 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInpaint360GS: Efficient Object-Aware 3D Inpainting via Gaussian Splatting for 360° Scenes
Nov 09, 2025Despite recent advances in single-object front-facing inpainting using NeRF and 3D Gaussian Splatting (3DGS), inpainting in complex 360° scenes remains largely underexplored. This is primarily due to three key challenges: (i) identifying target objects in the 3D field of 360° environments, (ii) dealing with severe occlusions in multi-object scenes, which makes it hard to define regions to inpaint, and (iii) maintaining consistent and high-quality appearance across views effectively. To tackle these challenges, we propose Inpaint360GS, a flexible 360° editing framework based on 3DGS that supports multi-object removal and high-fidelity inpainting in 3D space. By distilling 2D segmentation into 3D and leveraging virtual camera views for contextual guidance, our method enables accurate object-level editing and consistent scene completion. We further introduce a new dataset tailored for 360° inpainting, addressing the lack of ground truth object-free scenes. Experiments demonstrate that Inpaint360GS outperforms existing baselines and achieves state-of-the-art performance. Project page: https://dfki-av.github.io/inpaint360gs/
EventEgo3D++: 3D Human Motion Capture from a Head-Mounted Event Camera
Feb 11, 2025Monocular egocentric 3D human motion capture remains a significant challenge, particularly under conditions of low lighting and fast movements, which are common in head-mounted device applications. Existing methods that rely on RGB cameras often fail under these conditions. To address these limitations, we introduce EventEgo3D++, the first approach that leverages a monocular event camera with a fisheye lens for 3D human motion capture. Event cameras excel in high-speed scenarios and varying illumination due to their high temporal resolution, providing reliable cues for accurate 3D human motion capture. EventEgo3D++ leverages the LNES representation of event streams to enable precise 3D reconstructions. We have also developed a mobile head-mounted device (HMD) prototype equipped with an event camera, capturing a comprehensive dataset that includes real event observations from both controlled studio environments and in-the-wild settings, in addition to a synthetic dataset. Additionally, to provide a more holistic dataset, we include allocentric RGB streams that offer different perspectives of the HMD wearer, along with their corresponding SMPL body model. Our experiments demonstrate that EventEgo3D++ achieves superior 3D accuracy and robustness compared to existing solutions, even in challenging conditions. Moreover, our method supports real-time 3D pose updates at a rate of 140Hz. This work is an extension of the EventEgo3D approach (CVPR 2024) and further advances the state of the art in egocentric 3D human motion capture. For more details, visit the project page at https://eventego3d.mpi-inf.mpg.de.
3D Spatial Understanding in MLLMs: Disambiguation and Evaluation
Dec 09, 2024



Multimodal Large Language Models (MLLMs) have made significant progress in tasks such as image captioning and question answering. However, while these models can generate realistic captions, they often struggle with providing precise instructions, particularly when it comes to localizing and disambiguating objects in complex 3D environments. This capability is critical as MLLMs become more integrated with collaborative robotic systems. In scenarios where a target object is surrounded by similar objects (distractors), robots must deliver clear, spatially-aware instructions to guide humans effectively. We refer to this challenge as contextual object localization and disambiguation, which imposes stricter constraints than conventional 3D dense captioning, especially regarding ensuring target exclusivity. In response, we propose simple yet effective techniques to enhance the model's ability to localize and disambiguate target objects. Our approach not only achieves state-of-the-art performance on conventional metrics that evaluate sentence similarity, but also demonstrates improved 3D spatial understanding through 3D visual grounding model.
Uni-SLAM: Uncertainty-Aware Neural Implicit SLAM for Real-Time Dense Indoor Scene Reconstruction
Nov 29, 2024



Neural implicit fields have recently emerged as a powerful representation method for multi-view surface reconstruction due to their simplicity and state-of-the-art performance. However, reconstructing thin structures of indoor scenes while ensuring real-time performance remains a challenge for dense visual SLAM systems. Previous methods do not consider varying quality of input RGB-D data and employ fixed-frequency mapping process to reconstruct the scene, which could result in the loss of valuable information in some frames. In this paper, we propose Uni-SLAM, a decoupled 3D spatial representation based on hash grids for indoor reconstruction. We introduce a novel defined predictive uncertainty to reweight the loss function, along with strategic local-to-global bundle adjustment. Experiments on synthetic and real-world datasets demonstrate that our system achieves state-of-the-art tracking and mapping accuracy while maintaining real-time performance. It significantly improves over current methods with a 25% reduction in depth L1 error and a 66.86% completion rate within 1 cm on the Replica dataset, reflecting a more accurate reconstruction of thin structures. Project page: https://shaoxiang777.github.io/project/uni-slam/
G3FA: Geometry-guided GAN for Face Animation
Aug 23, 2024



