issues, leading to immense refinement in DETR. Since 2020, transformer-based object detection has attracted increasing interest and demonstrated impressive performance. Although numerous surveys have been conducted on transformers in vision in general, a review regarding advancements made in 2D object detection using transformers is still missing. This paper gives a detailed review of twenty-one papers about recent developments in DETR. We begin with the basic modules of Transformers, such as self-attention, object queries and input features encoding. Then, we cover the latest advancements in DETR, including backbone modification, query design and attention refinement. We also compare all detection transformers in terms of performance and network design. We hope this study will increase the researcher's interest in solving existing challenges towards applying transformers in the object detection domain. Researchers can follow newer improvements in detection transformers on this webpage available at: https://github.com/mindgarage-shan/trans_object_detection_survey
Bridging the Performance Gap between DETR and R-CNN for Graphical Object Detection in Document Images
Jun 23, 2023This paper takes an important step in bridging the performance gap between DETR and R-CNN for graphical object detection. Existing graphical object detection approaches have enjoyed recent enhancements in CNN-based object detection methods, achieving remarkable progress. Recently, Transformer-based detectors have considerably boosted the generic object detection performance, eliminating the need for hand-crafted features or post-processing steps such as Non-Maximum Suppression (NMS) using object queries. However, the effectiveness of such enhanced transformer-based detection algorithms has yet to be verified for the problem of graphical object detection. Essentially, inspired by the latest advancements in the DETR, we employ the existing detection transformer with few modifications for graphical object detection. We modify object queries in different ways, using points, anchor boxes and adding positive and negative noise to the anchors to boost performance. These modifications allow for better handling of objects with varying sizes and aspect ratios, more robustness to small variations in object positions and sizes, and improved image discrimination between objects and non-objects. We evaluate our approach on the four graphical datasets: PubTables, TableBank, NTable and PubLaynet. Upon integrating query modifications in the DETR, we outperform prior works and achieve new state-of-the-art results with the mAP of 96.9\%, 95.7\% and 99.3\% on TableBank, PubLaynet, PubTables, respectively. The results from extensive ablations show that transformer-based methods are more effective for document analysis analogous to other applications. We hope this study draws more attention to the research of using detection transformers in document image analysis.
Towards End-to-End Semi-Supervised Table Detection with Deformable Transformer
May 07, 2023Table detection is the task of classifying and localizing table objects within document images. With the recent development in deep learning methods, we observe remarkable success in table detection. However, a significant amount of labeled data is required to train these models effectively. Many semi-supervised approaches are introduced to mitigate the need for a substantial amount of label data. These approaches use CNN-based detectors that rely on anchor proposals and post-processing stages such as NMS. To tackle these limitations, this paper presents a novel end-to-end semi-supervised table detection method that employs the deformable transformer for detecting table objects. We evaluate our semi-supervised method on PubLayNet, DocBank, ICADR-19 and TableBank datasets, and it achieves superior performance compared to previous methods. It outperforms the fully supervised method (Deformable transformer) by +3.4 points on 10\% labels of TableBank-both dataset and the previous CNN-based semi-supervised approach (Soft Teacher) by +1.8 points on 10\% labels of PubLayNet dataset. We hope this work opens new possibilities towards semi-supervised and unsupervised table detection methods.
BoxMask: Revisiting Bounding Box Supervision for Video Object Detection
Oct 12, 2022

