 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Training Data From Real World Models Trained with Transfer Learning
Jul 22, 2024Current methods for reconstructing training data from trained classifiers are restricted to very small models, limited training set sizes, and low-resolution images. Such restrictions hinder their applicability to real-world scenarios. In this paper, we present a novel approach enabling data reconstruction in realistic settings for models trained on high-resolution images. Our method adapts the reconstruction scheme of arXiv:2206.07758 to real-world scenarios -- specifically, targeting models trained via transfer learning over image embeddings of large pre-trained models like DINO-ViT and CLIP. Our work employs data reconstruction in the embedding space rather than in the image space, showcasing its applicability beyond visual data. Moreover, we introduce a novel clustering-based method to identify good reconstructions from thousands of candidates. This significantly improves on previous works that relied on knowledge of the training set to identify good reconstructed images. Our findings shed light on a potential privacy risk for data leakage from models trained using transfer learning.
Deconstructing Data Reconstruction: Multiclass, Weight Decay and General Losses
Jul 04, 2023
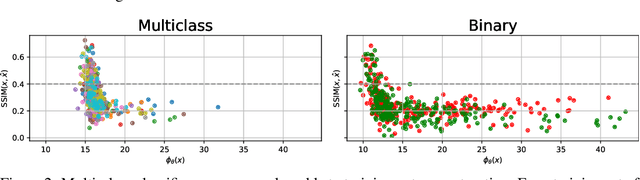
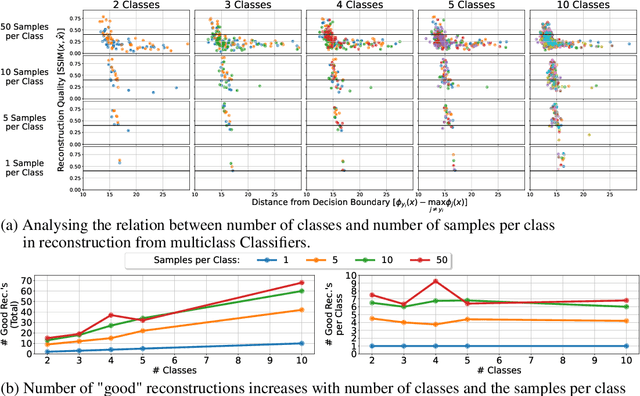
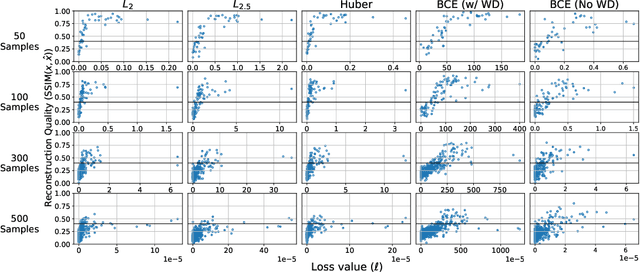
Memorization of training data is an active research area, yet our understanding of the inner workings of neural networks is still in its infancy. Recently, Haim et al. (2022) proposed a scheme to reconstruct training samples from multilayer perceptron binary classifiers, effectively demonstrating that a large portion of training samples are encoded in the parameters of such networks. In this work, we extend their findings in several directions, including reconstruction from multiclass and convolutional neural networks. We derive a more general reconstruction scheme which is applicable to a wider range of loss functions such as regression losses. Moreover, we study the various factors that contribute to networks' susceptibility to such reconstruction schemes. Intriguingly, we observe that using weight decay during training increases reconstructability both in terms of quantity and quality. Additionally, we examine the influence of the number of neurons relative to the number of training samples on the reconstructability.
