 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventNeuS: 3D Mesh Reconstruction from a Single Event Camera
Feb 03, 2026Event cameras offer a considerable alternative to RGB cameras in many scenarios. While there are recent works on event-based novel-view synthesis, dense 3D mesh reconstruction remains scarcely explored and existing event-based techniques are severely limited in their 3D reconstruction accuracy. To address this limitation, we present EventNeuS, a self-supervised neural model for learning 3D representations from monocular colour event streams. Our approach, for the first time, combines 3D signed distance function and density field learning with event-based supervision. Furthermore, we introduce spherical harmonics encodings into our model for enhanced handling of view-dependent effects. EventNeuS outperforms existing approaches by a significant margin, achieving 34% lower Chamfer distance and 31% lower mean absolute error on average compared to the best previous method.
* 13 pages, 10 figures, 3 tables; project page: https://4dqv.mpi-inf.mpg.de/EventNeuS/
Dynamic EventNeRF: Reconstructing General Dynamic Scenes from Multi-view Event Cameras
Dec 09, 2024



Volumetric reconstruction of dynamic scenes is an important problem in computer vision. It is especially challenging in poor lighting and with fast motion. It is partly due to the limitations of RGB cameras: To capture fast motion without much blur, the framerate must be increased, which in turn requires more lighting. In contrast, event cameras, which record changes in pixel brightness asynchronously, are much less dependent on lighting, making them more suitable for recording fast motion. We hence propose the first method to spatiotemporally reconstruct a scene from sparse multi-view event streams and sparse RGB frames. We train a sequence of cross-faded time-conditioned NeRF models, one per short recording segment. The individual segments are supervised with a set of event- and RGB-based losses and sparse-view regularisation. We assemble a real-world multi-view camera rig with six static event cameras around the object and record a benchmark multi-view event stream dataset of challenging motions. Our work outperforms RGB-based baselines, producing state-of-the-art results, and opens up the topic of multi-view event-based reconstruction as a new path for fast scene capture beyond RGB cameras. The code and the data will be released soon at https://4dqv.mpi-inf.mpg.de/DynEventNeRF/
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera
Dec 21, 2023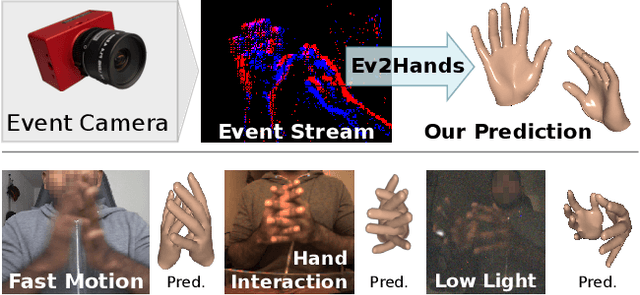

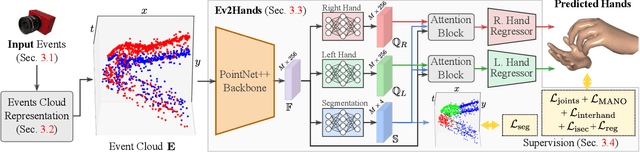

3D hand tracking from a monocular video is a very challenging problem due to hand interactions, occlusions, left-right hand ambiguity, and fast motion. Most existing methods rely on RGB inputs, which have severe limitations under low-light conditions and suffer from motion blur. In contrast, event cameras capture local brightness changes instead of full image frames and do not suffer from the described effects. Unfortunately, existing image-based techniques cannot be directly applied to events due to significant differences in the data modalities. In response to these challenges, this paper introduces the first framework for 3D tracking of two fast-moving and interacting hands from a single monocular event camera. Our approach tackles the left-right hand ambiguity with a novel semi-supervised feature-wise attention mechanism and integrates an intersection loss to fix hand collisions. To facilitate advances in this research domain, we release a new synthetic large-scale dataset of two interacting hands, Ev2Hands-S, and a new real benchmark with real event streams and ground-truth 3D annotations, Ev2Hands-R. Our approach outperforms existing methods in terms of the 3D reconstruction accuracy and generalises to real data under severe light conditions.
* 17 pages, 12 figures, 7 tables; project page: https://4dqv.mpi-inf.mpg.de/Ev2Hands/
EventNeRF: Neural Radiance Fields from a Single Colour Event Camera
Jun 23, 2022
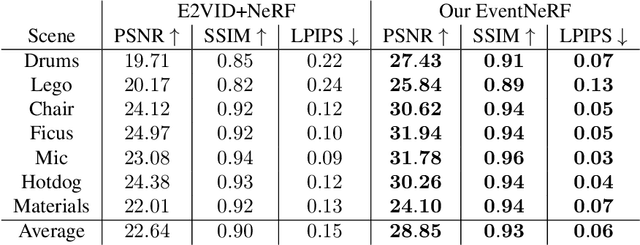

