 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me Your Face, And I'll Tell You How You Speak
Jun 28, 2022

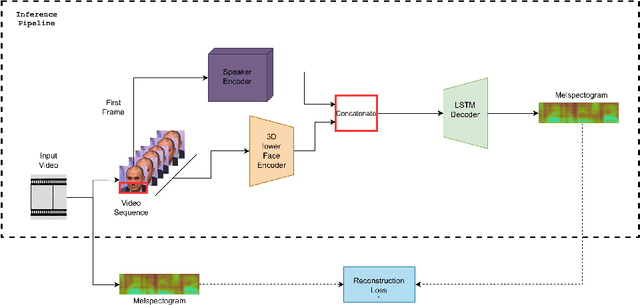

When we speak, the prosody and content of the speech can be inferred from the movement of our lips. In this work, we explore the task of lip to speech synthesis, i.e., learning to generate speech given only the lip movements of a speaker where we focus on learning accurate lip to speech mappings for multiple speakers in unconstrained, large vocabulary settings. We capture the speaker's voice identity through their facial characteristics, i.e., age, gender, ethnicity and condition them along with the lip movements to generate speaker identity aware speech. To this end, we present a novel method "Lip2Speech", with key design choices to achieve accurate lip to speech synthesis in unconstrained scenarios. We also perform various experiments and extensive evaluation using quantitative, qualitative metrics and human evaluation.