 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Inertial Denoiser (GID): Endowing Accurate Motion Capture via Loose IMU Denoiser
Jan 04, 2026Wearable inertial motion capture (MoCap) provides a portable, occlusion-free, and privacy-preserving alternative to camera-based systems, but its accuracy depends on tightly attached sensors - an intrusive and uncomfortable requirement for daily use. Embedding IMUs into loose-fitting garments is a desirable alternative, yet sensor-body displacement introduces severe, structured, and location-dependent corruption that breaks standard inertial pipelines. We propose GID (Garment Inertial Denoiser), a lightweight, plug-and-play Transformer that factorizes loose-wear MoCap into three stages: (i) location-specific denoising, (ii) adaptive cross-wear fusion, and (iii) general pose prediction. GID uses a location-aware expert architecture, where a shared spatio-temporal backbone models global motion while per-IMU expert heads specialize in local garment dynamics, and a lightweight fusion module ensures cross-part consistency. This inductive bias enables stable training and effective learning from limited paired loose-tight IMU data. We also introduce GarMoCap, a combined public and newly collected dataset covering diverse users, motions, and garments. Experiments show that GID enables accurate, real-time denoising from single-user training and generalizes across unseen users, motions, and garment types, consistently improving state-of-the-art inertial MoCap methods when used as a drop-in module.
Vid2Sim: Generalizable, Video-based Reconstruction of Appearance, Geometry and Physics for Mesh-free Simulation
Jun 06, 2025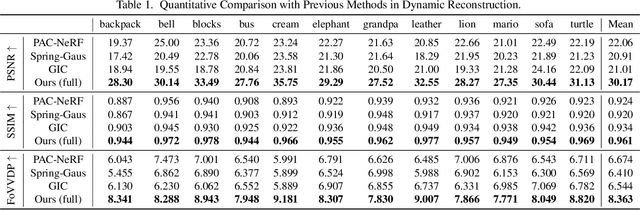
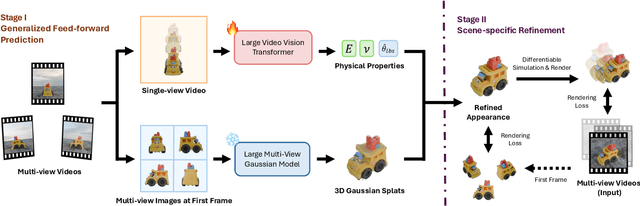
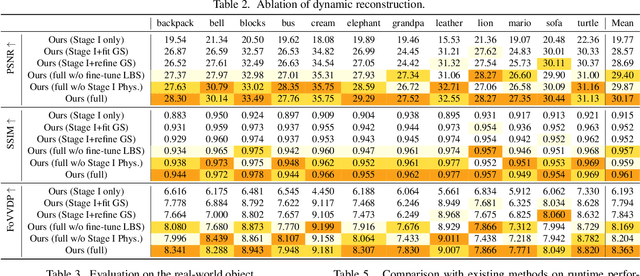

Faithfully reconstructing textured shapes and physical properties from videos presents an intriguing yet challenging problem. Significant efforts have been dedicated to advancing such a system identification problem in this area. Previous methods often rely on heavy optimization pipelines with a differentiable simulator and renderer to estimate physical parameters. However, these approaches frequently necessitate extensive hyperparameter tuning for each scene and involve a costly optimization process, which limits both their practicality and generalizability. In this work, we propose a novel framework, Vid2Sim, a generalizable video-based approach for recovering geometry and physical properties through a mesh-free reduced simulation based on Linear Blend Skinning (LBS), offering high computational efficiency and versatile representation capability. Specifically, Vid2Sim first reconstructs the observed configuration of the physical system from video using a feed-forward neural network trained to capture physical world knowledge. A lightweight optimization pipeline then refines the estimated appearance, geometry, and physical properties to closely align with video observations within just a few minutes. Additionally, after the reconstruction, Vid2Sim enables high-quality, mesh-free simulation with high efficiency. Extensive experiments demonstrate that our method achieves superior accuracy and efficiency in reconstructing geometry and physical properties from video data.
Radar and Camera Fusion for Object Detection and Tracking: A Comprehensive Survey
Oct 24, 2024



