 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me Your Face, And I'll Tell You How You Speak
Jun 28, 2022

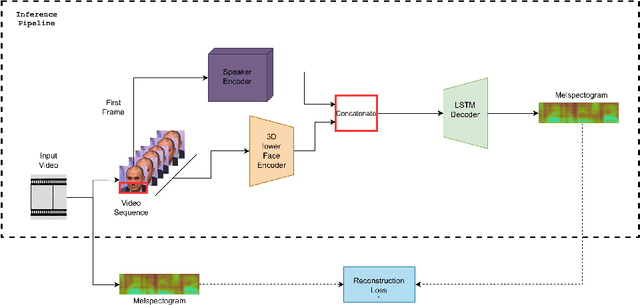

When we speak, the prosody and content of the speech can be inferred from the movement of our lips. In this work, we explore the task of lip to speech synthesis, i.e., learning to generate speech given only the lip movements of a speaker where we focus on learning accurate lip to speech mappings for multiple speakers in unconstrained, large vocabulary settings. We capture the speaker's voice identity through their facial characteristics, i.e., age, gender, ethnicity and condition them along with the lip movements to generate speaker identity aware speech. To this end, we present a novel method "Lip2Speech", with key design choices to achieve accurate lip to speech synthesis in unconstrained scenarios. We also perform various experiments and extensive evaluation using quantitative, qualitative metrics and human evaluation.
Breaking the De-Pois Poisoning Defense
Apr 03, 2022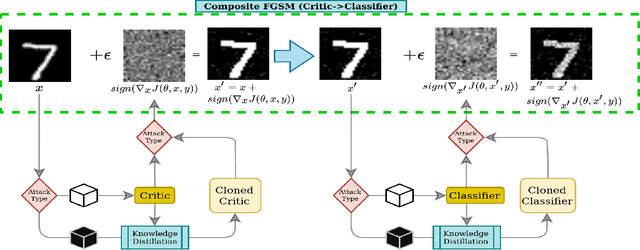

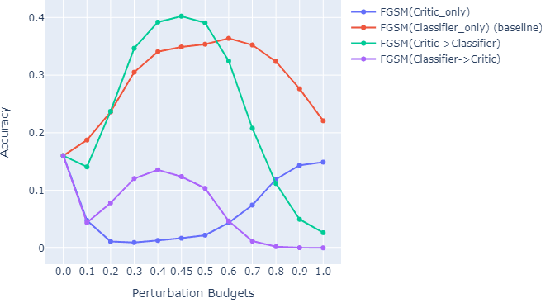
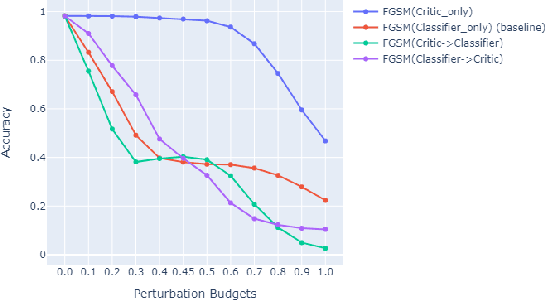
Attacks on machine learning models have been, since their conception, a very persistent and evasive issue resembling an endless cat-and-mouse game. One major variant of such attacks is poisoning attacks which can indirectly manipulate an ML model. It has been observed over the years that the majority of proposed effective defense models are only effective when an attacker is not aware of them being employed. In this paper, we show that the attack-agnostic De-Pois defense is hardly an exception to that rule. In fact, we demonstrate its vulnerability to the simplest White-Box and Black-Box attacks by an attacker that knows the structure of the De-Pois defense model. In essence, the De-Pois defense relies on a critic model that can be used to detect poisoned data before passing it to the target model. In our work, we break this poison-protection layer by replicating the critic model and then performing a composed gradient-sign attack on both the critic and target models simultaneously -- allowing us to bypass the critic firewall to poison the target model.