 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-stream Policy Optimization
Sep 16, 2025
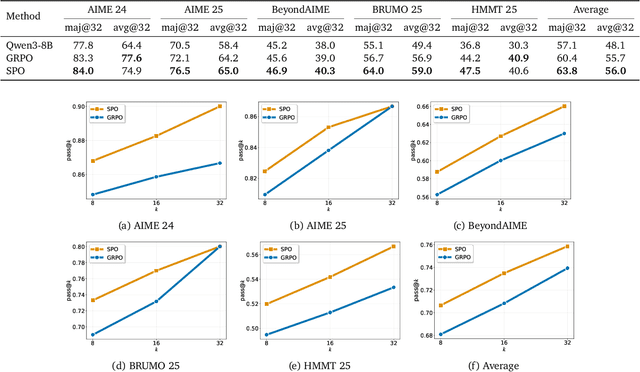

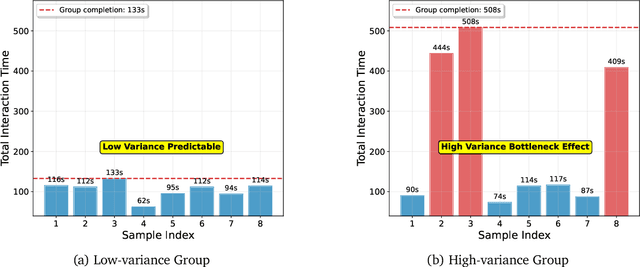
We revisit policy-gradient optimization for Large Language Models (LLMs) from a single-stream perspective. Prevailing group-based methods like GRPO reduce variance with on-the-fly baselines but suffer from critical flaws: frequent degenerate groups erase learning signals, and synchronization barriers hinder scalability. We introduce Single-stream Policy Optimization (SPO), which eliminates these issues by design. SPO replaces per-group baselines with a persistent, KL-adaptive value tracker and normalizes advantages globally across the batch, providing a stable, low-variance learning signal for every sample. Being group-free, SPO enables higher throughput and scales effectively in long-horizon or tool-integrated settings where generation times vary. Furthermore, the persistent value tracker naturally enables an adaptive curriculum via prioritized sampling. Experiments using Qwen3-8B show that SPO converges more smoothly and attains higher accuracy than GRPO, while eliminating computation wasted on degenerate groups. Ablation studies confirm that SPO's gains stem from its principled approach to baseline estimation and advantage normalization, offering a more robust and efficient path for LLM reasoning. Across five hard math benchmarks with Qwen3 8B, SPO improves the average maj@32 by +3.4 percentage points (pp) over GRPO, driven by substantial absolute point gains on challenging datasets, including +7.3 pp on BRUMO 25, +4.4 pp on AIME 25, +3.3 pp on HMMT 25, and achieves consistent relative gain in pass@$k$ across the evaluated $k$ values. SPO's success challenges the prevailing trend of adding incidental complexity to RL algorithms, highlighting a path where fundamental principles, not architectural workarounds, drive the next wave of progress in LLM reasoning.
Understanding Tool-Integrated Reasoning
Aug 26, 2025We study why Tool-Integrated Reasoning (TIR) makes Large Language Models (LLMs) more capable. While LLMs integrated with tools like Python code interpreters show great promise, a principled theory explaining why this paradigm is effective has been missing. This work provides the first formal proof that TIR fundamentally expands an LLM's capabilities. We demonstrate that tools enable a strict expansion of the model's empirical and feasible support, breaking the capability ceiling of pure-text models by unlocking problem-solving strategies that are otherwise impossible or intractably verbose. To guide model behavior without compromising training stability and performance, we also introduce Advantage Shaping Policy Optimization (ASPO), a novel algorithm that directly modifies the advantage function to guide the policy behavior. We conduct comprehensive experiments on challenging mathematical benchmarks, leveraging a Python interpreter as the external tool. Our results show that the TIR model decisively outperforms its pure-text counterpart on the pass@k metric. Crucially, this advantage is not confined to computationally-intensive problems but extends to those requiring significant abstract insight. We further identify the emergent cognitive patterns that illustrate how models learn to think with tools. Finally, we report improved tool usage behavior with early code invocation and much more interactive turns with ASPO. Overall, our work provides the first principled explanation for TIR's success, shifting the focus from the mere fact that tools work to why and how they enable more powerful reasoning.
