 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-SLAM: Uncertainty-Aware Neural Implicit SLAM for Real-Time Dense Indoor Scene Reconstruction
Nov 29, 2024



Neural implicit fields have recently emerged as a powerful representation method for multi-view surface reconstruction due to their simplicity and state-of-the-art performance. However, reconstructing thin structures of indoor scenes while ensuring real-time performance remains a challenge for dense visual SLAM systems. Previous methods do not consider varying quality of input RGB-D data and employ fixed-frequency mapping process to reconstruct the scene, which could result in the loss of valuable information in some frames. In this paper, we propose Uni-SLAM, a decoupled 3D spatial representation based on hash grids for indoor reconstruction. We introduce a novel defined predictive uncertainty to reweight the loss function, along with strategic local-to-global bundle adjustment. Experiments on synthetic and real-world datasets demonstrate that our system achieves state-of-the-art tracking and mapping accuracy while maintaining real-time performance. It significantly improves over current methods with a 25% reduction in depth L1 error and a 66.86% completion rate within 1 cm on the Replica dataset, reflecting a more accurate reconstruction of thin structures. Project page: https://shaoxiang777.github.io/project/uni-slam/
SG-PGM: Partial Graph Matching Network with Semantic Geometric Fusion for 3D Scene Graph Alignment and Its Downstream Tasks
Mar 28, 2024Scene graphs have been recently introduced into 3D spatial understanding as a comprehensive representation of the scene. The alignment between 3D scene graphs is the first step of many downstream tasks such as scene graph aided point cloud registration, mosaicking, overlap checking, and robot navigation. In this work, we treat 3D scene graph alignment as a partial graph-matching problem and propose to solve it with a graph neural network. We reuse the geometric features learned by a point cloud registration method and associate the clustered point-level geometric features with the node-level semantic feature via our designed feature fusion module. Partial matching is enabled by using a learnable method to select the top-k similar node pairs. Subsequent downstream tasks such as point cloud registration are achieved by running a pre-trained registration network within the matched regions. We further propose a point-matching rescoring method, that uses the node-wise alignment of the 3D scene graph to reweight the matching candidates from a pre-trained point cloud registration method. It reduces the false point correspondences estimated especially in low-overlapping cases. Experiments show that our method improves the alignment accuracy by 10~20% in low-overlap and random transformation scenarios and outperforms the existing work in multiple downstream tasks.
PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Oct 21, 2021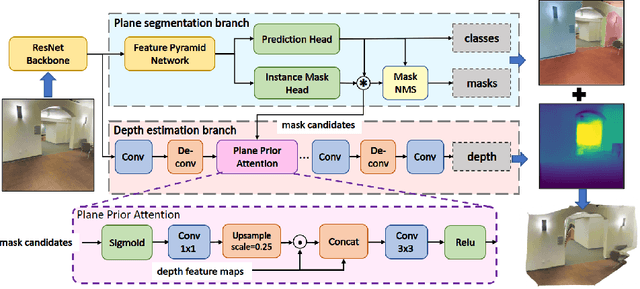

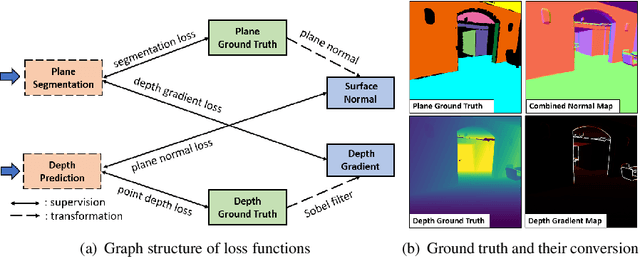

Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Most recent approaches focused on improving the segmentation and reconstruction results by introducing advanced network architectures but overlooked the dual characteristics of piece-wise planes as objects and geometric models. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image. To achieve this, we introduce several novel loss functions (geometric constraint) that jointly improve the accuracy of piece-wise planar segmentation and depth estimation. Meanwhile, a novel Plane Prior Attention module is used to guide depth estimation with the awareness of plane instances. Exhaustive experiments are conducted in this work to validate the effectiveness and efficiency of our method.
Visual SLAM with Graph-Cut Optimized Multi-Plane Reconstruction
Aug 09, 2021
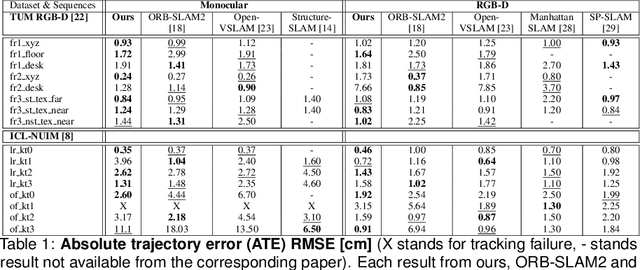
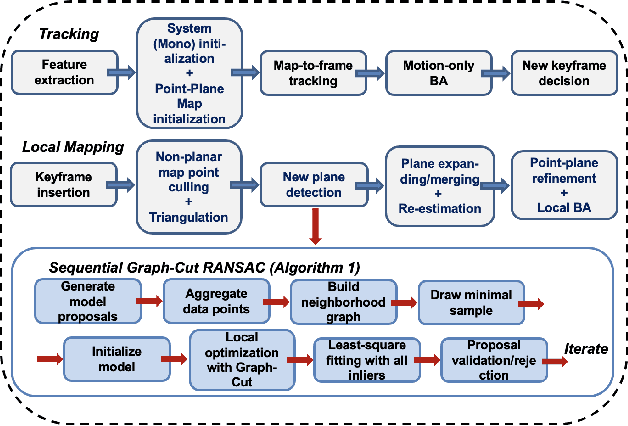

