 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Invertible Neural Networks
Feb 05, 2026The Moore-Penrose Pseudo-inverse (PInv) serves as the fundamental solution for linear systems. In this paper, we propose a natural generalization of PInv to the nonlinear regime in general and to neural networks in particular. We introduce Surjective Pseudo-invertible Neural Networks (SPNN), a class of architectures explicitly designed to admit a tractable non-linear PInv. The proposed non-linear PInv and its implementation in SPNN satisfy fundamental geometric properties. One such property is null-space projection or "Back-Projection", $x' = x + A^\dagger(y-Ax)$, which moves a sample $x$ to its closest consistent state $x'$ satisfying $Ax=y$. We formalize Non-Linear Back-Projection (NLBP), a method that guarantees the same consistency constraint for non-linear mappings $f(x)=y$ via our defined PInv. We leverage SPNNs to expand the scope of zero-shot inverse problems. Diffusion-based null-space projection has revolutionized zero-shot solving for linear inverse problems by exploiting closed-form back-projection. We extend this method to non-linear degradations. Here, "degradation" is broadly generalized to include any non-linear loss of information, spanning from optical distortions to semantic abstractions like classification. This approach enables zero-shot inversion of complex degradations and allows precise semantic control over generative outputs without retraining the diffusion prior.
Who Said Neural Networks Aren't Linear?
Oct 09, 2025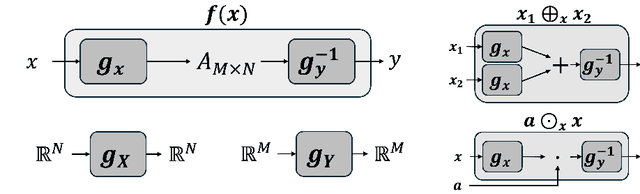



Neural networks are famously nonlinear. However, linearity is defined relative to a pair of vector spaces, $f$$:$$X$$\to$$Y$. Is it possible to identify a pair of non-standard vector spaces for which a conventionally nonlinear function is, in fact, linear? This paper introduces a method that makes such vector spaces explicit by construction. We find that if we sandwich a linear operator $A$ between two invertible neural networks, $f(x)=g_y^{-1}(A g_x(x))$, then the corresponding vector spaces $X$ and $Y$ are induced by newly defined addition and scaling actions derived from $g_x$ and $g_y$. We term this kind of architecture a Linearizer. This framework makes the entire arsenal of linear algebra, including SVD, pseudo-inverse, orthogonal projection and more, applicable to nonlinear mappings. Furthermore, we show that the composition of two Linearizers that share a neural network is also a Linearizer. We leverage this property and demonstrate that training diffusion models using our architecture makes the hundreds of sampling steps collapse into a single step. We further utilize our framework to enforce idempotency (i.e. $f(f(x))=f(x)$) on networks leading to a globally projective generative model and to demonstrate modular style transfer.
KernelFusion: Assumption-Free Blind Super-Resolution via Patch Diffusion
Mar 27, 2025Traditional super-resolution (SR) methods assume an ``ideal'' downscaling SR-kernel (e.g., bicubic downscaling) between the high-resolution (HR) image and the low-resolution (LR) image. Such methods fail once the LR images are generated differently. Current blind-SR methods aim to remove this assumption, but are still fundamentally restricted to rather simplistic downscaling SR-kernels (e.g., anisotropic Gaussian kernels), and fail on more complex (out of distribution) downscaling degradations. However, using the correct SR-kernel is often more important than using a sophisticated SR algorithm. In ``KernelFusion'' we introduce a zero-shot diffusion-based method that makes no assumptions about the kernel. Our method recovers the unique image-specific SR-kernel directly from the LR input image, while simultaneously recovering its corresponding HR image. KernelFusion exploits the principle that the correct SR-kernel is the one that maximizes patch similarity across different scales of the LR image. We first train an image-specific patch-based diffusion model on the single LR input image, capturing its unique internal patch statistics. We then reconstruct a larger HR image with the same learned patch distribution, while simultaneously recovering the correct downscaling SR-kernel that maintains this cross-scale relation between the HR and LR images. Empirical results show that KernelFusion vastly outperforms all SR baselines on complex downscaling degradations, where existing SotA Blind-SR methods fail miserably. By breaking free from predefined kernel assumptions, KernelFusion pushes Blind-SR into a new assumption-free paradigm, handling downscaling kernels previously thought impossible.
