 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retail Video Annotation: A Robust Key Frame Generation Approach for Product and Customer Interaction Analysis
Jun 17, 2025Accurate video annotation plays a vital role in modern retail applications, including customer behavior analysis, product interaction detection, and in-store activity recognition. However, conventional annotation methods heavily rely on time-consuming manual labeling by human annotators, introducing non-robust frame selection and increasing operational costs. To address these challenges in the retail domain, we propose a deep learning-based approach that automates key-frame identification in retail videos and provides automatic annotations of products and customers. Our method leverages deep neural networks to learn discriminative features by embedding video frames and incorporating object detection-based techniques tailored for retail environments. Experimental results showcase the superiority of our approach over traditional methods, achieving accuracy comparable to human annotator labeling while enhancing the overall efficiency of retail video annotation. Remarkably, our approach leads to an average of 2 times cost savings in video annotation. By allowing human annotators to verify/adjust less than 5% of detected frames in the video dataset, while automating the annotation process for the remaining frames without reducing annotation quality, retailers can significantly reduce operational costs. The automation of key-frame detection enables substantial time and effort savings in retail video labeling tasks, proving highly valuable for diverse retail applications such as shopper journey analysis, product interaction detection, and in-store security monitoring.
DA-STGCN: 4D Trajectory Prediction Based on Spatiotemporal Feature Extraction
Mar 05, 2025The importance of four-dimensional (4D) trajectory prediction within air traffic management systems is on the rise. Key operations such as conflict detection and resolution, aircraft anomaly monitoring, and the management of congested flight paths are increasingly reliant on this foundational technology, underscoring the urgent demand for intelligent solutions. The dynamics in airport terminal zones and crowded airspaces are intricate and ever-changing; however, current methodologies do not sufficiently account for the interactions among aircraft. To tackle these challenges, we propose DA-STGCN, an innovative spatiotemporal graph convolutional network that integrates a dual attention mechanism. Our model reconstructs the adjacency matrix through a self-attention approach, enhancing the capture of node correlations, and employs graph attention to distill spatiotemporal characteristics, thereby generating a probabilistic distribution of predicted trajectories. This novel adjacency matrix, reconstructed with the self-attention mechanism, is dynamically optimized throughout the network's training process, offering a more nuanced reflection of the inter-node relationships compared to traditional algorithms. The performance of the model is validated on two ADS-B datasets, one near the airport terminal area and the other in dense airspace. Experimental results demonstrate a notable improvement over current 4D trajectory prediction methods, achieving a 20% and 30% reduction in the Average Displacement Error (ADE) and Final Displacement Error (FDE), respectively. The incorporation of a Dual-Attention module has been shown to significantly enhance the extraction of node correlations, as verified by ablation experiments.
Radar and Camera Fusion for Object Detection and Tracking: A Comprehensive Survey
Oct 24, 2024



Multi-modal fusion is imperative to the implementation of reliable object detection and tracking in complex environments. Exploiting the synergy of heterogeneous modal information endows perception systems the ability to achieve more comprehensive, robust, and accurate performance. As a nucleus concern in wireless-vision collaboration, radar-camera fusion has prompted prospective research directions owing to its extensive applicability, complementarity, and compatibility. Nonetheless, there still lacks a systematic survey specifically focusing on deep fusion of radar and camera for object detection and tracking. To fill this void, we embark on an endeavor to comprehensively review radar-camera fusion in a holistic way. First, we elaborate on the fundamental principles, methodologies, and applications of radar-camera fusion perception. Next, we delve into the key techniques concerning sensor calibration, modal representation, data alignment, and fusion operation. Furthermore, we provide a detailed taxonomy covering the research topics related to object detection and tracking in the context of radar and camera technologies.Finally, we discuss the emerging perspectives in the field of radar-camera fusion perception and highlight the potential areas for future research.