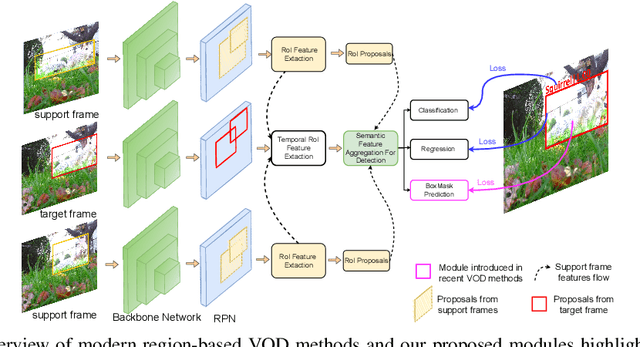

We present a new, simple yet effective approach to uplift video object detection. We observe that prior works operate on instance-level feature aggregation that imminently neglects the refined pixel-level representation, resulting in confusion among objects sharing similar appearance or motion characteristics. To address this limitation, we propose BoxMask, which effectively learns discriminative representations by incorporating class-aware pixel-level information. We simply consider bounding box-level annotations as a coarse mask for each object to supervise our method. The proposed module can be effortlessly integrated into any region-based detector to boost detection. Extensive experiments on ImageNet VID and EPIC KITCHENS datasets demonstrate consistent and significant improvement when we plug our BoxMask module into numerous recent state-of-the-art methods.
Spatio-Temporal Learnable Proposals for End-to-End Video Object Detection
Oct 07, 2022
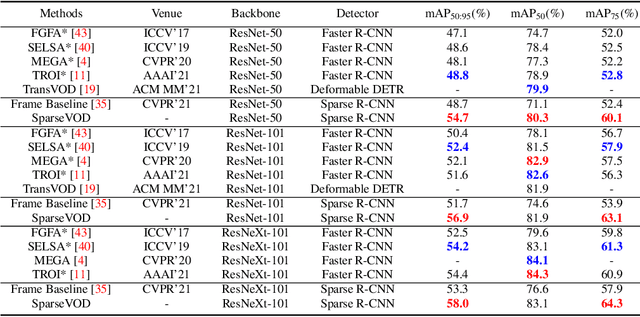

This paper presents the novel idea of generating object proposals by leveraging temporal information for video object detection. The feature aggregation in modern region-based video object detectors heavily relies on learned proposals generated from a single-frame RPN. This imminently introduces additional components like NMS and produces unreliable proposals on low-quality frames. To tackle these restrictions, we present SparseVOD, a novel video object detection pipeline that employs Sparse R-CNN to exploit temporal information. In particular, we introduce two modules in the dynamic head of Sparse R-CNN. First, the Temporal Feature Extraction module based on the Temporal RoI Align operation is added to extract the RoI proposal features. Second, motivated by sequence-level semantic aggregation, we incorporate the attention-guided Semantic Proposal Feature Aggregation module to enhance object feature representation before detection. The proposed SparseVOD effectively alleviates the overhead of complicated post-processing methods and makes the overall pipeline end-to-end trainable. Extensive experiments show that our method significantly improves the single-frame Sparse RCNN by 8%-9% in mAP. Furthermore, besides achieving state-of-the-art 80.3% mAP on the ImageNet VID dataset with ResNet-50 backbone, our SparseVOD outperforms existing proposal-based methods by a significant margin on increasing IoU thresholds (IoU > 0.5).
Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks
May 08, 2021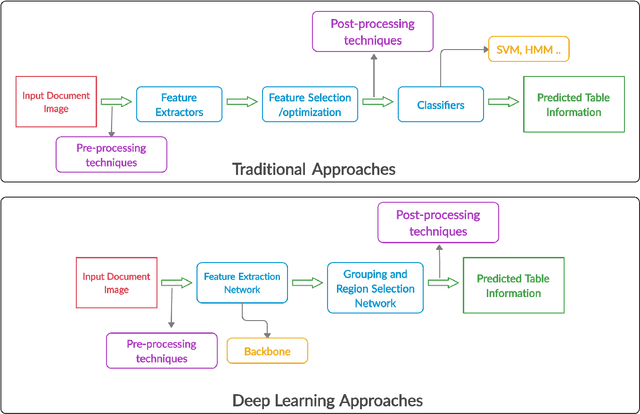

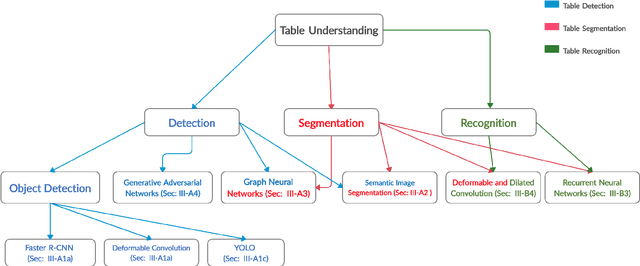

The first phase of table recognition is to detect the tabular area in a document. Subsequently, the tabular structures are recognized in the second phase in order to extract information from the respective cells. Table detection and structural recognition are pivotal problems in the domain of table understanding. However, table analysis is a perplexing task due to the colossal amount of diversity and asymmetry in tables. Therefore, it is an active area of research in document image analysis. Recent advances in the computing capabilities of graphical processing units have enabled deep neural networks to outperform traditional state-of-the-art machine learning methods. Table understanding has substantially benefited from the recent breakthroughs in deep neural networks. However, there has not been a consolidated description of the deep learning methods for table detection and table structure recognition. This review paper provides a thorough analysis of the modern methodologies that utilize deep neural networks. This work provided a thorough understanding of the current state-of-the-art and related challenges of table understanding in document images. Furthermore, the leading datasets and their intricacies have been elaborated along with the quantitative results. Moreover, a brief overview is given regarding the promising directions that can serve as a guide to further improve table analysis in document images.