RL-RC-DoT: A Block-level RL agent for Task-Aware Video Compression
Jan 21, 2025Video encoders optimize compression for human perception by minimizing reconstruction error under bit-rate constraints. In many modern applications such as autonomous driving, an overwhelming majority of videos serve as input for AI systems performing tasks like object recognition or segmentation, rather than being watched by humans. It is therefore useful to optimize the encoder for a downstream task instead of for perceptual image quality. However, a major challenge is how to combine such downstream optimization with existing standard video encoders, which are highly efficient and popular. Here, we address this challenge by controlling the Quantization Parameters (QPs) at the macro-block level to optimize the downstream task. This granular control allows us to prioritize encoding for task-relevant regions within each frame. We formulate this optimization problem as a Reinforcement Learning (RL) task, where the agent learns to balance long-term implications of choosing QPs on both task performance and bit-rate constraints. Notably, our policy does not require the downstream task as an input during inference, making it suitable for streaming applications and edge devices such as vehicles. We demonstrate significant improvements in two tasks, car detection, and ROI (saliency) encoding. Our approach improves task performance for a given bit rate compared to traditional task agnostic encoding methods, paving the way for more efficient task-aware video compression.
IT$^3$: Idempotent Test-Time Training
Oct 05, 2024



This paper introduces Idempotent Test-Time Training (IT$^3$), a novel approach to addressing the challenge of distribution shift. While supervised-learning methods assume matching train and test distributions, this is rarely the case for machine learning systems deployed in the real world. Test-Time Training (TTT) approaches address this by adapting models during inference, but they are limited by a domain specific auxiliary task. IT$^3$ is based on the universal property of idempotence. An idempotent operator is one that can be applied sequentially without changing the result beyond the initial application, that is $f(f(x))=f(x)$. At training, the model receives an input $x$ along with another signal that can either be the ground truth label $y$ or a neutral "don't know" signal $0$. At test time, the additional signal can only be $0$. When sequentially applying the model, first predicting $y_0 = f(x, 0)$ and then $y_1 = f(x, y_0)$, the distance between $y_0$ and $y_1$ measures certainty and indicates out-of-distribution input $x$ if high. We use this distance, that can be expressed as $||f(x, f(x, 0)) - f(x, 0)||$ as our TTT loss during inference. By carefully optimizing this objective, we effectively train $f(x,\cdot)$ to be idempotent, projecting the internal representation of the input onto the training distribution. We demonstrate the versatility of our approach across various tasks, including corrupted image classification, aerodynamic predictions, tabular data with missing information, age prediction from face, and large-scale aerial photo segmentation. Moreover, these tasks span different architectures such as MLPs, CNNs, and GNNs.
Idempotent Generative Network
Nov 02, 2023



We propose a new approach for generative modeling based on training a neural network to be idempotent. An idempotent operator is one that can be applied sequentially without changing the result beyond the initial application, namely $f(f(z))=f(z)$. The proposed model $f$ is trained to map a source distribution (e.g, Gaussian noise) to a target distribution (e.g. realistic images) using the following objectives: (1) Instances from the target distribution should map to themselves, namely $f(x)=x$. We define the target manifold as the set of all instances that $f$ maps to themselves. (2) Instances that form the source distribution should map onto the defined target manifold. This is achieved by optimizing the idempotence term, $f(f(z))=f(z)$ which encourages the range of $f(z)$ to be on the target manifold. Under ideal assumptions such a process provably converges to the target distribution. This strategy results in a model capable of generating an output in one step, maintaining a consistent latent space, while also allowing sequential applications for refinement. Additionally, we find that by processing inputs from both target and source distributions, the model adeptly projects corrupted or modified data back to the target manifold. This work is a first step towards a ``global projector'' that enables projecting any input into a target data distribution.
