 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInpaint360GS: Efficient Object-Aware 3D Inpainting via Gaussian Splatting for 360° Scenes
Nov 09, 2025Despite recent advances in single-object front-facing inpainting using NeRF and 3D Gaussian Splatting (3DGS), inpainting in complex 360° scenes remains largely underexplored. This is primarily due to three key challenges: (i) identifying target objects in the 3D field of 360° environments, (ii) dealing with severe occlusions in multi-object scenes, which makes it hard to define regions to inpaint, and (iii) maintaining consistent and high-quality appearance across views effectively. To tackle these challenges, we propose Inpaint360GS, a flexible 360° editing framework based on 3DGS that supports multi-object removal and high-fidelity inpainting in 3D space. By distilling 2D segmentation into 3D and leveraging virtual camera views for contextual guidance, our method enables accurate object-level editing and consistent scene completion. We further introduce a new dataset tailored for 360° inpainting, addressing the lack of ground truth object-free scenes. Experiments demonstrate that Inpaint360GS outperforms existing baselines and achieves state-of-the-art performance. Project page: https://dfki-av.github.io/inpaint360gs/
EventEgo3D++: 3D Human Motion Capture from a Head-Mounted Event Camera
Feb 11, 2025Monocular egocentric 3D human motion capture remains a significant challenge, particularly under conditions of low lighting and fast movements, which are common in head-mounted device applications. Existing methods that rely on RGB cameras often fail under these conditions. To address these limitations, we introduce EventEgo3D++, the first approach that leverages a monocular event camera with a fisheye lens for 3D human motion capture. Event cameras excel in high-speed scenarios and varying illumination due to their high temporal resolution, providing reliable cues for accurate 3D human motion capture. EventEgo3D++ leverages the LNES representation of event streams to enable precise 3D reconstructions. We have also developed a mobile head-mounted device (HMD) prototype equipped with an event camera, capturing a comprehensive dataset that includes real event observations from both controlled studio environments and in-the-wild settings, in addition to a synthetic dataset. Additionally, to provide a more holistic dataset, we include allocentric RGB streams that offer different perspectives of the HMD wearer, along with their corresponding SMPL body model. Our experiments demonstrate that EventEgo3D++ achieves superior 3D accuracy and robustness compared to existing solutions, even in challenging conditions. Moreover, our method supports real-time 3D pose updates at a rate of 140Hz. This work is an extension of the EventEgo3D approach (CVPR 2024) and further advances the state of the art in egocentric 3D human motion capture. For more details, visit the project page at https://eventego3d.mpi-inf.mpg.de.
Uni-SLAM: Uncertainty-Aware Neural Implicit SLAM for Real-Time Dense Indoor Scene Reconstruction
Nov 29, 2024



Neural implicit fields have recently emerged as a powerful representation method for multi-view surface reconstruction due to their simplicity and state-of-the-art performance. However, reconstructing thin structures of indoor scenes while ensuring real-time performance remains a challenge for dense visual SLAM systems. Previous methods do not consider varying quality of input RGB-D data and employ fixed-frequency mapping process to reconstruct the scene, which could result in the loss of valuable information in some frames. In this paper, we propose Uni-SLAM, a decoupled 3D spatial representation based on hash grids for indoor reconstruction. We introduce a novel defined predictive uncertainty to reweight the loss function, along with strategic local-to-global bundle adjustment. Experiments on synthetic and real-world datasets demonstrate that our system achieves state-of-the-art tracking and mapping accuracy while maintaining real-time performance. It significantly improves over current methods with a 25% reduction in depth L1 error and a 66.86% completion rate within 1 cm on the Replica dataset, reflecting a more accurate reconstruction of thin structures. Project page: https://shaoxiang777.github.io/project/uni-slam/
EventEgo3D: 3D Human Motion Capture from Egocentric Event Streams
Apr 12, 2024



