 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifying Proportionality in Temporal Voting
Feb 09, 2025We study a model of temporal voting where there is a fixed time horizon, and at each round the voters report their preferences over the available candidates and a single candidate is selected. Prior work has adapted popular notions of justified representation as well as voting rules that provide strong representation guarantees from the multiwinner election setting to this model. In our work, we focus on the complexity of verifying whether a given outcome offers proportional representation. We show that in the temporal setting verification is strictly harder than in multiwinner voting, but identify natural special cases that enable efficient algorithms.
Temporal Fairness in Multiwinner Voting
Dec 09, 2023Multiwinner voting captures a wide variety of settings, from parliamentary elections in democratic systems to product placement in online shopping platforms. There is a large body of work dealing with axiomatic characterizations, computational complexity, and algorithmic analysis of multiwinner voting rules. Although many challenges remain, significant progress has been made in showing existence of fair and representative outcomes as well as efficient algorithmic solutions for many commonly studied settings. However, much of this work focuses on single-shot elections, even though in numerous real-world settings elections are held periodically and repeatedly. Hence, it is imperative to extend the study of multiwinner voting to temporal settings. Recently, there have been several efforts to address this challenge. However, these works are difficult to compare, as they model multi-period voting in very different ways. We propose a unified framework for studying temporal fairness in this domain, drawing connections with various existing bodies of work, and consolidating them within a general framework. We also identify gaps in existing literature, outline multiple opportunities for future work, and put forward a vision for the future of multiwinner voting in temporal settings.
RPM: Generalizable Behaviors for Multi-Agent Reinforcement Learning
Oct 18, 2022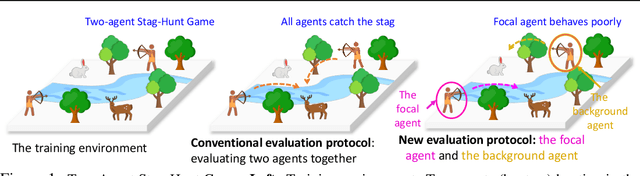
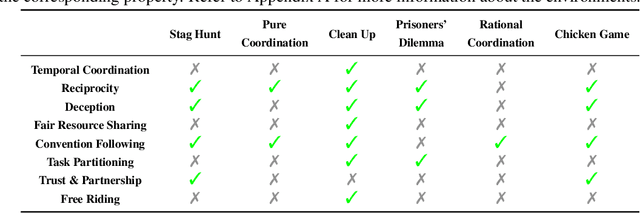


Despite the recent advancement in multi-agent reinforcement learning (MARL), the MARL agents easily overfit the training environment and perform poorly in the evaluation scenarios where other agents behave differently. Obtaining generalizable policies for MARL agents is thus necessary but challenging mainly due to complex multi-agent interactions. In this work, we model the problem with Markov Games and propose a simple yet effective method, ranked policy memory (RPM), to collect diverse multi-agent trajectories for training MARL policies with good generalizability. The main idea of RPM is to maintain a look-up memory of policies. In particular, we try to acquire various levels of behaviors by saving policies via ranking the training episode return, i.e., the episode return of agents in the training environment; when an episode starts, the learning agent can then choose a policy from the RPM as the behavior policy. This innovative self-play training framework leverages agents' past policies and guarantees the diversity of multi-agent interaction in the training data. We implement RPM on top of MARL algorithms and conduct extensive experiments on Melting Pot. It has been demonstrated that RPM enables MARL agents to interact with unseen agents in multi-agent generalization evaluation scenarios and complete given tasks, and it significantly boosts the performance up to 402% on average.
