 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Evolution Under Zeroth-Order Optimization: A Neural Tangent Kernel Perspective
Mar 22, 2026Zeroth-order (ZO) optimization enables memory-efficient training of neural networks by estimating gradients via forward passes only, eliminating the need for backpropagation. However, the stochastic nature of gradient estimation significantly obscures the training dynamics, in contrast to the well-characterized behavior of first-order methods under Neural Tangent Kernel (NTK) theory. To address this, we introduce the Neural Zeroth-order Kernel (NZK) to describe model evolution in function space under ZO updates. For linear models, we prove that the expected NZK remains constant throughout training and depends explicitly on the first and second moments of the random perturbation directions. This invariance yields a closed-form expression for model evolution under squared loss. We further extend the analysis to linearized neural networks. Interpreting ZO updates as kernel gradient descent via NZK provides a novel perspective for potentially accelerating convergence. Extensive experiments across synthetic and real-world datasets (including MNIST, CIFAR-10, and Tiny ImageNet) validate our theoretical results and demonstrate acceleration when using a single shared random vector.
How Much Information Can a Vision Token Hold? A Scaling Law for Recognition Limits in VLMs
Jan 28, 2026Recent vision-centric approaches have made significant strides in long-context modeling. Represented by DeepSeek-OCR, these models encode rendered text into continuous vision tokens, achieving high compression rates without sacrificing recognition precision. However, viewing the vision encoder as a lossy channel with finite representational capacity raises a fundamental question: what is the information upper bound of visual tokens? To investigate this limit, we conduct controlled stress tests by progressively increasing the information quantity (character count) within an image. We observe a distinct phase-transition phenomenon characterized by three regimes: a near-perfect Stable Phase, an Instability Phase marked by increased error variance, and a total Collapse Phase. We analyze the mechanical origins of these transitions and identify key factors. Furthermore, we formulate a probabilistic scaling law that unifies average vision token load and visual density into a latent difficulty metric. Extensive experiments across various Vision-Language Models demonstrate the universality of this scaling law, providing critical empirical guidance for optimizing the efficiency-accuracy trade-off in visual context compression.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
Tailed Low-Rank Matrix Factorization for Similarity Matrix Completion
Sep 29, 2024



Similarity matrix serves as a fundamental tool at the core of numerous downstream machine-learning tasks. However, missing data is inevitable and often results in an inaccurate similarity matrix. To address this issue, Similarity Matrix Completion (SMC) methods have been proposed, but they suffer from high computation complexity due to the Singular Value Decomposition (SVD) operation. To reduce the computation complexity, Matrix Factorization (MF) techniques are more explicit and frequently applied to provide a low-rank solution, but the exact low-rank optimal solution can not be guaranteed since it suffers from a non-convex structure. In this paper, we introduce a novel SMC framework that offers a more reliable and efficient solution. Specifically, beyond simply utilizing the unique Positive Semi-definiteness (PSD) property to guide the completion process, our approach further complements a carefully designed rank-minimization regularizer, aiming to achieve an optimal and low-rank solution. Based on the key insights that the underlying PSD property and Low-Rank property improve the SMC performance, we present two novel, scalable, and effective algorithms, SMCNN and SMCNmF, which investigate the PSD property to guide the estimation process and incorporate nonconvex low-rank regularizer to ensure the low-rank solution. Theoretical analysis ensures better estimation performance and convergence speed. Empirical results on real-world datasets demonstrate the superiority and efficiency of our proposed methods compared to various baseline methods.
