 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPixie: Unified and Probabilistic 3D Physics Learning via Flow Matching
Jun 03, 2026Existing feed-forward networks excel at predicting a single set of physical properties from visual appearance, but this point-estimate paradigm fundamentally fails to capture the real world's inherent physical ambiguity. We address this by reframing physics prediction as a task of learning a controllable, continuous distribution of material properties. We introduce UNIPIXIE, a framework trained to predict a continuous and parameterized path of physically plausible material properties from a single visual input. By learning a direct mapping along an object's softest-to-stiffest spectrum on our PIXIEMULTIVERSE dataset, UNIPIXIE allows for controllable generation of diverse, physically valid material fields via a single intuitive parameter. Crucially, UNIPIXIE introduces a novel unified architecture to produce simulation-ready parameters for diverse physics solvers, including continuum-based Material Point Method (MPM), reduced-order deformation based on Linear Blend Skinning (LBS), and anchor-based Spring-Mass systems, addressing a key portability issue in prior work. Experiments show our approach not only generates a rich variety of plausible dynamics but also reduces Young's Modulus prediction error by over 50% against the strongest deterministic baseline, bridging the gap between static point estimates and the continuous nature of physical reality. Project page: https://unipixie.github.io/
PointAction: 3D Points as Universal Action Representations for Robot Control
Jun 02, 2026Video-Action Models (VAMs) leverage the broad visual dynamics captured by pre-trained video diffusion models, offering a promising path toward generalizable robot manipulation. However, RGB-only video rollouts are not directly actionable: they leave metric 3D motion, contact geometry, and fine-grained spatial constraints under-specified, making action grounding ambiguous. Meanwhile, scaling action supervision across diverse tasks and embodiments remains costly. We present PointAction, a framework that bridges video predictions to robot actions through explicit point-based 4D modeling. PointAction fine-tunes a foundation video generation model to jointly predict future RGB frames and dynamic 3D pointmaps, producing temporally consistent 3D motion of task-relevant scene geometry. These point dynamics serve as a structured, embodiment-agnostic action interface, which a diffusion-based action decoder maps to executable robot actions. By using metric 3D point dynamics as the interface between video prediction and control, PointAction reduces the ambiguity of RGB-only action grounding and supports transfer across tasks and embodiments with limited action supervision. Experiments show that PointAction achieves state-of-the-art 4D generation quality on robot scenes, outperforms existing baselines in simulation, and generalizes to two real robot arms unseen during pretraining.
Next-Scale Autoregressive Models for Text-to-Motion Generation
Apr 04, 2026Autoregressive (AR) models offer stable and efficient training, but standard next-token prediction is not well aligned with the temporal structure required for text-conditioned motion generation. We introduce MoScale, a next-scale AR framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, we further incorporate cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction. MoScale achieves SOTA text-to-motion performance with high training efficiency, scales effectively with model size, and generalizes zero-shot to diverse motion generation and editing tasks.
OmniGuide: Universal Guidance Fields for Enhancing Generalist Robot Policies
Mar 09, 2026Vision-language-action(VLA) models have shown great promise as generalist policies for a large range of relatively simple tasks. However, they demonstrate limited performance on more complex tasks, such as those requiring complex spatial or semantic understanding, manipulation in clutter, or precise manipulation. We propose OMNIGUIDE, a flexible framework that improves VLA performance on such tasks by leveraging arbitrary sources of guidance, such as 3D foundation models, semantic-reasoning VLMs, and human pose models. We show how many kinds of guidance can be naturally expressed as differentiable energy functions with task-specific attractors and repellers located in 3D space, that influence the sampling of VLA actions. In this way, OMNIGUIDE enables guidance sources with complementary task-relevant strengths to improve a VLA model's performance on challenging tasks. Extensive experiments in both simulation and real-world environments, across diverse sources of guidance, demonstrate that OMNIGUIDE enhances the performance of state-of-the-art generalist policies (e.g., $π_{0.5}$, GR00T N1.6) significantly across success and safety rates. Critically, our unified framework matches or surpasses the performance of prior methods designed to incorporate specific sources of guidance into VLA policies. Project Page: $\href{https://omniguide.github.io/}{this \; url}$
tttLRM: Test-Time Training for Long Context and Autoregressive 3D Reconstruction
Feb 23, 2026We propose tttLRM, a novel large 3D reconstruction model that leverages a Test-Time Training (TTT) layer to enable long-context, autoregressive 3D reconstruction with linear computational complexity, further scaling the model's capability. Our framework efficiently compresses multiple image observations into the fast weights of the TTT layer, forming an implicit 3D representation in the latent space that can be decoded into various explicit formats, such as Gaussian Splats (GS) for downstream applications. The online learning variant of our model supports progressive 3D reconstruction and refinement from streaming observations. We demonstrate that pretraining on novel view synthesis tasks effectively transfers to explicit 3D modeling, resulting in improved reconstruction quality and faster convergence. Extensive experiments show that our method achieves superior performance in feedforward 3D Gaussian reconstruction compared to state-of-the-art approaches on both objects and scenes.
