 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient with Tree Search: Avoiding Local Optimas through Lookahead
Jun 08, 2025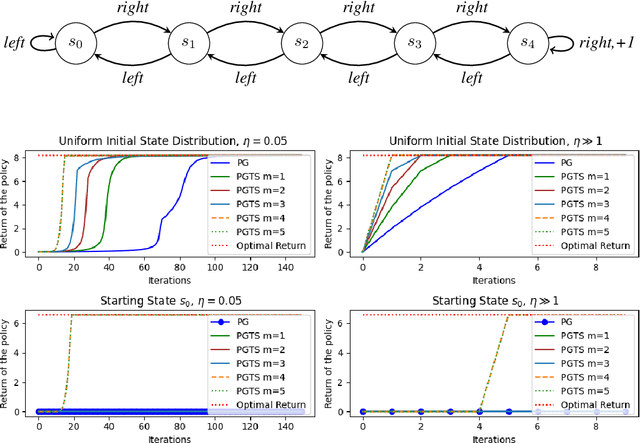
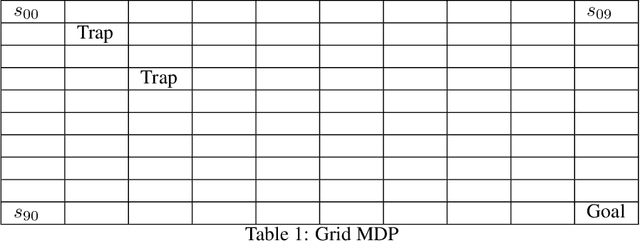
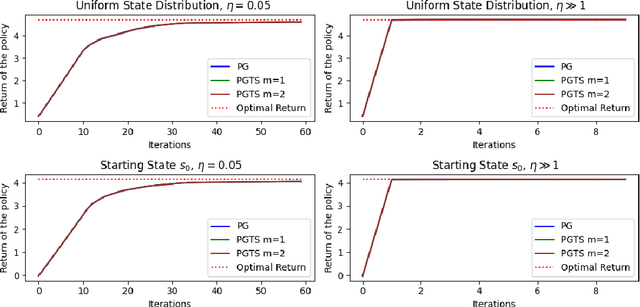

Classical policy gradient (PG) methods in reinforcement learning frequently converge to suboptimal local optima, a challenge exacerbated in large or complex environments. This work investigates Policy Gradient with Tree Search (PGTS), an approach that integrates an $m$-step lookahead mechanism to enhance policy optimization. We provide theoretical analysis demonstrating that increasing the tree search depth $m$-monotonically reduces the set of undesirable stationary points and, consequently, improves the worst-case performance of any resulting stationary policy. Critically, our analysis accommodates practical scenarios where policy updates are restricted to states visited by the current policy, rather than requiring updates across the entire state space. Empirical evaluations on diverse MDP structures, including Ladder, Tightrope, and Gridworld environments, illustrate PGTS's ability to exhibit "farsightedness," navigate challenging reward landscapes, escape local traps where standard PG fails, and achieve superior solutions.
Policy Optimized Text-to-Image Pipeline Design
May 27, 2025Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
$\text{M}^{\text{3}}$: A Modular World Model over Streams of Tokens
Feb 20, 2025Token-based world models emerged as a promising modular framework, modeling dynamics over token streams while optimizing tokenization separately. While successful in visual environments with discrete actions (e.g., Atari games), their broader applicability remains uncertain. In this paper, we introduce $\text{M}^{\text{3}}$, a $\textbf{m}$odular $\textbf{w}$orld $\textbf{m}$odel that extends this framework, enabling flexible combinations of observation and action modalities through independent modality-specific components. $\text{M}^{\text{3}}$ integrates several improvements from existing literature to enhance agent performance. Through extensive empirical evaluation across diverse benchmarks, $\text{M}^{\text{3}}$ achieves state-of-the-art sample efficiency for planning-free world models. Notably, among these methods, it is the first to reach a human-level median score on Atari 100K, with superhuman performance on 13 games. Our code and model weights are publicly available at https://github.com/leor-c/M3.
RL-RC-DoT: A Block-level RL agent for Task-Aware Video Compression
Jan 21, 2025Video encoders optimize compression for human perception by minimizing reconstruction error under bit-rate constraints. In many modern applications such as autonomous driving, an overwhelming majority of videos serve as input for AI systems performing tasks like object recognition or segmentation, rather than being watched by humans. It is therefore useful to optimize the encoder for a downstream task instead of for perceptual image quality. However, a major challenge is how to combine such downstream optimization with existing standard video encoders, which are highly efficient and popular. Here, we address this challenge by controlling the Quantization Parameters (QPs) at the macro-block level to optimize the downstream task. This granular control allows us to prioritize encoding for task-relevant regions within each frame. We formulate this optimization problem as a Reinforcement Learning (RL) task, where the agent learns to balance long-term implications of choosing QPs on both task performance and bit-rate constraints. Notably, our policy does not require the downstream task as an input during inference, making it suitable for streaming applications and edge devices such as vehicles. We demonstrate significant improvements in two tasks, car detection, and ROI (saliency) encoding. Our approach improves task performance for a given bit rate compared to traditional task agnostic encoding methods, paving the way for more efficient task-aware video compression.