Direct Alignment of Language Models via Quality-Aware Self-Refinement
May 31, 2024
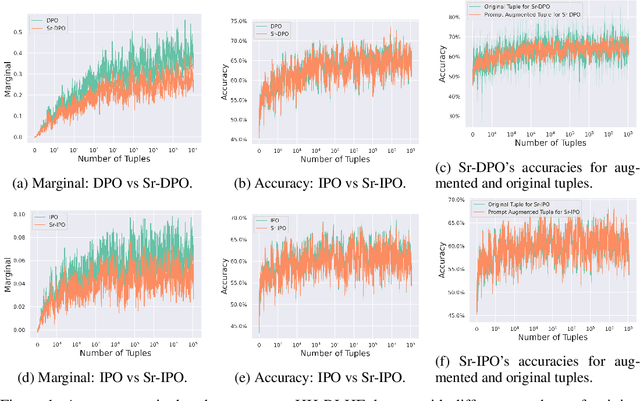
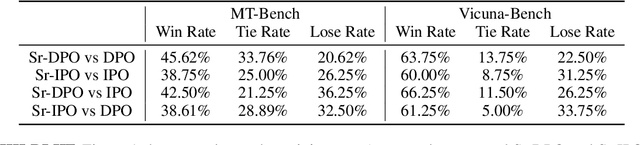
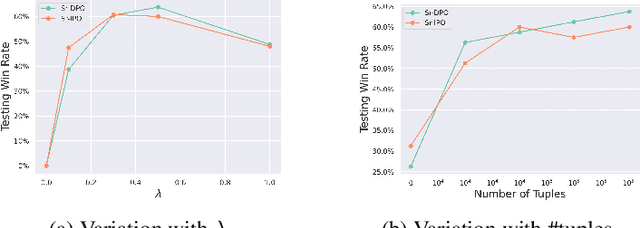
Reinforcement Learning from Human Feedback (RLHF) has been commonly used to align the behaviors of Large Language Models (LLMs) with human preferences. Recently, a popular alternative is Direct Policy Optimization (DPO), which replaces an LLM-based reward model with the policy itself, thus obviating the need for extra memory and training time to learn the reward model. However, DPO does not consider the relative qualities of the positive and negative responses, and can lead to sub-optimal training outcomes. To alleviate this problem, we investigate the use of intrinsic knowledge within the on-the-fly fine-tuning LLM to obtain relative qualities and help to refine the loss function. Specifically, we leverage the knowledge of the LLM to design a refinement function to estimate the quality of both the positive and negative responses. We show that the constructed refinement function can help self-refine the loss function under mild assumptions. The refinement function is integrated into DPO and its variant Identity Policy Optimization (IPO). Experiments across various evaluators indicate that they can improve the performance of the fine-tuned models over DPO and IPO.
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Dec 15, 2021

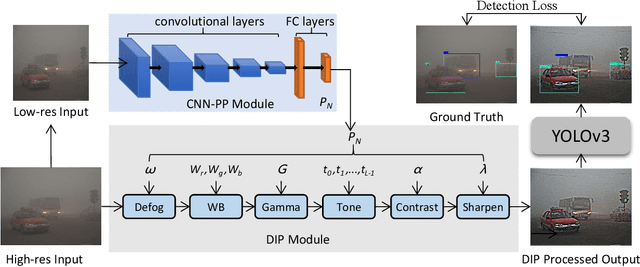
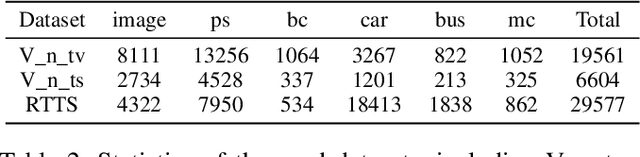
Though deep learning-based object detection methods have achieved promising results on the conventional datasets, it is still challenging to locate objects from the low-quality images captured in adverse weather conditions. The existing methods either have difficulties in balancing the tasks of image enhancement and object detection, or often ignore the latent information beneficial for detection. To alleviate this problem, we propose a novel Image-Adaptive YOLO (IA-YOLO) framework, where each image can be adaptively enhanced for better detection performance. Specifically, a differentiable image processing (DIP) module is presented to take into account the adverse weather conditions for YOLO detector, whose parameters are predicted by a small convolutional neural net-work (CNN-PP). We learn CNN-PP and YOLOv3 jointly in an end-to-end fashion, which ensures that CNN-PP can learn an appropriate DIP to enhance the image for detection in a weakly supervised manner. Our proposed IA-YOLO approach can adaptively process images in both normal and adverse weather conditions. The experimental results are very encouraging, demonstrating the effectiveness of our proposed IA-YOLO method in both foggy and low-light scenarios.