Zero-shot Reconstruction of In-Scene Object Manipulation from Video
Dec 22, 2025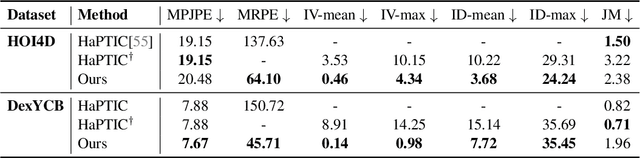
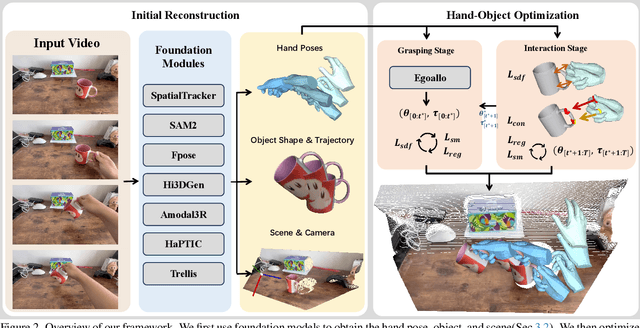
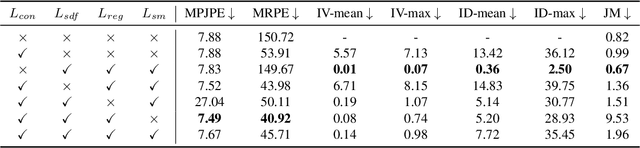
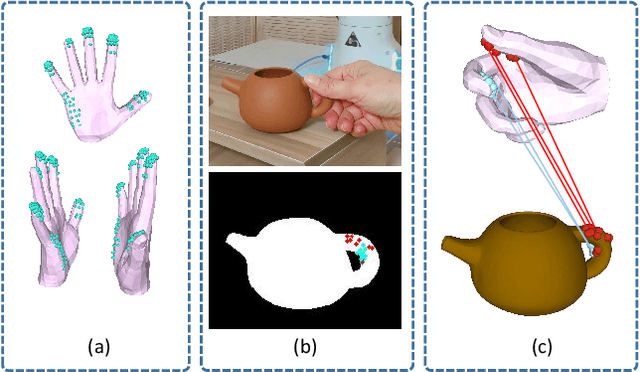
We build the first system to address the problem of reconstructing in-scene object manipulation from a monocular RGB video. It is challenging due to ill-posed scene reconstruction, ambiguous hand-object depth, and the need for physically plausible interactions. Existing methods operate in hand centric coordinates and ignore the scene, hindering metric accuracy and practical use. In our method, we first use data-driven foundation models to initialize the core components, including the object mesh and poses, the scene point cloud, and the hand poses. We then apply a two-stage optimization that recovers a complete hand-object motion from grasping to interaction, which remains consistent with the scene information observed in the input video.
DIMO: Diverse 3D Motion Generation for Arbitrary Objects
Nov 10, 2025
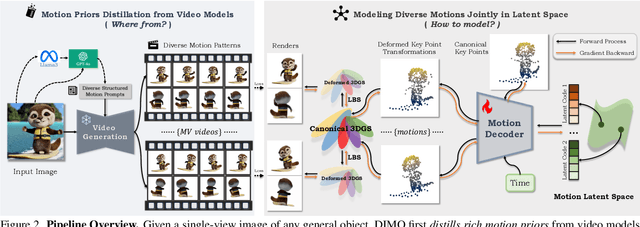
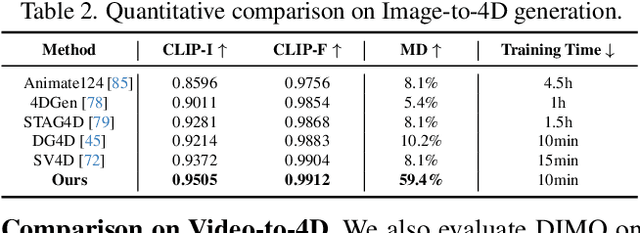

We present DIMO, a generative approach capable of generating diverse 3D motions for arbitrary objects from a single image. The core idea of our work is to leverage the rich priors in well-trained video models to extract the common motion patterns and then embed them into a shared low-dimensional latent space. Specifically, we first generate multiple videos of the same object with diverse motions. We then embed each motion into a latent vector and train a shared motion decoder to learn the distribution of motions represented by a structured and compact motion representation, i.e., neural key point trajectories. The canonical 3D Gaussians are then driven by these key points and fused to model the geometry and appearance. During inference time with learned latent space, we can instantly sample diverse 3D motions in a single-forward pass and support several interesting applications including 3D motion interpolation and language-guided motion generation. Our project page is available at https://linzhanm.github.io/dimo.
