 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision
Aug 07, 2023

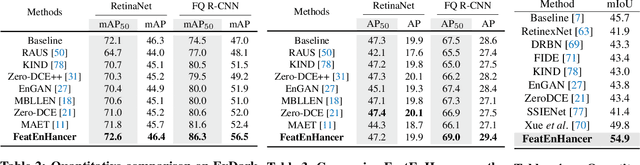

Extracting useful visual cues for the downstream tasks is especially challenging under low-light vision. Prior works create enhanced representations by either correlating visual quality with machine perception or designing illumination-degrading transformation methods that require pre-training on synthetic datasets. We argue that optimizing enhanced image representation pertaining to the loss of the downstream task can result in more expressive representations. Therefore, in this work, we propose a novel module, FeatEnHancer, that hierarchically combines multiscale features using multiheaded attention guided by task-related loss function to create suitable representations. Furthermore, our intra-scale enhancement improves the quality of features extracted at each scale or level, as well as combines features from different scales in a way that reflects their relative importance for the task at hand. FeatEnHancer is a general-purpose plug-and-play module and can be incorporated into any low-light vision pipeline. We show with extensive experimentation that the enhanced representation produced with FeatEnHancer significantly and consistently improves results in several low-light vision tasks, including dark object detection (+5.7 mAP on ExDark), face detection (+1.5 mAPon DARK FACE), nighttime semantic segmentation (+5.1 mIoU on ACDC ), and video object detection (+1.8 mAP on DarkVision), highlighting the effectiveness of enhancing hierarchical features under low-light vision.
BoxMask: Revisiting Bounding Box Supervision for Video Object Detection
Oct 12, 2022

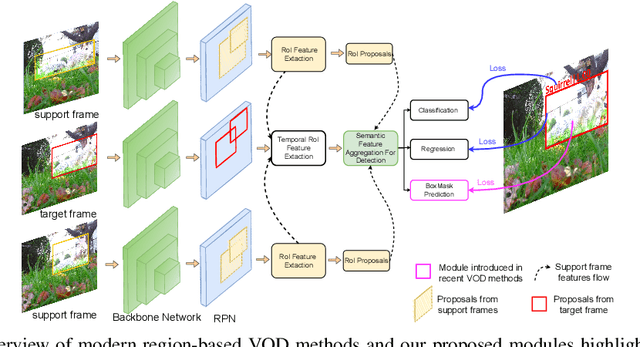

We present a new, simple yet effective approach to uplift video object detection. We observe that prior works operate on instance-level feature aggregation that imminently neglects the refined pixel-level representation, resulting in confusion among objects sharing similar appearance or motion characteristics. To address this limitation, we propose BoxMask, which effectively learns discriminative representations by incorporating class-aware pixel-level information. We simply consider bounding box-level annotations as a coarse mask for each object to supervise our method. The proposed module can be effortlessly integrated into any region-based detector to boost detection. Extensive experiments on ImageNet VID and EPIC KITCHENS datasets demonstrate consistent and significant improvement when we plug our BoxMask module into numerous recent state-of-the-art methods.
Spatio-Temporal Learnable Proposals for End-to-End Video Object Detection
Oct 07, 2022
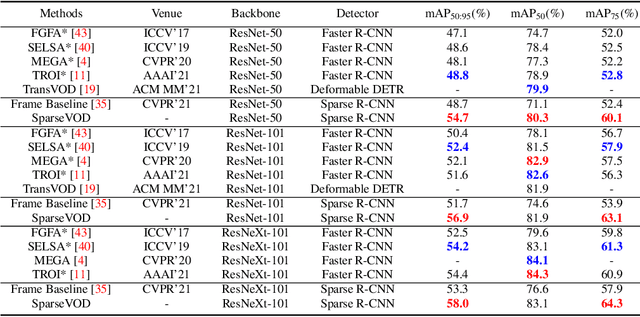
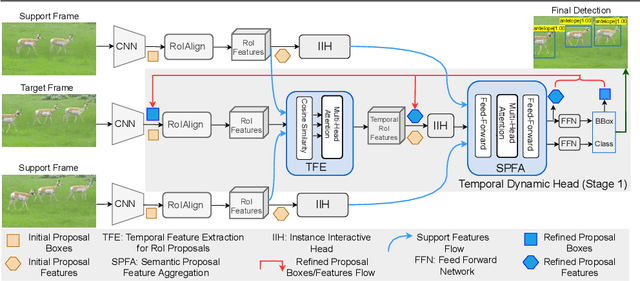

This paper presents the novel idea of generating object proposals by leveraging temporal information for video object detection. The feature aggregation in modern region-based video object detectors heavily relies on learned proposals generated from a single-frame RPN. This imminently introduces additional components like NMS and produces unreliable proposals on low-quality frames. To tackle these restrictions, we present SparseVOD, a novel video object detection pipeline that employs Sparse R-CNN to exploit temporal information. In particular, we introduce two modules in the dynamic head of Sparse R-CNN. First, the Temporal Feature Extraction module based on the Temporal RoI Align operation is added to extract the RoI proposal features. Second, motivated by sequence-level semantic aggregation, we incorporate the attention-guided Semantic Proposal Feature Aggregation module to enhance object feature representation before detection. The proposed SparseVOD effectively alleviates the overhead of complicated post-processing methods and makes the overall pipeline end-to-end trainable. Extensive experiments show that our method significantly improves the single-frame Sparse RCNN by 8%-9% in mAP. Furthermore, besides achieving state-of-the-art 80.3% mAP on the ImageNet VID dataset with ResNet-50 backbone, our SparseVOD outperforms existing proposal-based methods by a significant margin on increasing IoU thresholds (IoU > 0.5).