DO-GAN: A Double Oracle Framework for Generative Adversarial Networks
Feb 17, 2021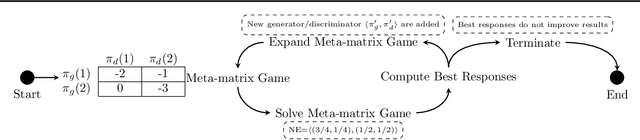
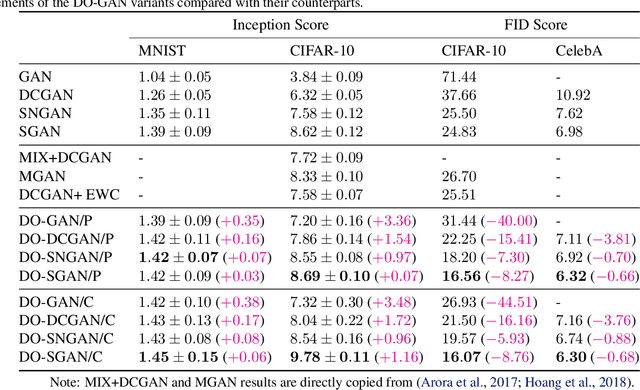

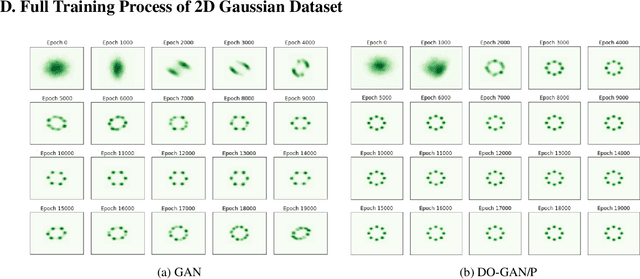
In this paper, we propose a new approach to train Generative Adversarial Networks (GANs) where we deploy a double-oracle framework using the generator and discriminator oracles. GAN is essentially a two-player zero-sum game between the generator and the discriminator. Training GANs is challenging as a pure Nash equilibrium may not exist and even finding the mixed Nash equilibrium is difficult as GANs have a large-scale strategy space. In DO-GAN, we extend the double oracle framework to GANs. We first generalize the players' strategies as the trained models of generator and discriminator from the best response oracles. We then compute the meta-strategies using a linear program. For scalability of the framework where multiple generators and discriminator best responses are stored in the memory, we propose two solutions: 1) pruning the weakly-dominated players' strategies to keep the oracles from becoming intractable; 2) applying continual learning to retain the previous knowledge of the networks. We apply our framework to established GAN architectures such as vanilla GAN, Deep Convolutional GAN, Spectral Normalization GAN and Stacked GAN. Finally, we conduct experiments on MNIST, CIFAR-10 and CelebA datasets and show that DO-GAN variants have significant improvements in both subjective qualitative evaluation and quantitative metrics, compared with their respective GAN architectures.