Reconstructing Training Data from Multiclass Neural Networks
May 05, 2023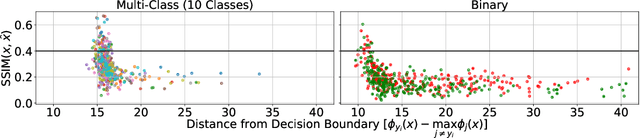
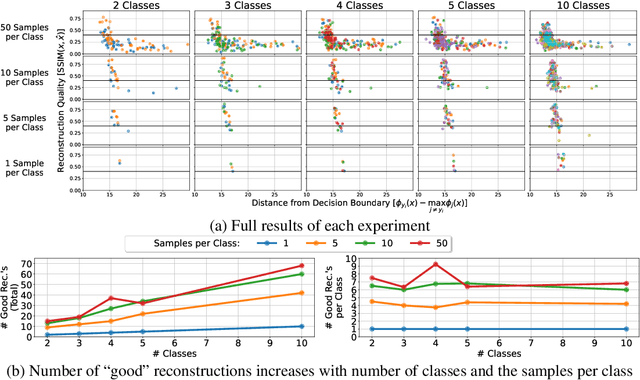
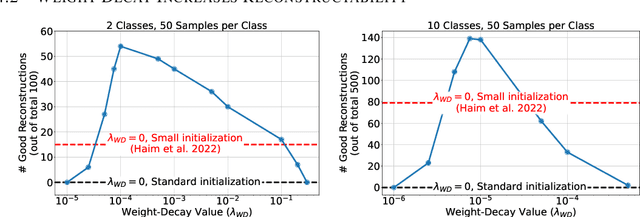
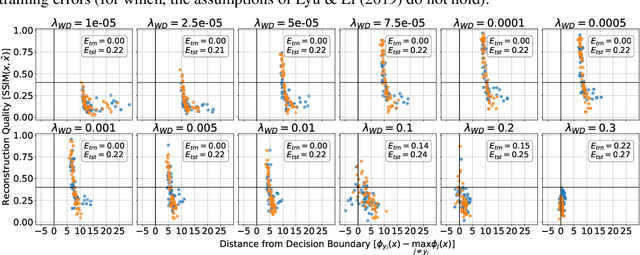
Reconstructing samples from the training set of trained neural networks is a major privacy concern. Haim et al. (2022) recently showed that it is possible to reconstruct training samples from neural network binary classifiers, based on theoretical results about the implicit bias of gradient methods. In this work, we present several improvements and new insights over this previous work. As our main improvement, we show that training-data reconstruction is possible in the multi-class setting and that the reconstruction quality is even higher than in the case of binary classification. Moreover, we show that using weight-decay during training increases the vulnerability to sample reconstruction. Finally, while in the previous work the training set was of size at most $1000$ from $10$ classes, we show preliminary evidence of the ability to reconstruct from a model trained on $5000$ samples from $100$ classes.
SinFusion: Training Diffusion Models on a Single Image or Video
Nov 21, 2022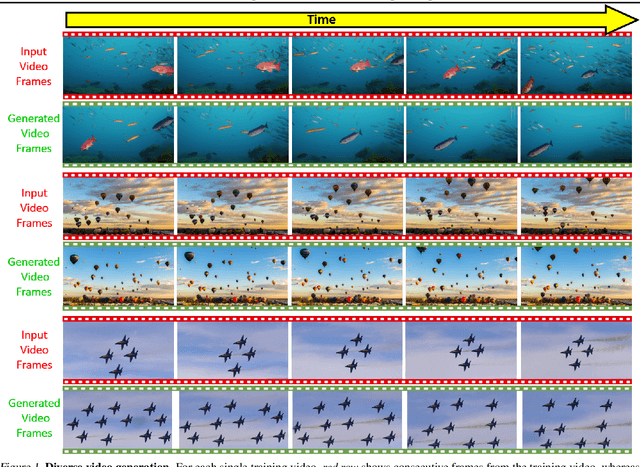

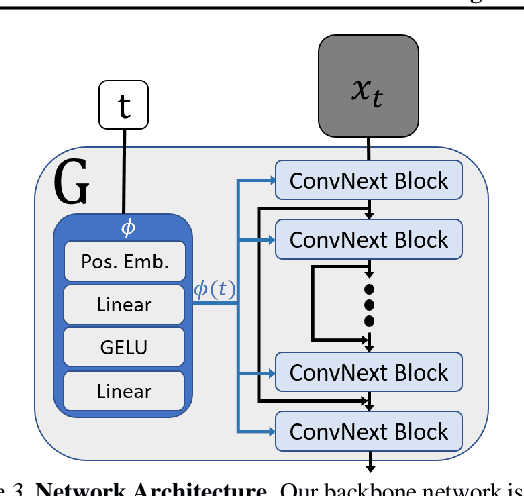
Diffusion models exhibited tremendous progress in image and video generation, exceeding GANs in quality and diversity. However, they are usually trained on very large datasets and are not naturally adapted to manipulate a given input image or video. In this paper we show how this can be resolved by training a diffusion model on a single input image or video. Our image/video-specific diffusion model (SinFusion) learns the appearance and dynamics of the single image or video, while utilizing the conditioning capabilities of diffusion models. It can solve a wide array of image/video-specific manipulation tasks. In particular, our model can learn from few frames the motion and dynamics of a single input video. It can then generate diverse new video samples of the same dynamic scene, extrapolate short videos into long ones (both forward and backward in time) and perform video upsampling. When trained on a single image, our model shows comparable performance and capabilities to previous single-image models in various image manipulation tasks.
Reconstructing Training Data from Trained Neural Networks
Jun 15, 2022
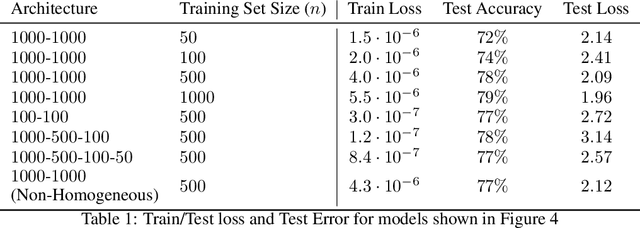
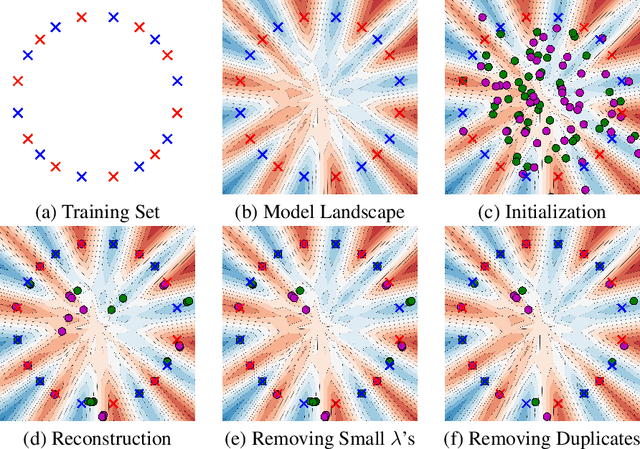
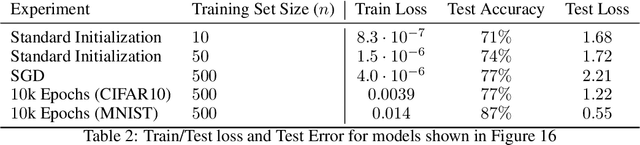
Understanding to what extent neural networks memorize training data is an intriguing question with practical and theoretical implications. In this paper we show that in some cases a significant fraction of the training data can in fact be reconstructed from the parameters of a trained neural network classifier. We propose a novel reconstruction scheme that stems from recent theoretical results about the implicit bias in training neural networks with gradient-based methods. To the best of our knowledge, our results are the first to show that reconstructing a large portion of the actual training samples from a trained neural network classifier is generally possible. This has negative implications on privacy, as it can be used as an attack for revealing sensitive training data. We demonstrate our method for binary MLP classifiers on a few standard computer vision datasets.
