 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWorld 2: Learning Transferable Knowledge from Real-world Videos
Feb 10, 2026Learning transferable knowledge from unlabeled video data and applying it in new environments is a fundamental capability of intelligent agents. This work presents VideoWorld 2, which extends VideoWorld and offers the first investigation into learning transferable knowledge directly from raw real-world videos. At its core, VideoWorld 2 introduces a dynamic-enhanced Latent Dynamics Model (dLDM) that decouples action dynamics from visual appearance: a pretrained video diffusion model handles visual appearance modeling, enabling the dLDM to learn latent codes that focus on compact and meaningful task-related dynamics. These latent codes are then modeled autoregressively to learn task policies and support long-horizon reasoning. We evaluate VideoWorld 2 on challenging real-world handcraft making tasks, where prior video generation and latent-dynamics models struggle to operate reliably. Remarkably, VideoWorld 2 achieves up to 70% improvement in task success rate and produces coherent long execution videos. In robotics, we show that VideoWorld 2 can acquire effective manipulation knowledge from the Open-X dataset, which substantially improves task performance on CALVIN. This study reveals the potential of learning transferable world knowledge directly from raw videos, with all code, data, and models to be open-sourced for further research.
SpatialTree: How Spatial Abilities Branch Out in MLLMs
Dec 23, 2025Cognitive science suggests that spatial ability develops progressively-from perception to reasoning and interaction. Yet in multimodal LLMs (MLLMs), this hierarchy remains poorly understood, as most studies focus on a narrow set of tasks. We introduce SpatialTree, a cognitive-science-inspired hierarchy that organizes spatial abilities into four levels: low-level perception (L1), mental mapping (L2), simulation (L3), and agentic competence (L4). Based on this taxonomy, we construct the first capability-centric hierarchical benchmark, thoroughly evaluating mainstream MLLMs across 27 sub-abilities. The evaluation results reveal a clear structure: L1 skills are largely orthogonal, whereas higher-level skills are strongly correlated, indicating increasing interdependency. Through targeted supervised fine-tuning, we uncover a surprising transfer dynamic-negative transfer within L1, but strong cross-level transfer from low- to high-level abilities with notable synergy. Finally, we explore how to improve the entire hierarchy. We find that naive RL that encourages extensive "thinking" is unreliable: it helps complex reasoning but hurts intuitive perception. We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels. By building SpatialTree, we provide a proof-of-concept framework for understanding and systematically scaling spatial abilities in MLLMs.
Depth Anything 3: Recovering the Visual Space from Any Views
Nov 13, 2025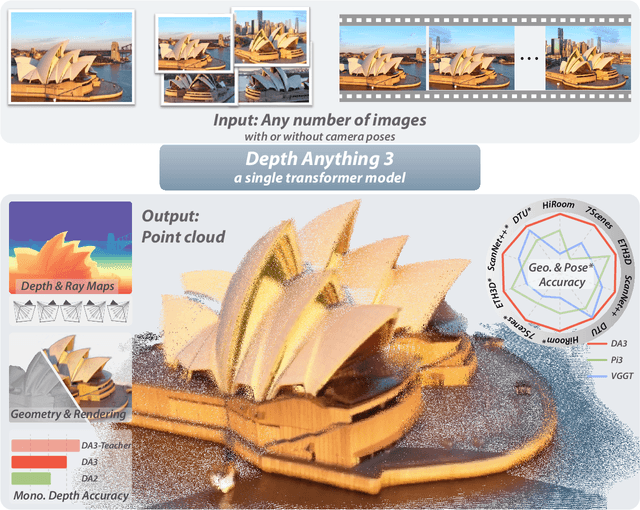
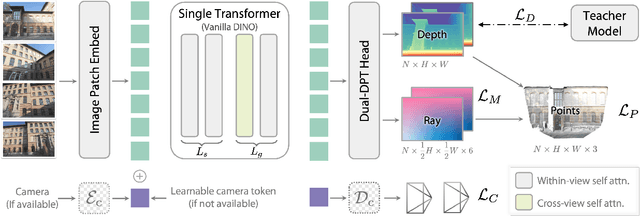