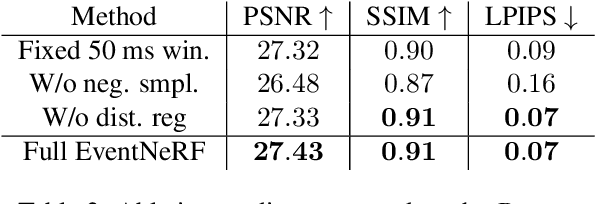
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
Neural Radiance Fields for Outdoor Scene Relighting
Dec 09, 2021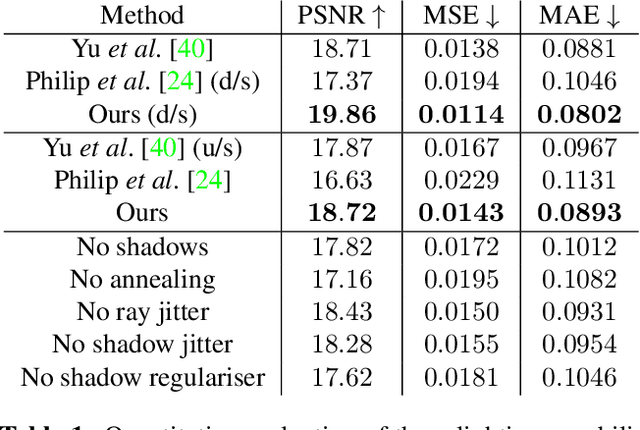
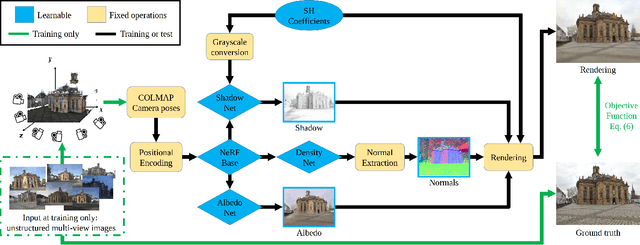
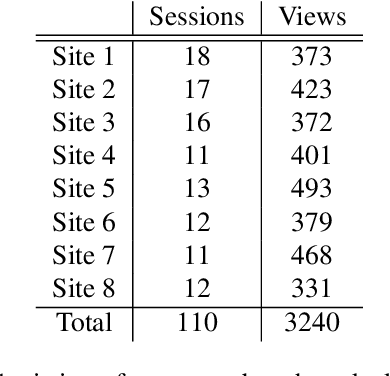