This paper presents a semantic planar SLAM system that improves pose estimation and mapping using cues from an instance planar segmentation network. While the mainstream approaches are using RGB-D sensors, employing a monocular camera with such a system still faces challenges such as robust data association and precise geometric model fitting. In the majority of existing work, geometric model estimation problems such as homography estimation and piece-wise planar reconstruction (PPR) are usually solved by standard (greedy) RANSAC separately and sequentially. However, setting the inlier-outlier threshold is difficult in absence of information about the scene (i.e. the scale). In this work, we revisit these problems and argue that two mentioned geometric models (homographies/3D planes) can be solved by minimizing an energy function that exploits the spatial coherence, i.e. with graph-cut optimization, which also tackles the practical issue when the output of a trained CNN is inaccurate. Moreover, we propose an adaptive parameter setting strategy based on our experiments, and report a comprehensive evaluation on various open-source datasets.
PlaneSegNet: Fast and Robust Plane Estimation Using a Single-stage Instance Segmentation CNN
Mar 29, 2021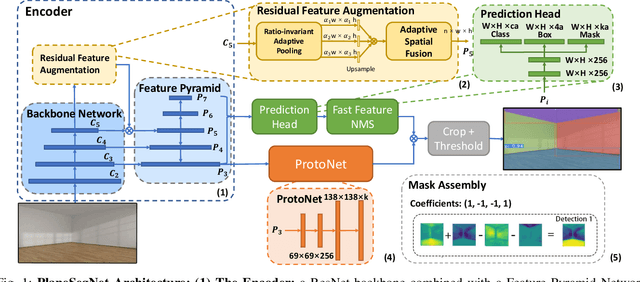



Instance segmentation of planar regions in indoor scenes benefits visual SLAM and other applications such as augmented reality (AR) where scene understanding is required. Existing methods built upon two-stage frameworks show satisfactory accuracy but are limited by low frame rates. In this work, we propose a real-time deep neural architecture that estimates piece-wise planar regions from a single RGB image. Our model employs a variant of a fast single-stage CNN architecture to segment plane instances. Considering the particularity of the target detected, we propose Fast Feature Non-maximum Suppression (FF-NMS) to reduce the suppression errors resulted from overlapping bounding boxes of planes. We also utilize a Residual Feature Augmentation module in the Feature Pyramid Network (FPN). Our method achieves significantly higher frame-rates and comparable segmentation accuracy against two-stage methods. We automatically label over 70,000 images as ground truth from the Stanford 2D-3D-Semantics dataset. Moreover, we incorporate our method with a state-of-the-art planar SLAM and validate its benefits.
SLAM in the Field: An Evaluation of Monocular Mapping and Localization on Challenging Dynamic Agricultural Environment
Nov 06, 2020
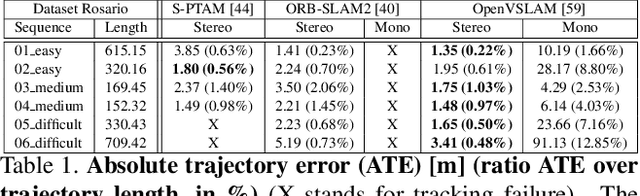
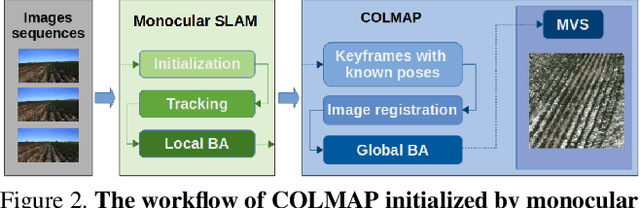
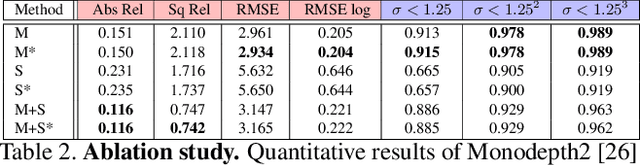
This paper demonstrates a system capable of combining a sparse, indirect, monocular visual SLAM, with both offline and real-time Multi-View Stereo (MVS) reconstruction algorithms. This combination overcomes many obstacles encountered by autonomous vehicles or robots employed in agricultural environments, such as overly repetitive patterns, need for very detailed reconstructions, and abrupt movements caused by uneven roads. Furthermore, the use of a monocular SLAM makes our system much easier to integrate with an existing device, as we do not rely on a LiDAR (which is expensive and power consuming), or stereo camera (whose calibration is sensitive to external perturbation e.g. camera being displaced). To the best of our knowledge, this paper presents the first evaluation results for monocular SLAM, and our work further explores unsupervised depth estimation on this specific application scenario by simulating RGB-D SLAM to tackle the scale ambiguity, and shows our approach produces reconstructions that are helpful to various agricultural tasks. Moreover, we highlight that our experiments provide meaningful insight to improve monocular SLAM systems under agricultural settings.