Off-Beat Multi-Agent Reinforcement Learning
May 27, 2022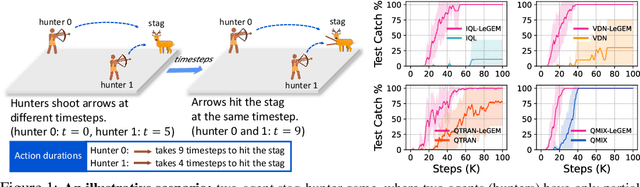
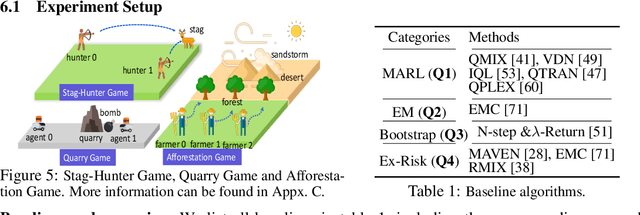

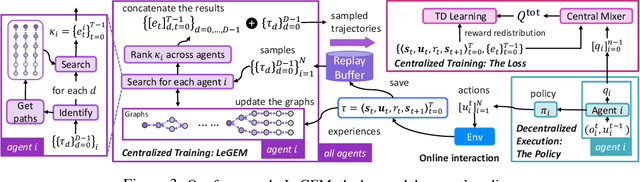
We investigate model-free multi-agent reinforcement learning (MARL) in environments where off-beat actions are prevalent, i.e., all actions have pre-set execution durations. During execution durations, the environment changes are influenced by, but not synchronised with, action execution. Such a setting is ubiquitous in many real-world problems. However, most MARL methods assume actions are executed immediately after inference, which is often unrealistic and can lead to catastrophic failure for multi-agent coordination with off-beat actions. In order to fill this gap, we develop an algorithmic framework for MARL with off-beat actions. We then propose a novel episodic memory, LeGEM, for model-free MARL algorithms. LeGEM builds agents' episodic memories by utilizing agents' individual experiences. It boosts multi-agent learning by addressing the challenging temporal credit assignment problem raised by the off-beat actions via our novel reward redistribution scheme, alleviating the issue of non-Markovian reward. We evaluate LeGEM on various multi-agent scenarios with off-beat actions, including Stag-Hunter Game, Quarry Game, Afforestation Game, and StarCraft II micromanagement tasks. Empirical results show that LeGEM significantly boosts multi-agent coordination and achieves leading performance and improved sample efficiency.
Mis-spoke or mis-lead: Achieving Robustness in Multi-Agent Communicative Reinforcement Learning
Aug 09, 2021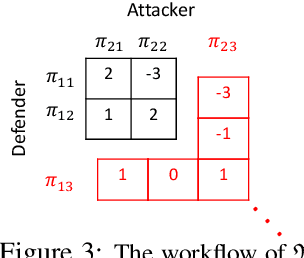
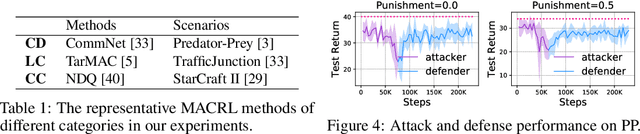
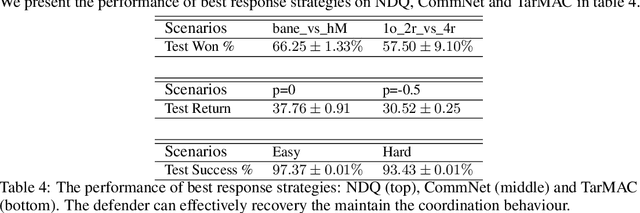

Recent studies in multi-agent communicative reinforcement learning (MACRL) demonstrate that multi-agent coordination can be significantly improved when communication between agents is allowed. Meanwhile, advances in adversarial machine learning (ML) have shown that ML and reinforcement learning (RL) models are vulnerable to a variety of attacks that significantly degrade the performance of learned behaviours. However, despite the obvious and growing importance, the combination of adversarial ML and MACRL remains largely uninvestigated. In this paper, we make the first step towards conducting message attacks on MACRL methods. In our formulation, one agent in the cooperating group is taken over by an adversary and can send malicious messages to disrupt a deployed MACRL-based coordinated strategy during the deployment phase. We further our study by developing a defence method via message reconstruction. Finally, we address the resulting arms race, i.e., we consider the ability of the malicious agent to adapt to the changing and improving defensive communicative policies of the benign agents. Specifically, we model the adversarial MACRL problem as a two-player zero-sum game and then utilize Policy-Space Response Oracle to achieve communication robustness. Empirically, we demonstrate that MACRL methods are vulnerable to message attacks while our defence method the game-theoretic framework can effectively improve the robustness of MACRL.
RMIX: Learning Risk-Sensitive Policies for Cooperative Reinforcement Learning Agents
Feb 17, 2021
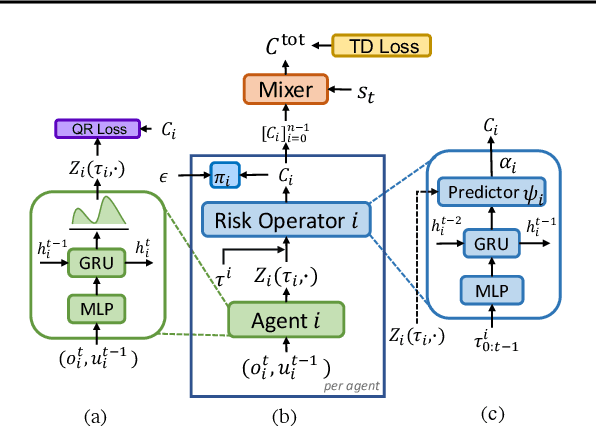
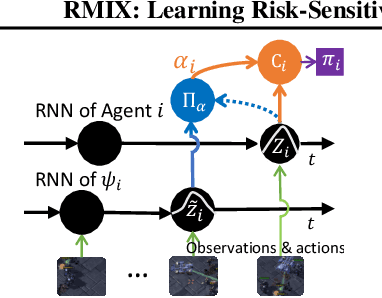
Current value-based multi-agent reinforcement learning methods optimize individual Q values to guide individuals' behaviours via centralized training with decentralized execution (CTDE). However, such expected, i.e., risk-neutral, Q value is not sufficient even with CTDE due to the randomness of rewards and the uncertainty in environments, which causes the failure of these methods to train coordinating agents in complex environments. To address these issues, we propose RMIX, a novel cooperative MARL method with the Conditional Value at Risk (CVaR) measure over the learned distributions of individuals' Q values. Specifically, we first learn the return distributions of individuals to analytically calculate CVaR for decentralized execution. Then, to handle the temporal nature of the stochastic outcomes during executions, we propose a dynamic risk level predictor for risk level tuning. Finally, we optimize the CVaR policies with CVaR values used to estimate the target in TD error during centralized training and the CVaR values are used as auxiliary local rewards to update the local distribution via Quantile Regression loss. Empirically, we show that our method significantly outperforms state-of-the-art methods on challenging StarCraft II tasks, demonstrating enhanced coordination and improved sample efficiency.