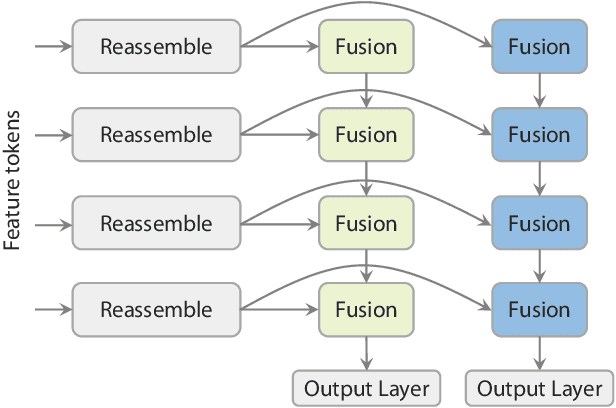
We present Depth Anything 3 (DA3), a model that predicts spatially consistent geometry from an arbitrary number of visual inputs, with or without known camera poses. In pursuit of minimal modeling, DA3 yields two key insights: a single plain transformer (e.g., vanilla DINO encoder) is sufficient as a backbone without architectural specialization, and a singular depth-ray prediction target obviates the need for complex multi-task learning. Through our teacher-student training paradigm, the model achieves a level of detail and generalization on par with Depth Anything 2 (DA2). We establish a new visual geometry benchmark covering camera pose estimation, any-view geometry and visual rendering. On this benchmark, DA3 sets a new state-of-the-art across all tasks, surpassing prior SOTA VGGT by an average of 44.3% in camera pose accuracy and 25.1% in geometric accuracy. Moreover, it outperforms DA2 in monocular depth estimation. All models are trained exclusively on public academic datasets.
SpatialTrackerV2: 3D Point Tracking Made Easy
Jul 16, 2025We present SpatialTrackerV2, a feed-forward 3D point tracking method for monocular videos. Going beyond modular pipelines built on off-the-shelf components for 3D tracking, our approach unifies the intrinsic connections between point tracking, monocular depth, and camera pose estimation into a high-performing and feedforward 3D point tracker. It decomposes world-space 3D motion into scene geometry, camera ego-motion, and pixel-wise object motion, with a fully differentiable and end-to-end architecture, allowing scalable training across a wide range of datasets, including synthetic sequences, posed RGB-D videos, and unlabeled in-the-wild footage. By learning geometry and motion jointly from such heterogeneous data, SpatialTrackerV2 outperforms existing 3D tracking methods by 30%, and matches the accuracy of leading dynamic 3D reconstruction approaches while running 50$\times$ faster.
$\text{M}^{\text{3}}$: A Modular World Model over Streams of Tokens
Feb 20, 2025Token-based world models emerged as a promising modular framework, modeling dynamics over token streams while optimizing tokenization separately. While successful in visual environments with discrete actions (e.g., Atari games), their broader applicability remains uncertain. In this paper, we introduce $\text{M}^{\text{3}}$, a $\textbf{m}$odular $\textbf{w}$orld $\textbf{m}$odel that extends this framework, enabling flexible combinations of observation and action modalities through independent modality-specific components. $\text{M}^{\text{3}}$ integrates several improvements from existing literature to enhance agent performance. Through extensive empirical evaluation across diverse benchmarks, $\text{M}^{\text{3}}$ achieves state-of-the-art sample efficiency for planning-free world models. Notably, among these methods, it is the first to reach a human-level median score on Atari 100K, with superhuman performance on 13 games. Our code and model weights are publicly available at https://github.com/leor-c/M3.
Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
Jan 21, 2025Depth Anything has achieved remarkable success in monocular depth estimation with strong generalization ability. However, it suffers from temporal inconsistency in videos, hindering its practical applications. Various methods have been proposed to alleviate this issue by leveraging video generation models or introducing priors from optical flow and camera poses. Nonetheless, these methods are only applicable to short videos (< 10 seconds) and require a trade-off between quality and computational efficiency. We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. We base our model on Depth Anything V2 and replace its head with an efficient spatial-temporal head. We design a straightforward yet effective temporal consistency loss by constraining the temporal depth gradient, eliminating the need for additional geometric priors. The model is trained on a joint dataset of video depth and unlabeled images, similar to Depth Anything V2. Moreover, a novel key-frame-based strategy is developed for long video inference. Experiments show that our model can be applied to arbitrarily long videos without compromising quality, consistency, or generalization ability. Comprehensive evaluations on multiple video benchmarks demonstrate that our approach sets a new state-of-the-art in zero-shot video depth estimation. We offer models of different scales to support a range of scenarios, with our smallest model capable of real-time performance at 30 FPS.
VideoWorld: Exploring Knowledge Learning from Unlabeled Videos
Jan 16, 2025This work explores whether a deep generative model can learn complex knowledge solely from visual input, in contrast to the prevalent focus on text-based models like large language models (LLMs). We develop VideoWorld, an auto-regressive video generation model trained on unlabeled video data, and test its knowledge acquisition abilities in video-based Go and robotic control tasks. Our experiments reveal two key findings: (1) video-only training provides sufficient information for learning knowledge, including rules, reasoning and planning capabilities, and (2) the representation of visual change is crucial for knowledge acquisition. To improve both the efficiency and efficacy of this process, we introduce the Latent Dynamics Model (LDM) as a key component of VideoWorld. Remarkably, VideoWorld reaches a 5-dan professional level in the Video-GoBench with just a 300-million-parameter model, without relying on search algorithms or reward mechanisms typical in reinforcement learning. In robotic tasks, VideoWorld effectively learns diverse control operations and generalizes across environments, approaching the performance of oracle models in CALVIN and RLBench. This study opens new avenues for knowledge acquisition from visual data, with all code, data, and models open-sourced for further research.
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
Dec 18, 2024Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024

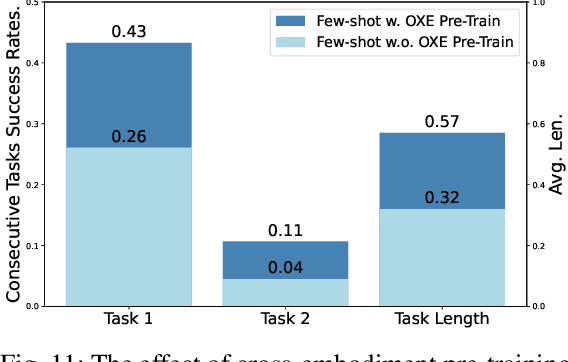

Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
Image Understanding Makes for A Good Tokenizer for Image Generation
Nov 07, 2024Abstract Modern image generation (IG) models have been shown to capture rich semantics valuable for image understanding (IU) tasks. However, the potential of IU models to improve IG performance remains uncharted. We address this issue using a token-based IG framework, which relies on effective tokenizers to project images into token sequences. Currently, pixel reconstruction (e.g., VQGAN) dominates the training objective for image tokenizers. In contrast, our approach adopts the feature reconstruction objective, where tokenizers are trained by distilling knowledge from pretrained IU encoders. Comprehensive comparisons indicate that tokenizers with strong IU capabilities achieve superior IG performance across a variety of metrics, datasets, tasks, and proposal networks. Notably, VQ-KD CLIP achieves $4.10$ FID on ImageNet-1k (IN-1k). Visualization suggests that the superiority of VQ-KD can be partly attributed to the rich semantics within the VQ-KD codebook. We further introduce a straightforward pipeline to directly transform IU encoders into tokenizers, demonstrating exceptional effectiveness for IG tasks. These discoveries may energize further exploration into image tokenizer research and inspire the community to reassess the relationship between IU and IG. The code is released at https://github.com/magic-research/vector_quantization.