Monocular egocentric 3D human motion capture is a challenging and actively researched problem. Existing methods use synchronously operating visual sensors (e.g. RGB cameras) and often fail under low lighting and fast motions, which can be restricting in many applications involving head-mounted devices. In response to the existing limitations, this paper 1) introduces a new problem, i.e., 3D human motion capture from an egocentric monocular event camera with a fisheye lens, and 2) proposes the first approach to it called EventEgo3D (EE3D). Event streams have high temporal resolution and provide reliable cues for 3D human motion capture under high-speed human motions and rapidly changing illumination. The proposed EE3D framework is specifically tailored for learning with event streams in the LNES representation, enabling high 3D reconstruction accuracy. We also design a prototype of a mobile head-mounted device with an event camera and record a real dataset with event observations and the ground-truth 3D human poses (in addition to the synthetic dataset). Our EE3D demonstrates robustness and superior 3D accuracy compared to existing solutions across various challenging experiments while supporting real-time 3D pose update rates of 140Hz.
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera
Dec 21, 2023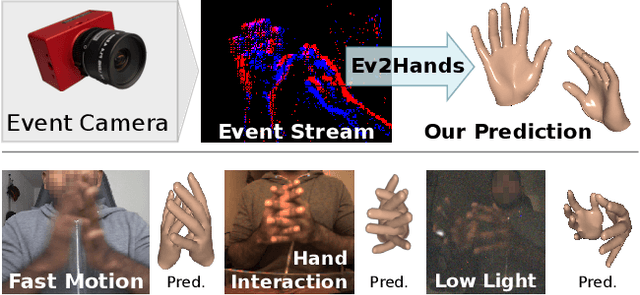

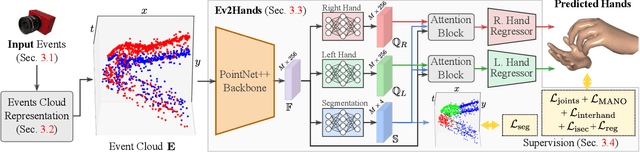

3D hand tracking from a monocular video is a very challenging problem due to hand interactions, occlusions, left-right hand ambiguity, and fast motion. Most existing methods rely on RGB inputs, which have severe limitations under low-light conditions and suffer from motion blur. In contrast, event cameras capture local brightness changes instead of full image frames and do not suffer from the described effects. Unfortunately, existing image-based techniques cannot be directly applied to events due to significant differences in the data modalities. In response to these challenges, this paper introduces the first framework for 3D tracking of two fast-moving and interacting hands from a single monocular event camera. Our approach tackles the left-right hand ambiguity with a novel semi-supervised feature-wise attention mechanism and integrates an intersection loss to fix hand collisions. To facilitate advances in this research domain, we release a new synthetic large-scale dataset of two interacting hands, Ev2Hands-S, and a new real benchmark with real event streams and ground-truth 3D annotations, Ev2Hands-R. Our approach outperforms existing methods in terms of the 3D reconstruction accuracy and generalises to real data under severe light conditions.
* 17 pages, 12 figures, 7 tables; project page: https://4dqv.mpi-inf.mpg.de/Ev2Hands/
Show Me Your Face, And I'll Tell You How You Speak
Jun 28, 2022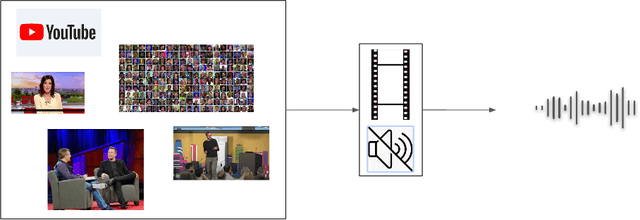

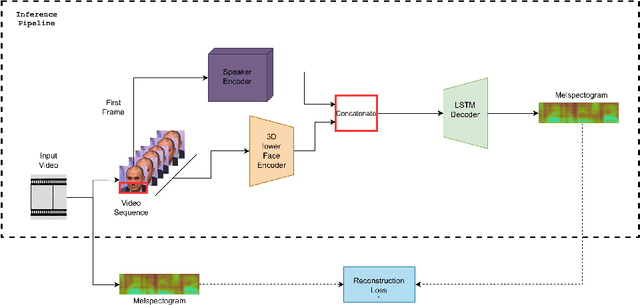

When we speak, the prosody and content of the speech can be inferred from the movement of our lips. In this work, we explore the task of lip to speech synthesis, i.e., learning to generate speech given only the lip movements of a speaker where we focus on learning accurate lip to speech mappings for multiple speakers in unconstrained, large vocabulary settings. We capture the speaker's voice identity through their facial characteristics, i.e., age, gender, ethnicity and condition them along with the lip movements to generate speaker identity aware speech. To this end, we present a novel method "Lip2Speech", with key design choices to achieve accurate lip to speech synthesis in unconstrained scenarios. We also perform various experiments and extensive evaluation using quantitative, qualitative metrics and human evaluation.