Lie on the Fly: Strategic Voting in an Iterative Preference Elicitation Process
May 13, 2019
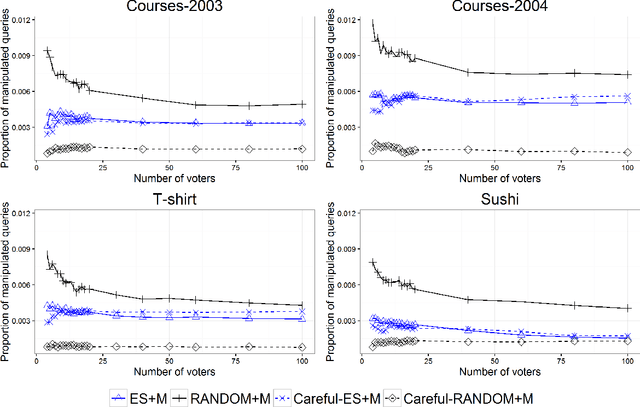
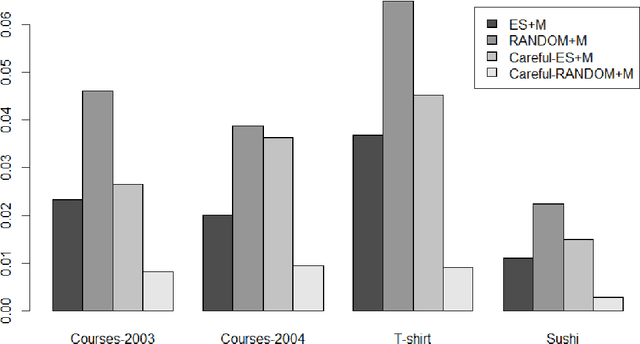
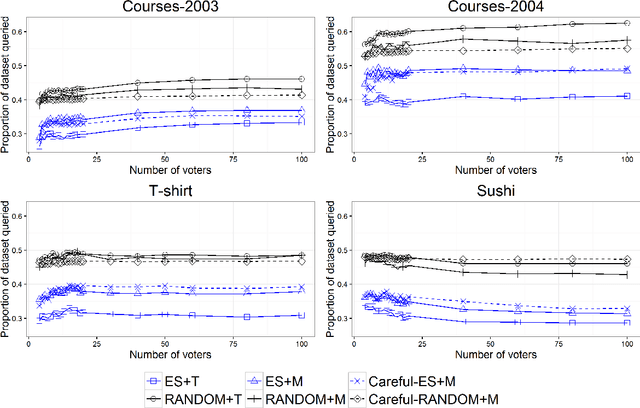
A voting center is in charge of collecting and aggregating voter preferences. In an iterative process, the center sends comparison queries to voters, requesting them to submit their preference between two items. Voters might discuss the candidates among themselves, figuring out during the elicitation process which candidates stand a chance of winning and which do not. Consequently, strategic voters might attempt to manipulate by deviating from their true preferences and instead submit a different response in order to attempt to maximize their profit. We provide a practical algorithm for strategic voters which computes the best manipulative vote and maximizes the voter's selfish outcome when such a vote exists. We also provide a careful voting center which is aware of the possible manipulations and avoids manipulative queries when possible. In an empirical study on four real-world domains, we show that in practice manipulation occurs in a low percentage of settings and has a low impact on the final outcome. The careful voting center reduces manipulation even further, thus allowing for a non-distorted group decision process to take place. We thus provide a core technology study of a voting process that can be adopted in opinion or information aggregation systems and in crowdsourcing applications, e.g., peer grading in Massive Open Online Courses (MOOCs).