Predicting masked tokens in stochastic locations improves masked image modeling
Jul 31, 2023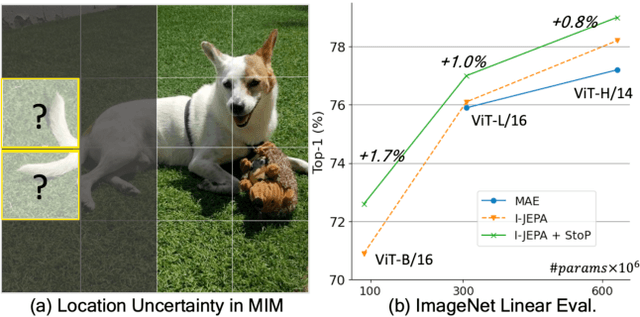
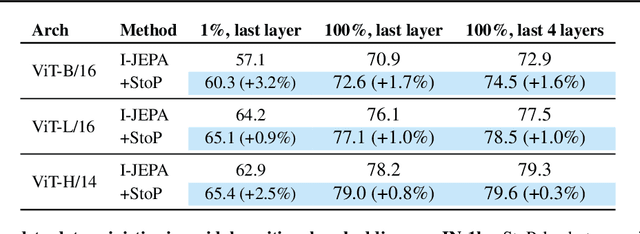
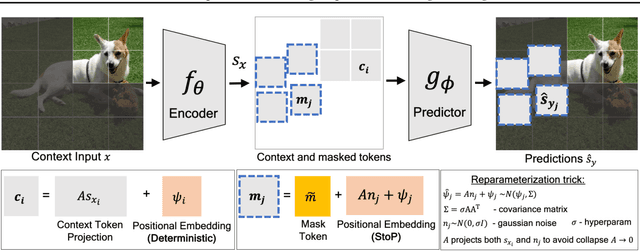
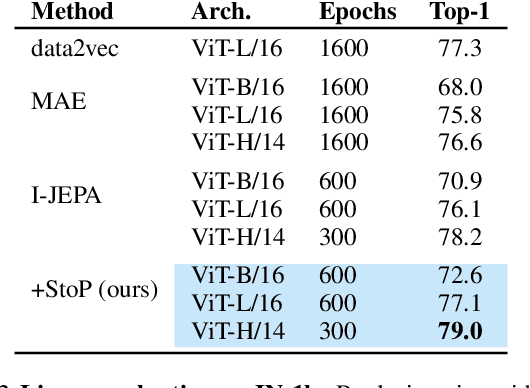
Self-supervised learning is a promising paradigm in deep learning that enables learning from unlabeled data by constructing pretext tasks that require learning useful representations. In natural language processing, the dominant pretext task has been masked language modeling (MLM), while in computer vision there exists an equivalent called Masked Image Modeling (MIM). However, MIM is challenging because it requires predicting semantic content in accurate locations. E.g, given an incomplete picture of a dog, we can guess that there is a tail, but we cannot determine its exact location. In this work, we propose FlexPredict, a stochastic model that addresses this challenge by incorporating location uncertainty into the model. Specifically, we condition the model on stochastic masked token positions to guide the model toward learning features that are more robust to location uncertainties. Our approach improves downstream performance on a range of tasks, e.g, compared to MIM baselines, FlexPredict boosts ImageNet linear probing by 1.6% with ViT-B and by 2.5% for semi-supervised video segmentation using ViT-L.
Rosetta Neurons: Mining the Common Units in a Model Zoo
Jun 16, 2023Do different neural networks, trained for various vision tasks, share some common representations? In this paper, we demonstrate the existence of common features we call "Rosetta Neurons" across a range of models with different architectures, different tasks (generative and discriminative), and different types of supervision (class-supervised, text-supervised, self-supervised). We present an algorithm for mining a dictionary of Rosetta Neurons across several popular vision models: Class Supervised-ResNet50, DINO-ResNet50, DINO-ViT, MAE, CLIP-ResNet50, BigGAN, StyleGAN-2, StyleGAN-XL. Our findings suggest that certain visual concepts and structures are inherently embedded in the natural world and can be learned by different models regardless of the specific task or architecture, and without the use of semantic labels. We can visualize shared concepts directly due to generative models included in our analysis. The Rosetta Neurons facilitate model-to-model translation enabling various inversion-based manipulations, including cross-class alignments, shifting, zooming, and more, without the need for specialized training.