APAM: Adaptive Pre-training and Adaptive Meta Learning in Language Model for Noisy Labels and Long-tailed Learning
Feb 06, 2023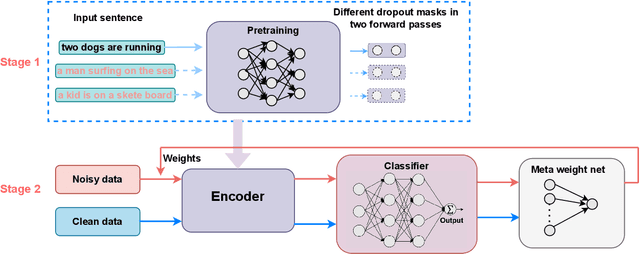



Practical natural language processing (NLP) tasks are commonly long-tailed with noisy labels. Those problems challenge the generalization and robustness of complex models such as Deep Neural Networks (DNNs). Some commonly used resampling techniques, such as oversampling or undersampling, could easily lead to overfitting. It is growing popular to learn the data weights leveraging a small amount of metadata. Besides, recent studies have shown the advantages of self-supervised pre-training, particularly to the under-represented data. In this work, we propose a general framework to handle the problem of both long-tail and noisy labels. The model is adapted to the domain of problems in a contrastive learning manner. The re-weighting module is a feed-forward network that learns explicit weighting functions and adapts weights according to metadata. The framework further adapts weights of terms in the loss function through a combination of the polynomial expansion of cross-entropy loss and focal loss. Our extensive experiments show that the proposed framework consistently outperforms baseline methods. Lastly, our sensitive analysis emphasizes the capability of the proposed framework to handle the long-tailed problem and mitigate the negative impact of noisy labels.
Inducing Cooperation via Team Regret Minimization based Multi-Agent Deep Reinforcement Learning
Nov 18, 2019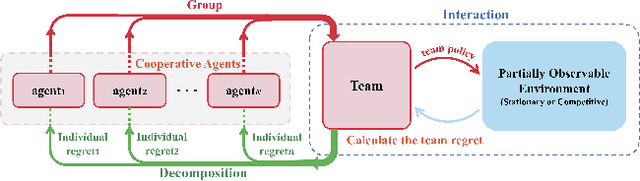
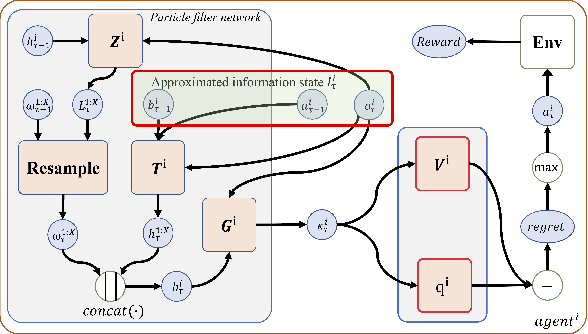
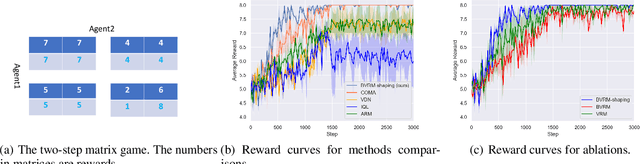
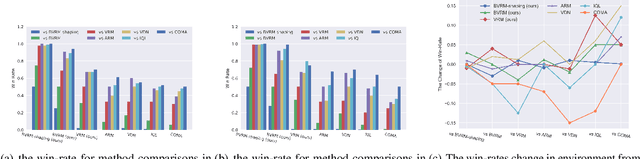
Existing value-factorized based Multi-Agent deep Reinforce-ment Learning (MARL) approaches are well-performing invarious multi-agent cooperative environment under thecen-tralized training and decentralized execution(CTDE) scheme,where all agents are trained together by the centralized valuenetwork and each agent execute its policy independently. How-ever, an issue remains open: in the centralized training process,when the environment for the team is partially observable ornon-stationary, i.e., the observation and action informationof all the agents cannot represent the global states, existingmethods perform poorly and sample inefficiently. Regret Min-imization (RM) can be a promising approach as it performswell in partially observable and fully competitive settings.However, it tends to model others as opponents and thus can-not work well under the CTDE scheme. In this work, wepropose a novel team RM based Bayesian MARL with threekey contributions: (a) we design a novel RM method to traincooperative agents as a team and obtain a team regret-basedpolicy for that team; (b) we introduce a novel method to de-compose the team regret to generate the policy for each agentfor decentralized execution; (c) to further improve the perfor-mance, we leverage a differential particle filter (a SequentialMonte Carlo method) network to get an accurate estimation ofthe state for each agent. Experimental results on two-step ma-trix games (cooperative game) and battle games (large-scalemixed cooperative-competitive games) demonstrate that ouralgorithm significantly outperforms state-of-the-art methods.