Solving Non-Rectangular Reward-Robust MDPs via Frequency Regularization
Sep 03, 2023In robust Markov decision processes (RMDPs), it is assumed that the reward and the transition dynamics lie in a given uncertainty set. By targeting maximal return under the most adversarial model from that set, RMDPs address performance sensitivity to misspecified environments. Yet, to preserve computational tractability, the uncertainty set is traditionally independently structured for each state. This so-called rectangularity condition is solely motivated by computational concerns. As a result, it lacks a practical incentive and may lead to overly conservative behavior. In this work, we study coupled reward RMDPs where the transition kernel is fixed, but the reward function lies within an $\alpha$-radius from a nominal one. We draw a direct connection between this type of non-rectangular reward-RMDPs and applying policy visitation frequency regularization. We introduce a policy-gradient method, and prove its convergence. Numerical experiments illustrate the learned policy's robustness and its less conservative behavior when compared to rectangular uncertainty.
Robust Reinforcement Learning via Adversarial Kernel Approximation
Jun 09, 2023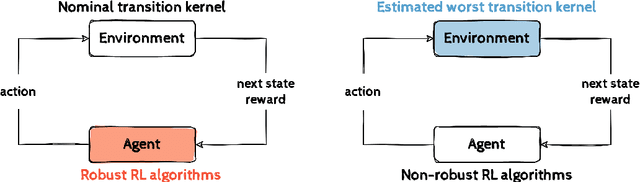
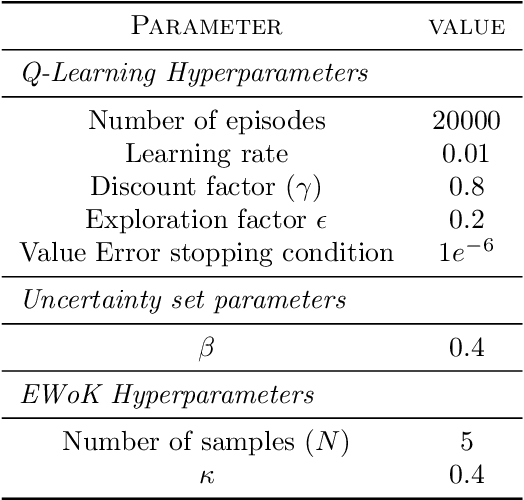
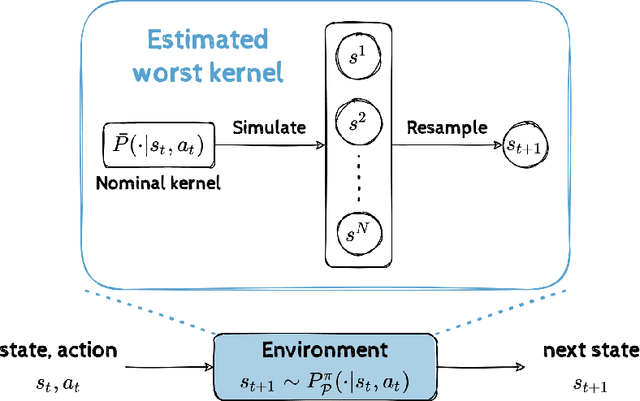
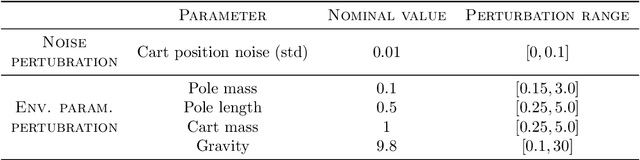
Robust Markov Decision Processes (RMDPs) provide a framework for sequential decision-making that is robust to perturbations on the transition kernel. However, robust reinforcement learning (RL) approaches in RMDPs do not scale well to realistic online settings with high-dimensional domains. By characterizing the adversarial kernel in RMDPs, we propose a novel approach for online robust RL that approximates the adversarial kernel and uses a standard (non-robust) RL algorithm to learn a robust policy. Notably, our approach can be applied on top of any underlying RL algorithm, enabling easy scaling to high-dimensional domains. Experiments in classic control tasks, MinAtar and DeepMind Control Suite demonstrate the effectiveness and the applicability of our method.