The Hidden Language of Diffusion Models
Jun 06, 2023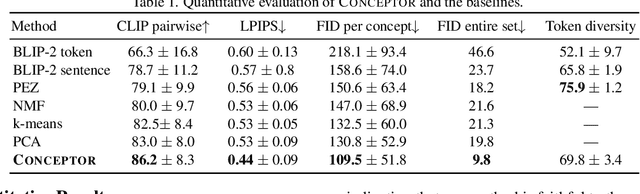



Text-to-image diffusion models have demonstrated an unparalleled ability to generate high-quality, diverse images from a textual concept (e.g., "a doctor", "love"). However, the internal process of mapping text to a rich visual representation remains an enigma. In this work, we tackle the challenge of understanding concept representations in text-to-image models by decomposing an input text prompt into a small set of interpretable elements. This is achieved by learning a pseudo-token that is a sparse weighted combination of tokens from the model's vocabulary, with the objective of reconstructing the images generated for the given concept. Applied over the state-of-the-art Stable Diffusion model, this decomposition reveals non-trivial and surprising structures in the representations of concepts. For example, we find that some concepts such as "a president" or "a composer" are dominated by specific instances (e.g., "Obama", "Biden") and their interpolations. Other concepts, such as "happiness" combine associated terms that can be concrete ("family", "laughter") or abstract ("friendship", "emotion"). In addition to peering into the inner workings of Stable Diffusion, our method also enables applications such as single-image decomposition to tokens, bias detection and mitigation, and semantic image manipulation. Our code will be available at: https://hila-chefer.github.io/Conceptor/
Diverse Video Generation from a Single Video
May 11, 2022

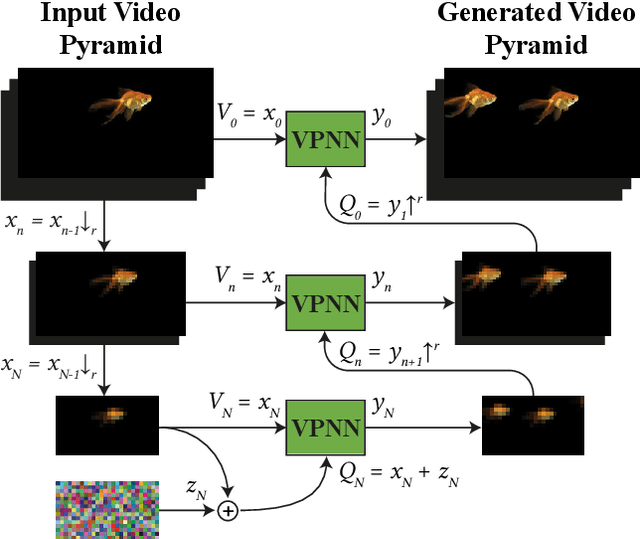
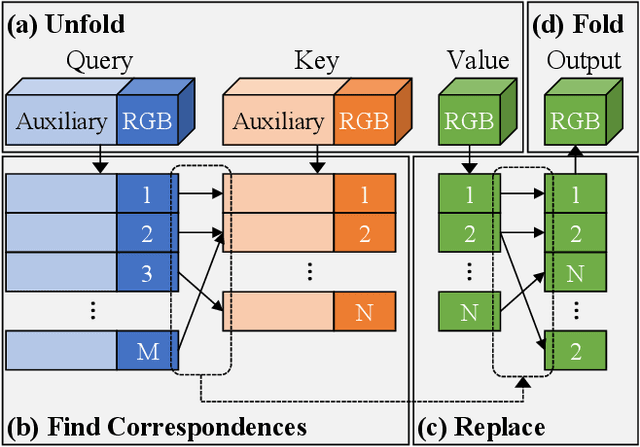
GANs are able to perform generation and manipulation tasks, trained on a single video. However, these single video GANs require unreasonable amount of time to train on a single video, rendering them almost impractical. In this paper we question the necessity of a GAN for generation from a single video, and introduce a non-parametric baseline for a variety of generation and manipulation tasks. We revive classical space-time patches-nearest-neighbors approaches and adapt them to a scalable unconditional generative model, without any learning. This simple baseline surprisingly outperforms single-video GANs in visual quality and realism (confirmed by quantitative and qualitative evaluations), and is disproportionately faster (runtime reduced from several days to seconds). Our approach is easily scaled to Full-HD videos. We also use the same framework to demonstrate video analogies and spatio-temporal retargeting. These observations show that classical approaches significantly outperform heavy deep learning machinery for these tasks. This sets a new baseline for single-video generation and manipulation tasks, and no less important -- makes diverse generation from a single video practically possible for the first time.