Animating human face images aims to synthesize a desired source identity in a natural-looking way mimicking a driving video's facial movements. In this context, Generative Adversarial Networks have demonstrated remarkable potential in real-time face reenactment using a single source image, yet are constrained by limited geometry consistency compared to graphic-based approaches. In this paper, we introduce Geometry-guided GAN for Face Animation (G3FA) to tackle this limitation. Our novel approach empowers the face animation model to incorporate 3D information using only 2D images, improving the image generation capabilities of the talking head synthesis model. We integrate inverse rendering techniques to extract 3D facial geometry properties, improving the feedback loop to the generator through a weighted average ensemble of discriminators. In our face reenactment model, we leverage 2D motion warping to capture motion dynamics along with orthogonal ray sampling and volume rendering techniques to produce the ultimate visual output. To evaluate the performance of our G3FA, we conducted comprehensive experiments using various evaluation protocols on VoxCeleb2 and TalkingHead benchmarks to demonstrate the effectiveness of our proposed framework compared to the state-of-the-art real-time face animation methods.
SG-PGM: Partial Graph Matching Network with Semantic Geometric Fusion for 3D Scene Graph Alignment and Its Downstream Tasks
Mar 28, 2024



Scene graphs have been recently introduced into 3D spatial understanding as a comprehensive representation of the scene. The alignment between 3D scene graphs is the first step of many downstream tasks such as scene graph aided point cloud registration, mosaicking, overlap checking, and robot navigation. In this work, we treat 3D scene graph alignment as a partial graph-matching problem and propose to solve it with a graph neural network. We reuse the geometric features learned by a point cloud registration method and associate the clustered point-level geometric features with the node-level semantic feature via our designed feature fusion module. Partial matching is enabled by using a learnable method to select the top-k similar node pairs. Subsequent downstream tasks such as point cloud registration are achieved by running a pre-trained registration network within the matched regions. We further propose a point-matching rescoring method, that uses the node-wise alignment of the 3D scene graph to reweight the matching candidates from a pre-trained point cloud registration method. It reduces the false point correspondences estimated especially in low-overlapping cases. Experiments show that our method improves the alignment accuracy by 10~20% in low-overlap and random transformation scenarios and outperforms the existing work in multiple downstream tasks.
MiKASA: Multi-Key-Anchor & Scene-Aware Transformer for 3D Visual Grounding
Mar 11, 20243D visual grounding involves matching natural language descriptions with their corresponding objects in 3D spaces. Existing methods often face challenges with accuracy in object recognition and struggle in interpreting complex linguistic queries, particularly with descriptions that involve multiple anchors or are view-dependent. In response, we present the MiKASA (Multi-Key-Anchor Scene-Aware) Transformer. Our novel end-to-end trained model integrates a self-attention-based scene-aware object encoder and an original multi-key-anchor technique, enhancing object recognition accuracy and the understanding of spatial relationships. Furthermore, MiKASA improves the explainability of decision-making, facilitating error diagnosis. Our model achieves the highest overall accuracy in the Referit3D challenge for both the Sr3D and Nr3D datasets, particularly excelling by a large margin in categories that require viewpoint-dependent descriptions. The source code and additional resources for this project are available on GitHub: https://github.com/birdy666/MiKASA-3DVG
BoxMask: Revisiting Bounding Box Supervision for Video Object Detection
Oct 12, 2022