RMIX: Learning Risk-Sensitive Policies for Cooperative Reinforcement Learning Agents
Feb 17, 2021
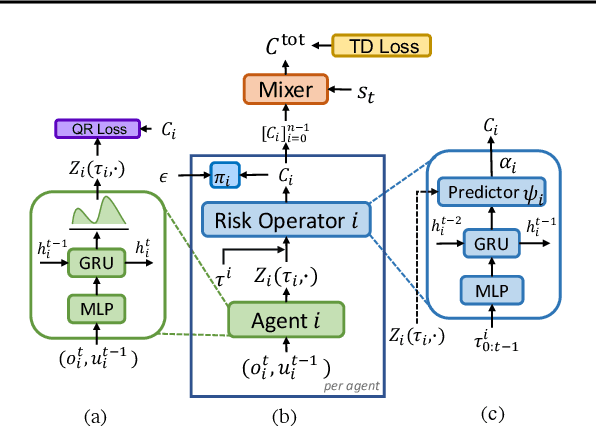
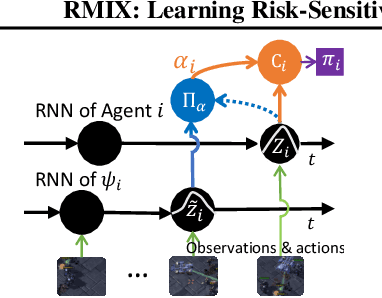
Current value-based multi-agent reinforcement learning methods optimize individual Q values to guide individuals' behaviours via centralized training with decentralized execution (CTDE). However, such expected, i.e., risk-neutral, Q value is not sufficient even with CTDE due to the randomness of rewards and the uncertainty in environments, which causes the failure of these methods to train coordinating agents in complex environments. To address these issues, we propose RMIX, a novel cooperative MARL method with the Conditional Value at Risk (CVaR) measure over the learned distributions of individuals' Q values. Specifically, we first learn the return distributions of individuals to analytically calculate CVaR for decentralized execution. Then, to handle the temporal nature of the stochastic outcomes during executions, we propose a dynamic risk level predictor for risk level tuning. Finally, we optimize the CVaR policies with CVaR values used to estimate the target in TD error during centralized training and the CVaR values are used as auxiliary local rewards to update the local distribution via Quantile Regression loss. Empirically, we show that our method significantly outperforms state-of-the-art methods on challenging StarCraft II tasks, demonstrating enhanced coordination and improved sample efficiency.
Personalized Adaptive Meta Learning for Cold-start User Preference Prediction
Dec 22, 2020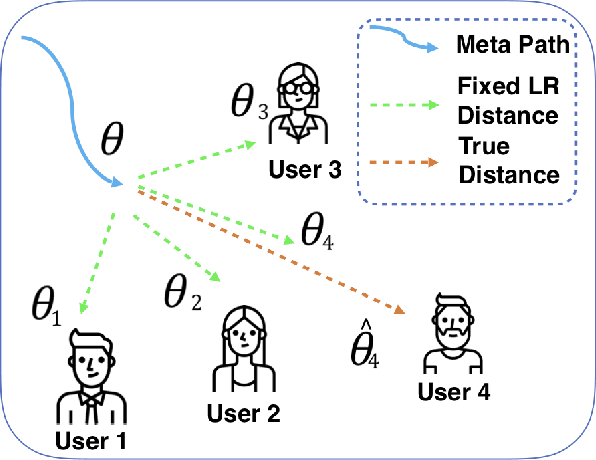
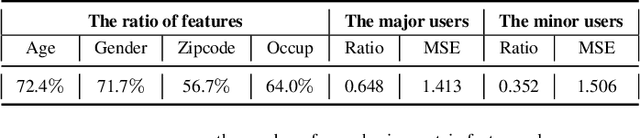
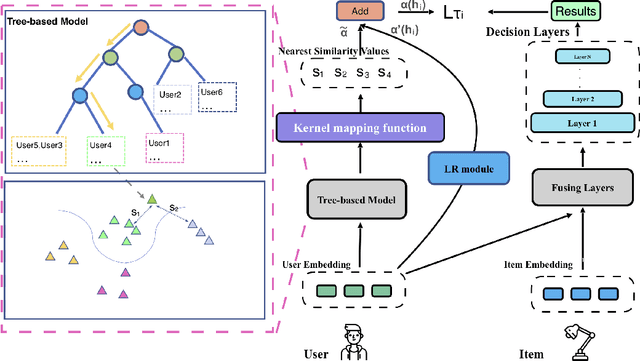

A common challenge in personalized user preference prediction is the cold-start problem. Due to the lack of user-item interactions, directly learning from the new users' log data causes serious over-fitting problem. Recently, many existing studies regard the cold-start personalized preference prediction as a few-shot learning problem, where each user is the task and recommended items are the classes, and the gradient-based meta learning method (MAML) is leveraged to address this challenge. However, in real-world application, the users are not uniformly distributed (i.e., different users may have different browsing history, recommended items, and user profiles. We define the major users as the users in the groups with large numbers of users sharing similar user information, and other users are the minor users), existing MAML approaches tend to fit the major users and ignore the minor users. To address this cold-start task-overfitting problem, we propose a novel personalized adaptive meta learning approach to consider both the major and the minor users with three key contributions: 1) We are the first to present a personalized adaptive learning rate meta-learning approach to improve the performance of MAML by focusing on both the major and minor users. 2) To provide better personalized learning rates for each user, we introduce a similarity-based method to find similar users as a reference and a tree-based method to store users' features for fast search. 3) To reduce the memory usage, we design a memory agnostic regularizer to further reduce the space complexity to constant while maintain the performance. Experiments on MovieLens, BookCrossing, and real-world production datasets reveal that our method outperforms the state-of-the-art methods dramatically for both the minor and major users.