Multi-modal fusion is imperative to the implementation of reliable object detection and tracking in complex environments. Exploiting the synergy of heterogeneous modal information endows perception systems the ability to achieve more comprehensive, robust, and accurate performance. As a nucleus concern in wireless-vision collaboration, radar-camera fusion has prompted prospective research directions owing to its extensive applicability, complementarity, and compatibility. Nonetheless, there still lacks a systematic survey specifically focusing on deep fusion of radar and camera for object detection and tracking. To fill this void, we embark on an endeavor to comprehensively review radar-camera fusion in a holistic way. First, we elaborate on the fundamental principles, methodologies, and applications of radar-camera fusion perception. Next, we delve into the key techniques concerning sensor calibration, modal representation, data alignment, and fusion operation. Furthermore, we provide a detailed taxonomy covering the research topics related to object detection and tracking in the context of radar and camera technologies.Finally, we discuss the emerging perspectives in the field of radar-camera fusion perception and highlight the potential areas for future research.
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Sep 07, 2024



Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Apr 19, 2024



The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Oct 04, 2022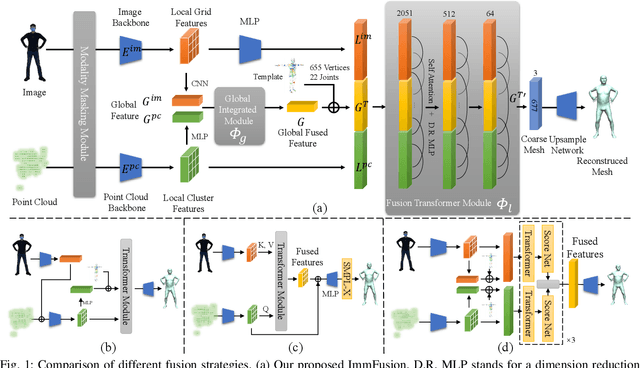
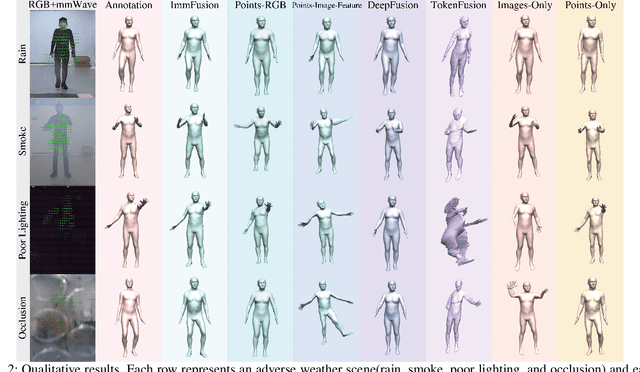