Photorealistic editing of outdoor scenes from photographs requires a profound understanding of the image formation process and an accurate estimation of the scene geometry, reflectance and illumination. A delicate manipulation of the lighting can then be performed while keeping the scene albedo and geometry unaltered. We present NeRF-OSR, i.e., the first approach for outdoor scene relighting based on neural radiance fields. In contrast to the prior art, our technique allows simultaneous editing of both scene illumination and camera viewpoint using only a collection of outdoor photos shot in uncontrolled settings. Moreover, it enables direct control over the scene illumination, as defined through a spherical harmonics model. It also includes a dedicated network for shadow reproduction, which is crucial for high-quality outdoor scene relighting. To evaluate the proposed method, we collect a new benchmark dataset of several outdoor sites, where each site is photographed from multiple viewpoints and at different timings. For each timing, a 360 degrees environment map is captured together with a colour-calibration chequerboard to allow accurate numerical evaluations on real data against ground truth. Comparisons against state of the art show that NeRF-OSR enables controllable lighting and viewpoint editing at higher quality and with realistic self-shadowing reproduction. Our method and the dataset will be made publicly available at https://4dqv.mpi-inf.mpg.de/NeRF-OSR/.
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
Jun 03, 2021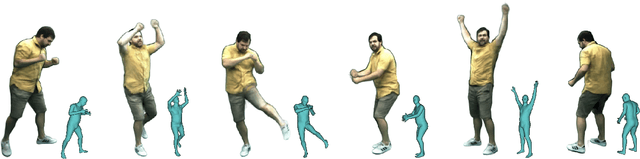
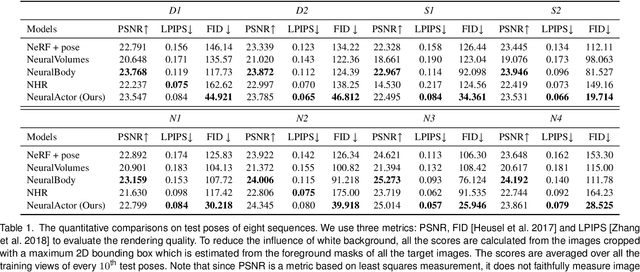
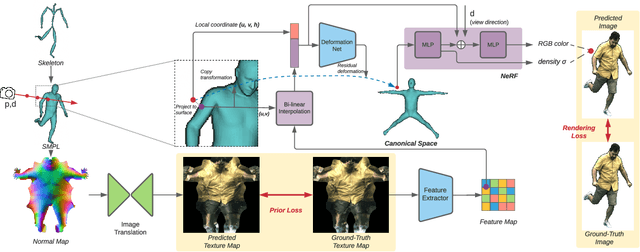
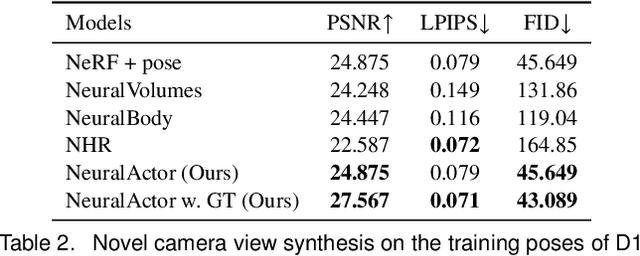
We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, we leverage 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports body shape control of the synthesized results.
EventHands: Real-Time Neural 3D Hand Reconstruction from an Event Stream
Dec 14, 2020
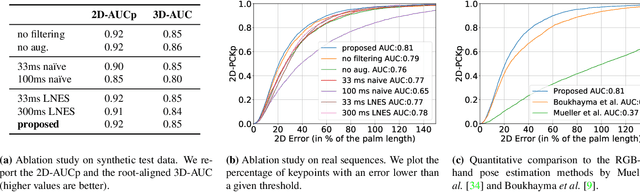


3D hand pose estimation from monocular videos is a long-standing and challenging problem, which is now seeing a strong upturn. In this work, we address it for the first time using a single event camera, i.e., an asynchronous vision sensor reacting on brightness changes. Our EventHands approach has characteristics previously not demonstrated with a single RGB or depth camera such as high temporal resolution at low data throughputs and real-time performance at 1000 Hz. Due to the different data modality of event cameras compared to classical cameras, existing methods cannot be directly applied to and re-trained for event streams. We thus design a new neural approach which accepts a new event stream representation suitable for learning, which is trained on newly-generated synthetic event streams and can generalise to real data. Experiments show that EventHands outperforms recent monocular methods using a colour (or depth) camera in terms of accuracy and its ability to capture hand motions of unprecedented speed. Our method, the event stream simulator and the dataset will be made publicly available.