Agents Play Thousands of 3D Video Games
Mar 17, 2025We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL's effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead. Experiment results on the 3D video games are best viewed on https://zhongwen.one/projects/portal .
Pre-Trained Video Generative Models as World Simulators
Feb 10, 2025



Video generative models pre-trained on large-scale internet datasets have achieved remarkable success, excelling at producing realistic synthetic videos. However, they often generate clips based on static prompts (e.g., text or images), limiting their ability to model interactive and dynamic scenarios. In this paper, we propose Dynamic World Simulation (DWS), a novel approach to transform pre-trained video generative models into controllable world simulators capable of executing specified action trajectories. To achieve precise alignment between conditioned actions and generated visual changes, we introduce a lightweight, universal action-conditioned module that seamlessly integrates into any existing model. Instead of focusing on complex visual details, we demonstrate that consistent dynamic transition modeling is the key to building powerful world simulators. Building upon this insight, we further introduce a motion-reinforced loss that enhances action controllability by compelling the model to capture dynamic changes more effectively. Experiments demonstrate that DWS can be versatilely applied to both diffusion and autoregressive transformer models, achieving significant improvements in generating action-controllable, dynamically consistent videos across games and robotics domains. Moreover, to facilitate the applications of the learned world simulator in downstream tasks such as model-based reinforcement learning, we propose prioritized imagination to improve sample efficiency, demonstrating competitive performance compared with state-of-the-art methods.
Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform
Sep 29, 2023
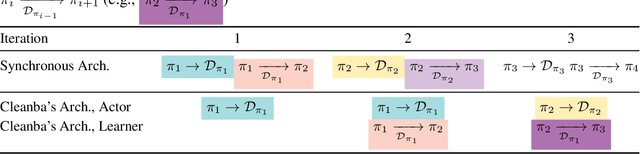
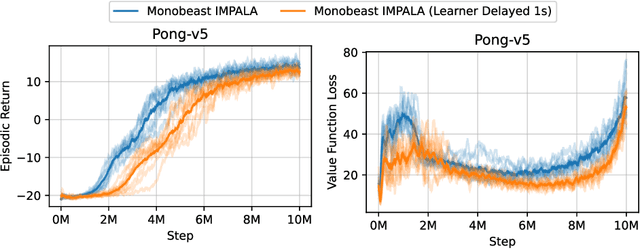

Distributed Deep Reinforcement Learning (DRL) aims to leverage more computational resources to train autonomous agents with less training time. Despite recent progress in the field, reproducibility issues have not been sufficiently explored. This paper first shows that the typical actor-learner framework can have reproducibility issues even if hyperparameters are controlled. We then introduce Cleanba, a new open-source platform for distributed DRL that proposes a highly reproducible architecture. Cleanba implements highly optimized distributed variants of PPO and IMPALA. Our Atari experiments show that these variants can obtain equivalent or higher scores than strong IMPALA baselines in moolib and torchbeast and PPO baseline in CleanRL. However, Cleanba variants present 1) shorter training time and 2) more reproducible learning curves in different hardware settings. Cleanba's source code is available at \url{https://github.com/vwxyzjn/cleanba}