3D human reconstruction from RGB images achieves decent results in good weather conditions but degrades dramatically in rough weather. Complementary, mmWave radars have been employed to reconstruct 3D human joints and meshes in rough weather. However, combining RGB and mmWave signals for robust all-weather 3D human reconstruction is still an open challenge, given the sparse nature of mmWave and the vulnerability of RGB images. In this paper, we present ImmFusion, the first mmWave-RGB fusion solution to reconstruct 3D human bodies in all weather conditions robustly. Specifically, our ImmFusion consists of image and point backbones for token feature extraction and a Transformer module for token fusion. The image and point backbones refine global and local features from original data, and the Fusion Transformer Module aims for effective information fusion of two modalities by dynamically selecting informative tokens. Extensive experiments on a large-scale dataset, mmBody, captured in various environments demonstrate that ImmFusion can efficiently utilize the information of two modalities to achieve a robust 3D human body reconstruction in all weather conditions. In addition, our method's accuracy is significantly superior to that of state-of-the-art Transformer-based LiDAR-camera fusion methods.
mmBody Benchmark: 3D Body Reconstruction Dataset and Analysis for Millimeter Wave Radar
Sep 12, 2022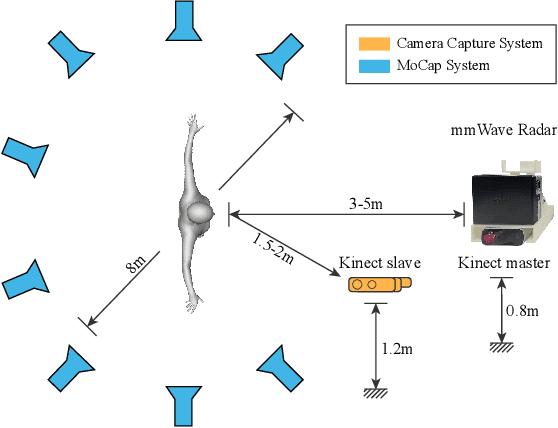
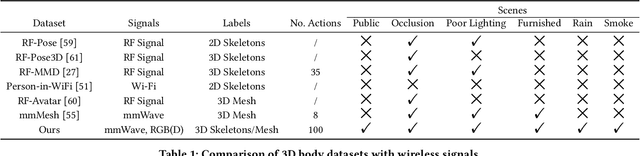
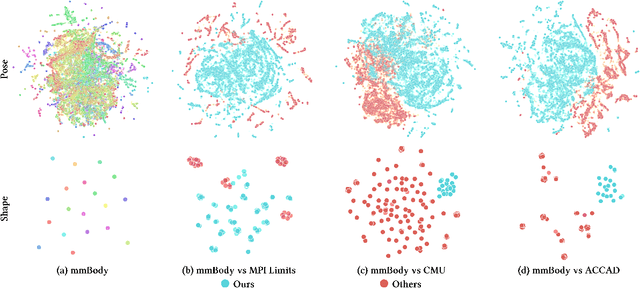

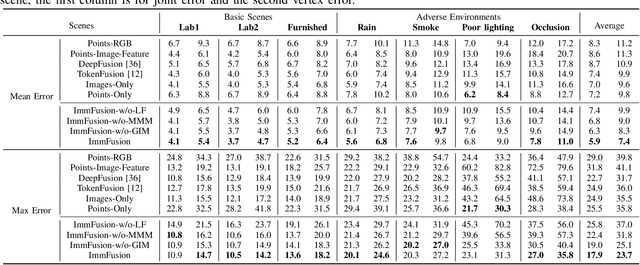
Millimeter Wave (mmWave) Radar is gaining popularity as it can work in adverse environments like smoke, rain, snow, poor lighting, etc. Prior work has explored the possibility of reconstructing 3D skeletons or meshes from the noisy and sparse mmWave Radar signals. However, it is unclear how accurately we can reconstruct the 3D body from the mmWave signals across scenes and how it performs compared with cameras, which are important aspects needed to be considered when either using mmWave radars alone or combining them with cameras. To answer these questions, an automatic 3D body annotation system is first designed and built up with multiple sensors to collect a large-scale dataset. The dataset consists of synchronized and calibrated mmWave radar point clouds and RGB(D) images in different scenes and skeleton/mesh annotations for humans in the scenes. With this dataset, we train state-of-the-art methods with inputs from different sensors and test them in various scenarios. The results demonstrate that 1) despite the noise and sparsity of the generated point clouds, the mmWave radar can achieve better reconstruction accuracy than the RGB camera but worse than the depth camera; 2) the reconstruction from the mmWave radar is affected by adverse weather conditions moderately while the RGB(D) camera is severely affected. Further, analysis of the dataset and the results shadow insights on improving the reconstruction from the mmWave radar and the combination of signals from different sensors.