 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Circuits: Stability Guarantees for Mechanistic Circuits
Feb 26, 2026Understanding how neural networks arrive at their predictions is essential for debugging, auditing, and deployment. Mechanistic interpretability pursues this goal by identifying circuits - minimal subnetworks responsible for specific behaviors. However, existing circuit discovery methods are brittle: circuits depend strongly on the chosen concept dataset and often fail to transfer out-of-distribution, raising doubts whether they capture concept or dataset-specific artifacts. We introduce Certified Circuits, which provide provable stability guarantees for circuit discovery. Our framework wraps any black-box discovery algorithm with randomized data subsampling to certify that circuit component inclusion decisions are invariant to bounded edit-distance perturbations of the concept dataset. Unstable neurons are abstained from, yielding circuits that are more compact and more accurate. On ImageNet and OOD datasets, certified circuits achieve up to 91% higher accuracy while using 45% fewer neurons, and remain reliable where baselines degrade. Certified Circuits puts circuit discovery on formal ground by producing mechanistic explanations that are provably stable and better aligned with the target concept. Code will be released soon!
Pixel-level Certified Explanations via Randomized Smoothing
Jun 18, 2025Post-hoc attribution methods aim to explain deep learning predictions by highlighting influential input pixels. However, these explanations are highly non-robust: small, imperceptible input perturbations can drastically alter the attribution map while maintaining the same prediction. This vulnerability undermines their trustworthiness and calls for rigorous robustness guarantees of pixel-level attribution scores. We introduce the first certification framework that guarantees pixel-level robustness for any black-box attribution method using randomized smoothing. By sparsifying and smoothing attribution maps, we reformulate the task as a segmentation problem and certify each pixel's importance against $\ell_2$-bounded perturbations. We further propose three evaluation metrics to assess certified robustness, localization, and faithfulness. An extensive evaluation of 12 attribution methods across 5 ImageNet models shows that our certified attributions are robust, interpretable, and faithful, enabling reliable use in downstream tasks. Our code is at https://github.com/AlaaAnani/certified-attributions.
Adaptive Hierarchical Certification for Segmentation using Randomized Smoothing
Feb 13, 2024Common certification methods operate on a flat pre-defined set of fine-grained classes. In this paper, however, we propose a novel, more general, and practical setting, namely adaptive hierarchical certification for image semantic segmentation. In this setting, the certification can be within a multi-level hierarchical label space composed of fine to coarse levels. Unlike classic methods where the certification would abstain for unstable components, our approach adaptively relaxes the certification to a coarser level within the hierarchy. This relaxation lowers the abstain rate whilst providing more certified semantically meaningful information. We mathematically formulate the problem setup and introduce, for the first time, an adaptive hierarchical certification algorithm for image semantic segmentation, that certifies image pixels within a hierarchy and prove the correctness of its guarantees. Since certified accuracy does not take the loss of information into account when traversing into a coarser hierarchy level, we introduce a novel evaluation paradigm for adaptive hierarchical certification, namely the certified information gain metric, which is proportional to the class granularity level. Our evaluation experiments on real-world challenging datasets such as Cityscapes and ACDC demonstrate that our adaptive algorithm achieves a higher certified information gain and a lower abstain rate compared to the current state-of-the-art certification method, as well as other non-adaptive versions of it.
Breaking the De-Pois Poisoning Defense
Apr 03, 2022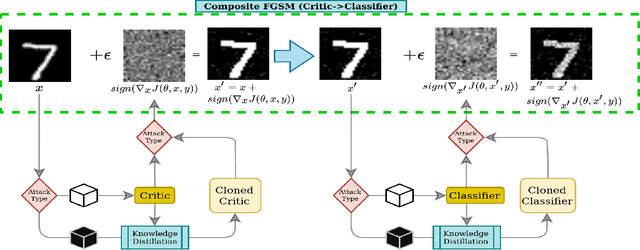

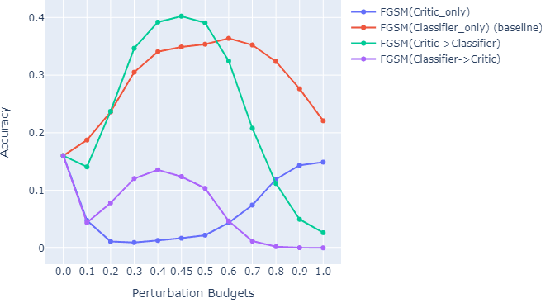
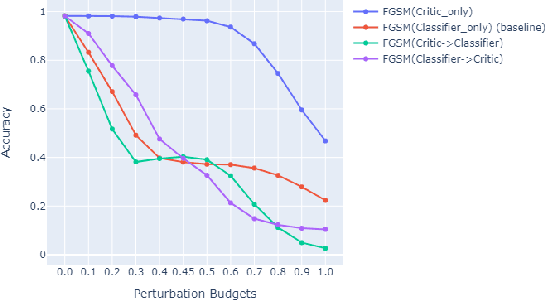
Attacks on machine learning models have been, since their conception, a very persistent and evasive issue resembling an endless cat-and-mouse game. One major variant of such attacks is poisoning attacks which can indirectly manipulate an ML model. It has been observed over the years that the majority of proposed effective defense models are only effective when an attacker is not aware of them being employed. In this paper, we show that the attack-agnostic De-Pois defense is hardly an exception to that rule. In fact, we demonstrate its vulnerability to the simplest White-Box and Black-Box attacks by an attacker that knows the structure of the De-Pois defense model. In essence, the De-Pois defense relies on a critic model that can be used to detect poisoned data before passing it to the target model. In our work, we break this poison-protection layer by replicating the critic model and then performing a composed gradient-sign attack on both the critic and target models simultaneously -- allowing us to bypass the critic firewall to poison the target model.