FormCoach: Lift Smarter, Not Harder
Aug 10, 2025Good form is the difference between strength and strain, yet for the fast-growing community of at-home fitness enthusiasts, expert feedback is often out of reach. FormCoach transforms a simple camera into an always-on, interactive AI training partner, capable of spotting subtle form errors and delivering tailored corrections in real time, leveraging vision-language models (VLMs). We showcase this capability through a web interface and benchmark state-of-the-art VLMs on a dataset of 1,700 expert-annotated user-reference video pairs spanning 22 strength and mobility exercises. To accelerate research in AI-driven coaching, we release both the dataset and an automated, rubric-based evaluation pipeline, enabling standardized comparison across models. Our benchmarks reveal substantial gaps compared to human-level coaching, underscoring both the challenges and opportunities in integrating nuanced, context-aware movement analysis into interactive AI systems. By framing form correction as a collaborative and creative process between humans and machines, FormCoach opens a new frontier in embodied AI.
StereoDiff: Stereo-Diffusion Synergy for Video Depth Estimation
Jun 25, 2025



Recent video depth estimation methods achieve great performance by following the paradigm of image depth estimation, i.e., typically fine-tuning pre-trained video diffusion models with massive data. However, we argue that video depth estimation is not a naive extension of image depth estimation. The temporal consistency requirements for dynamic and static regions in videos are fundamentally different. Consistent video depth in static regions, typically backgrounds, can be more effectively achieved via stereo matching across all frames, which provides much stronger global 3D cues. While the consistency for dynamic regions still should be learned from large-scale video depth data to ensure smooth transitions, due to the violation of triangulation constraints. Based on these insights, we introduce StereoDiff, a two-stage video depth estimator that synergizes stereo matching for mainly the static areas with video depth diffusion for maintaining consistent depth transitions in dynamic areas. We mathematically demonstrate how stereo matching and video depth diffusion offer complementary strengths through frequency domain analysis, highlighting the effectiveness of their synergy in capturing the advantages of both. Experimental results on zero-shot, real-world, dynamic video depth benchmarks, both indoor and outdoor, demonstrate StereoDiff's SoTA performance, showcasing its superior consistency and accuracy in video depth estimation.
Vid2Sim: Generalizable, Video-based Reconstruction of Appearance, Geometry and Physics for Mesh-free Simulation
Jun 06, 2025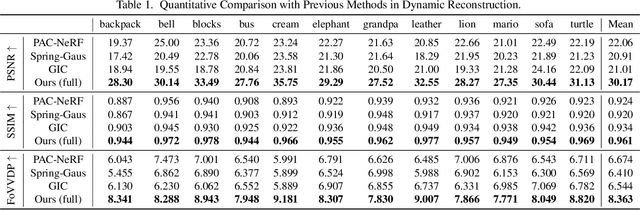
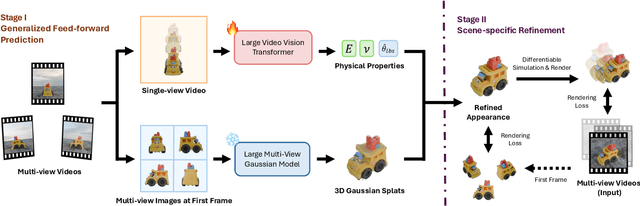
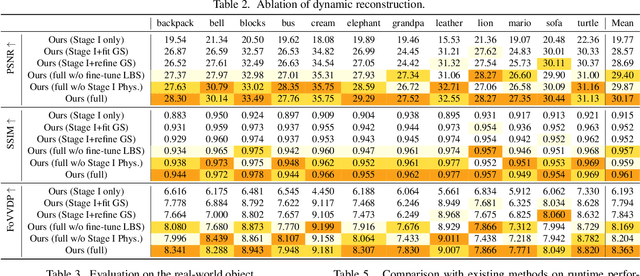

Faithfully reconstructing textured shapes and physical properties from videos presents an intriguing yet challenging problem. Significant efforts have been dedicated to advancing such a system identification problem in this area. Previous methods often rely on heavy optimization pipelines with a differentiable simulator and renderer to estimate physical parameters. However, these approaches frequently necessitate extensive hyperparameter tuning for each scene and involve a costly optimization process, which limits both their practicality and generalizability. In this work, we propose a novel framework, Vid2Sim, a generalizable video-based approach for recovering geometry and physical properties through a mesh-free reduced simulation based on Linear Blend Skinning (LBS), offering high computational efficiency and versatile representation capability. Specifically, Vid2Sim first reconstructs the observed configuration of the physical system from video using a feed-forward neural network trained to capture physical world knowledge. A lightweight optimization pipeline then refines the estimated appearance, geometry, and physical properties to closely align with video observations within just a few minutes. Additionally, after the reconstruction, Vid2Sim enables high-quality, mesh-free simulation with high efficiency. Extensive experiments demonstrate that our method achieves superior accuracy and efficiency in reconstructing geometry and physical properties from video data.