Diverse Video Generation from a Single Video
May 11, 2022

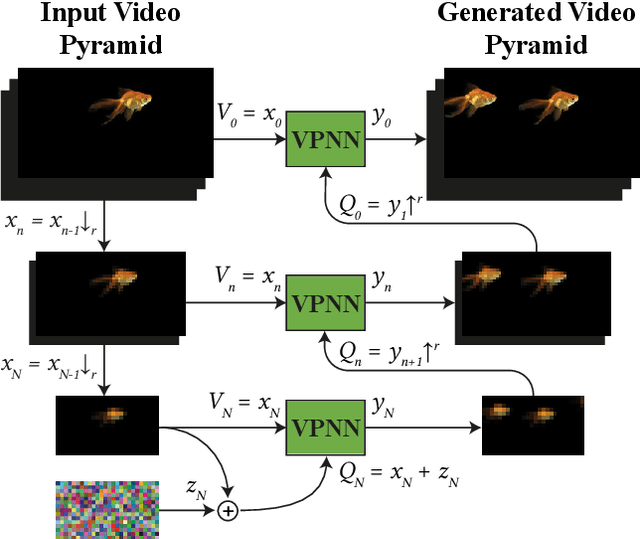
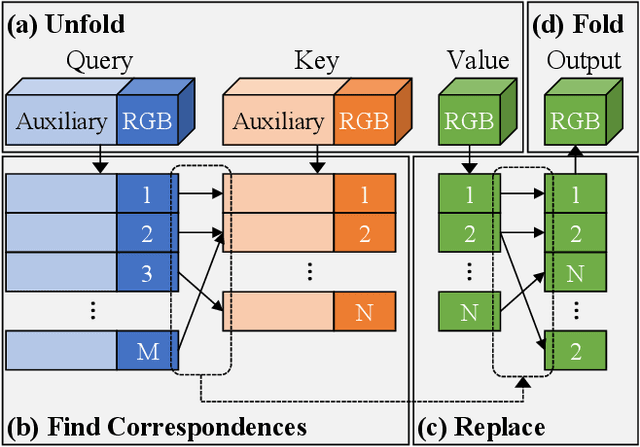
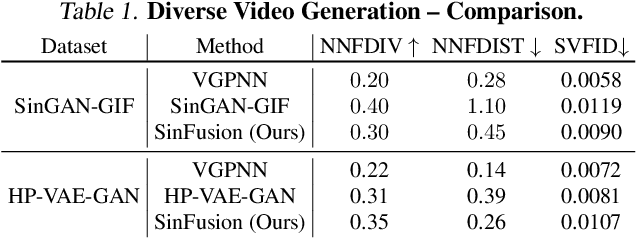
GANs are able to perform generation and manipulation tasks, trained on a single video. However, these single video GANs require unreasonable amount of time to train on a single video, rendering them almost impractical. In this paper we question the necessity of a GAN for generation from a single video, and introduce a non-parametric baseline for a variety of generation and manipulation tasks. We revive classical space-time patches-nearest-neighbors approaches and adapt them to a scalable unconditional generative model, without any learning. This simple baseline surprisingly outperforms single-video GANs in visual quality and realism (confirmed by quantitative and qualitative evaluations), and is disproportionately faster (runtime reduced from several days to seconds). Our approach is easily scaled to Full-HD videos. We also use the same framework to demonstrate video analogies and spatio-temporal retargeting. These observations show that classical approaches significantly outperform heavy deep learning machinery for these tasks. This sets a new baseline for single-video generation and manipulation tasks, and no less important -- makes diverse generation from a single video practically possible for the first time.