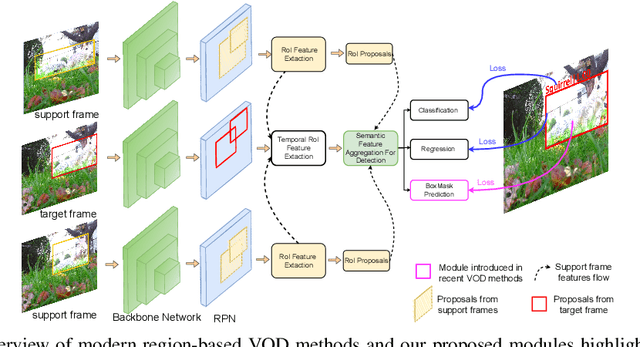

We present a new, simple yet effective approach to uplift video object detection. We observe that prior works operate on instance-level feature aggregation that imminently neglects the refined pixel-level representation, resulting in confusion among objects sharing similar appearance or motion characteristics. To address this limitation, we propose BoxMask, which effectively learns discriminative representations by incorporating class-aware pixel-level information. We simply consider bounding box-level annotations as a coarse mask for each object to supervise our method. The proposed module can be effortlessly integrated into any region-based detector to boost detection. Extensive experiments on ImageNet VID and EPIC KITCHENS datasets demonstrate consistent and significant improvement when we plug our BoxMask module into numerous recent state-of-the-art methods.
Structure PLP-SLAM: Efficient Sparse Mapping and Localization using Point, Line and Plane for Monocular, RGB-D and Stereo Cameras
Jul 19, 2022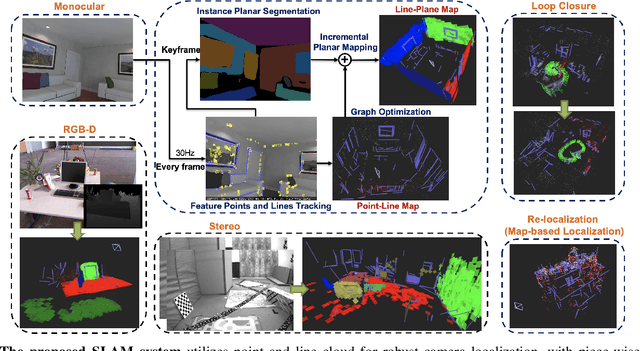
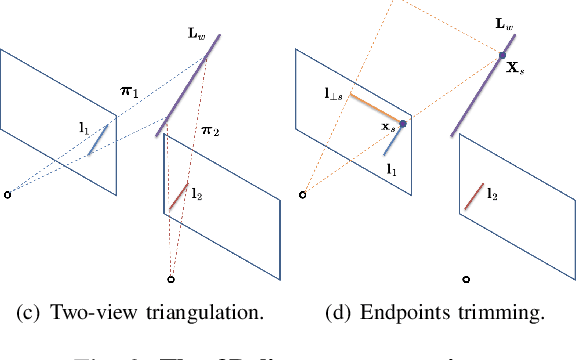
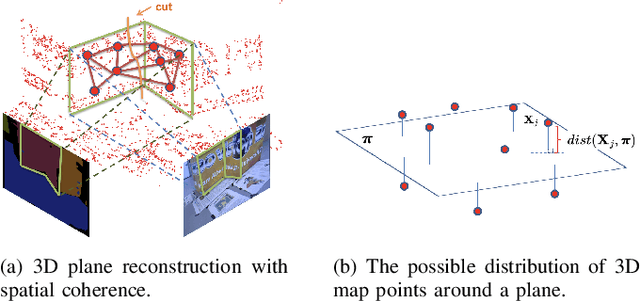

This paper demonstrates a visual SLAM system that utilizes point and line cloud for robust camera localization, simultaneously, with an embedded piece-wise planar reconstruction (PPR) module which in all provides a structural map. To build a scale consistent map in parallel with tracking, such as employing a single camera brings the challenge of reconstructing geometric primitives with scale ambiguity, and further introduces the difficulty in graph optimization of bundle adjustment (BA). We address these problems by proposing several run-time optimizations on the reconstructed lines and planes. The system is then extended with depth and stereo sensors based on the design of the monocular framework. The results show that our proposed SLAM tightly incorporates the semantic features to boost both frontend tracking as well as backend optimization. We evaluate our system exhaustively on various datasets, and open-source our code for the community (https://github.com/PeterFWS/Structure-PLP-SLAM).
PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Oct 21, 2021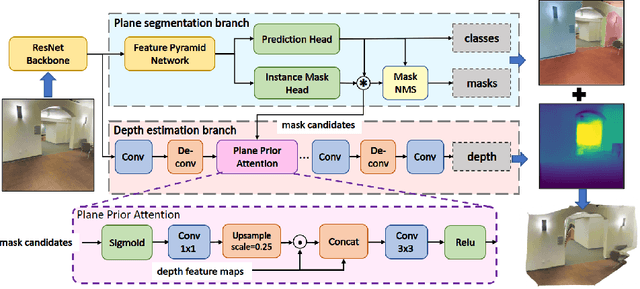

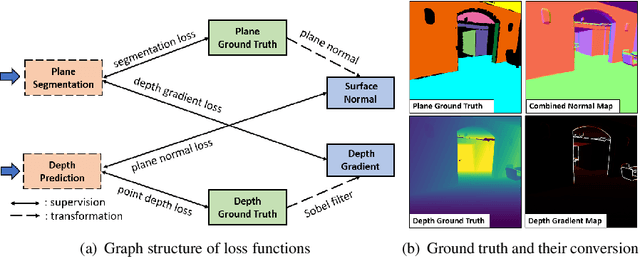

Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Most recent approaches focused on improving the segmentation and reconstruction results by introducing advanced network architectures but overlooked the dual characteristics of piece-wise planes as objects and geometric models. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image. To achieve this, we introduce several novel loss functions (geometric constraint) that jointly improve the accuracy of piece-wise planar segmentation and depth estimation. Meanwhile, a novel Plane Prior Attention module is used to guide depth estimation with the awareness of plane instances. Exhaustive experiments are conducted in this work to validate the effectiveness and efficiency of our method.