Visual Imitation Learning with Patch Rewards
Feb 10, 2023

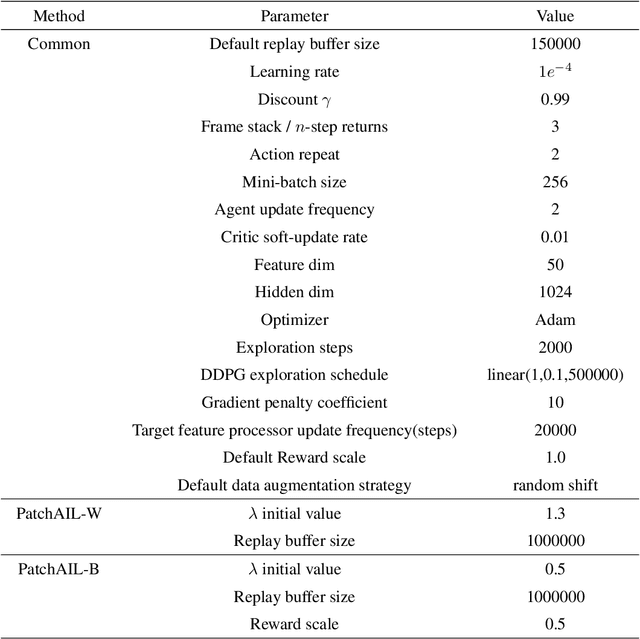
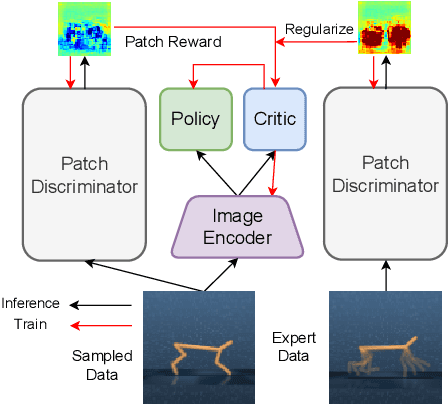
Visual imitation learning enables reinforcement learning agents to learn to behave from expert visual demonstrations such as videos or image sequences, without explicit, well-defined rewards. Previous research either adopted supervised learning techniques or induce simple and coarse scalar rewards from pixels, neglecting the dense information contained in the image demonstrations. In this work, we propose to measure the expertise of various local regions of image samples, or called \textit{patches}, and recover multi-dimensional \textit{patch rewards} accordingly. Patch reward is a more precise rewarding characterization that serves as a fine-grained expertise measurement and visual explainability tool. Specifically, we present Adversarial Imitation Learning with Patch Rewards (PatchAIL), which employs a patch-based discriminator to measure the expertise of different local parts from given images and provide patch rewards. The patch-based knowledge is also used to regularize the aggregated reward and stabilize the training. We evaluate our method on DeepMind Control Suite and Atari tasks. The experiment results have demonstrated that PatchAIL outperforms baseline methods and provides valuable interpretations for visual demonstrations.
Learning to Optimize for Reinforcement Learning
Feb 03, 2023In recent years, by leveraging more data, computation, and diverse tasks, learned optimizers have achieved remarkable success in supervised learning optimization, outperforming classical hand-designed optimizers. However, in practice, these learned optimizers fail to generalize to reinforcement learning tasks due to unstable and complex loss landscapes. Moreover, neither hand-designed optimizers nor learned optimizers have been specifically designed to address the unique optimization properties in reinforcement learning. In this work, we take a data-driven approach to learn to optimize for reinforcement learning using meta-learning. We introduce a novel optimizer structure that significantly improves the training efficiency of learned optimizers, making it possible to learn an optimizer for reinforcement learning from scratch. Although trained in toy tasks, our learned optimizer demonstrates its generalization ability to unseen complex tasks. Finally, we design a set of small gridworlds to train the first general-purpose optimizer for reinforcement learning.
