 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Alignment of Language Models via Quality-Aware Self-Refinement
Paper and Code
May 31, 2024
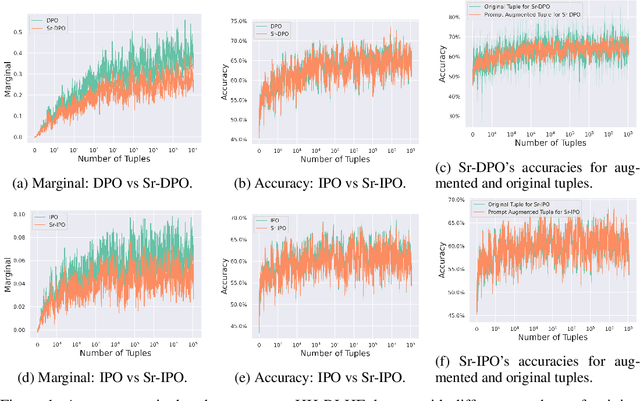
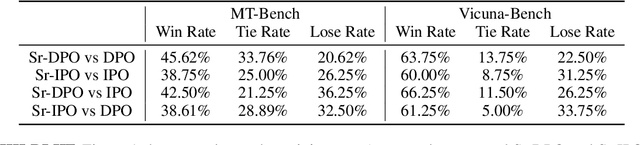
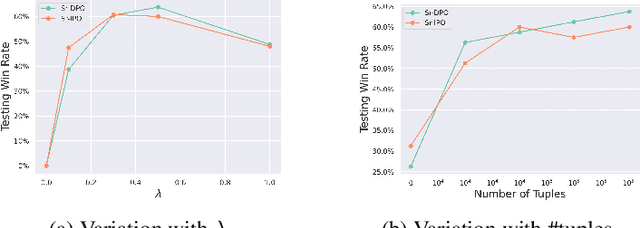
Reinforcement Learning from Human Feedback (RLHF) has been commonly used to align the behaviors of Large Language Models (LLMs) with human preferences. Recently, a popular alternative is Direct Policy Optimization (DPO), which replaces an LLM-based reward model with the policy itself, thus obviating the need for extra memory and training time to learn the reward model. However, DPO does not consider the relative qualities of the positive and negative responses, and can lead to sub-optimal training outcomes. To alleviate this problem, we investigate the use of intrinsic knowledge within the on-the-fly fine-tuning LLM to obtain relative qualities and help to refine the loss function. Specifically, we leverage the knowledge of the LLM to design a refinement function to estimate the quality of both the positive and negative responses. We show that the constructed refinement function can help self-refine the loss function under mild assumptions. The refinement function is integrated into DPO and its variant Identity Policy Optimization (IPO). Experiments across various evaluators indicate that they can improve the performance of the fine-tuned models over DPO and IPO.