Learning to Collaborate in Multi-Module Recommendation via Multi-Agent Reinforcement Learning without Communication
Aug 29, 2020
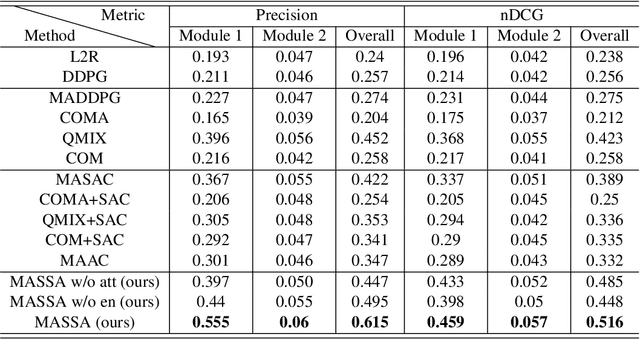
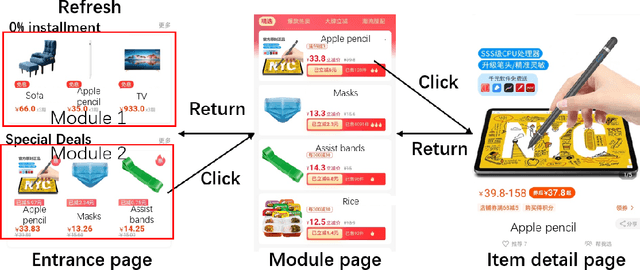
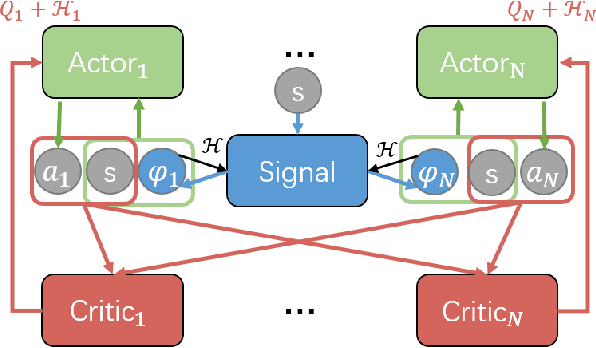
With the rise of online e-commerce platforms, more and more customers prefer to shop online. To sell more products, online platforms introduce various modules to recommend items with different properties such as huge discounts. A web page often consists of different independent modules. The ranking policies of these modules are decided by different teams and optimized individually without cooperation, which might result in competition between modules. Thus, the global policy of the whole page could be sub-optimal. In this paper, we propose a novel multi-agent cooperative reinforcement learning approach with the restriction that different modules cannot communicate. Our contributions are three-fold. Firstly, inspired by a solution concept in game theory named correlated equilibrium, we design a signal network to promote cooperation of all modules by generating signals (vectors) for different modules. Secondly, an entropy-regularized version of the signal network is proposed to coordinate agents' exploration of the optimal global policy. Furthermore, experiments based on real-world e-commerce data demonstrate that our algorithm obtains superior performance over baselines.