Reinforcement Learning from Diverse Human Preferences
Jan 30, 2023The complexity of designing reward functions has been a major obstacle to the wide application of deep reinforcement learning (RL) techniques. Describing an agent's desired behaviors and properties can be difficult, even for experts. A new paradigm called reinforcement learning from human preferences (or preference-based RL) has emerged as a promising solution, in which reward functions are learned from human preference labels among behavior trajectories. However, existing methods for preference-based RL are limited by the need for accurate oracle preference labels. This paper addresses this limitation by developing a method for crowd-sourcing preference labels and learning from diverse human preferences. The key idea is to stabilize reward learning through regularization and correction in a latent space. To ensure temporal consistency, a strong constraint is imposed on the reward model that forces its latent space to be close to the prior distribution. Additionally, a confidence-based reward model ensembling method is designed to generate more stable and reliable predictions. The proposed method is tested on a variety of tasks in DMcontrol and Meta-world and has shown consistent and significant improvements over existing preference-based RL algorithms when learning from diverse feedback, paving the way for real-world applications of RL methods.
Benchmarking Deformable Object Manipulation with Differentiable Physics
Oct 24, 2022



Deformable Object Manipulation (DOM) is of significant importance to both daily and industrial applications. Recent successes in differentiable physics simulators allow learning algorithms to train a policy with analytic gradients through environment dynamics, which significantly facilitates the development of DOM algorithms. However, existing DOM benchmarks are either single-object-based or non-differentiable. This leaves the questions of 1) how a task-specific algorithm performs on other tasks and 2) how a differentiable-physics-based algorithm compares with the non-differentiable ones in general. In this work, we present DaXBench, a differentiable DOM benchmark with a wide object and task coverage. DaXBench includes 9 challenging high-fidelity simulated tasks, covering rope, cloth, and liquid manipulation with various difficulty levels. To better understand the performance of general algorithms on different DOM tasks, we conduct comprehensive experiments over representative DOM methods, ranging from planning to imitation learning and reinforcement learning. In addition, we provide careful empirical studies of existing decision-making algorithms based on differentiable physics, and discuss their limitations, as well as potential future directions.
RPM: Generalizable Behaviors for Multi-Agent Reinforcement Learning
Oct 18, 2022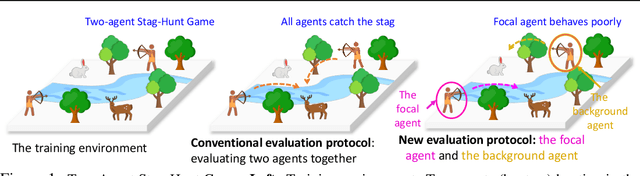
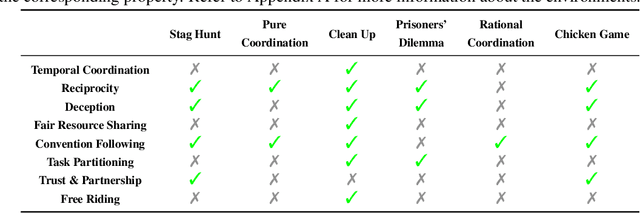


Despite the recent advancement in multi-agent reinforcement learning (MARL), the MARL agents easily overfit the training environment and perform poorly in the evaluation scenarios where other agents behave differently. Obtaining generalizable policies for MARL agents is thus necessary but challenging mainly due to complex multi-agent interactions. In this work, we model the problem with Markov Games and propose a simple yet effective method, ranked policy memory (RPM), to collect diverse multi-agent trajectories for training MARL policies with good generalizability. The main idea of RPM is to maintain a look-up memory of policies. In particular, we try to acquire various levels of behaviors by saving policies via ranking the training episode return, i.e., the episode return of agents in the training environment; when an episode starts, the learning agent can then choose a policy from the RPM as the behavior policy. This innovative self-play training framework leverages agents' past policies and guarantees the diversity of multi-agent interaction in the training data. We implement RPM on top of MARL algorithms and conduct extensive experiments on Melting Pot. It has been demonstrated that RPM enables MARL agents to interact with unseen agents in multi-agent generalization evaluation scenarios and complete given tasks, and it significantly boosts the performance up to 402% on average.