Diverse Generation from a Single Video Made Possible
Sep 17, 2021

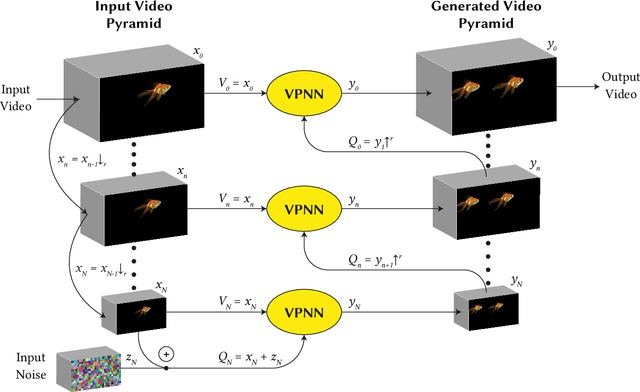
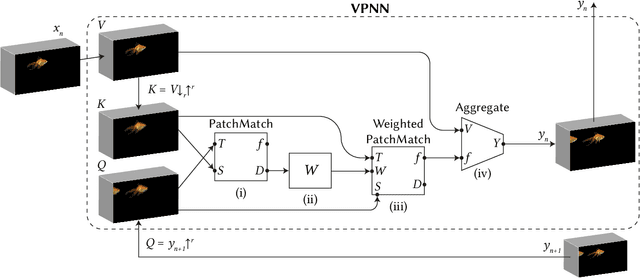
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.
From Discrete to Continuous Convolution Layers
Jun 19, 2020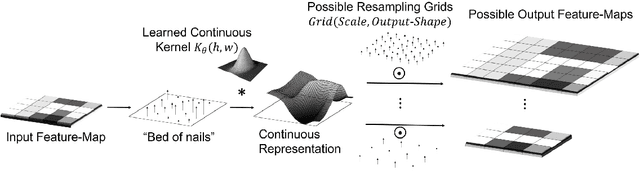
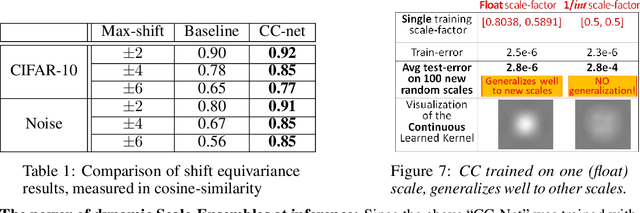
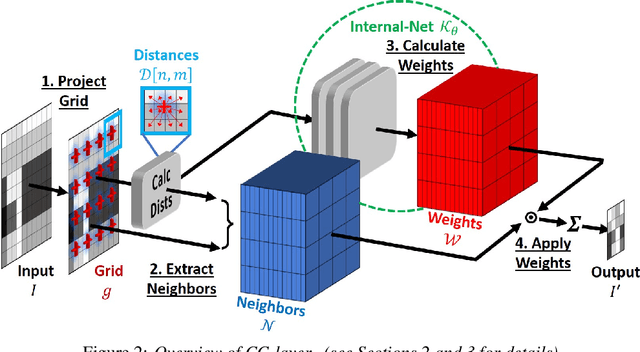

A basic operation in Convolutional Neural Networks (CNNs) is spatial resizing of feature maps. This is done either by strided convolution (donwscaling) or transposed convolution (upscaling). Such operations are limited to a fixed filter moving at predetermined integer steps (strides). Spatial sizes of consecutive layers are related by integer scale factors, predetermined at architectural design, and remain fixed throughout training and inference time. We propose a generalization of the common Conv-layer, from a discrete layer to a Continuous Convolution (CC) Layer. CC Layers naturally extend Conv-layers by representing the filter as a learned continuous function over sub-pixel coordinates. This allows learnable and principled resizing of feature maps, to any size, dynamically and consistently across scales. Once trained, the CC layer can be used to output any scale/size chosen at inference time. The scale can be non-integer and differ between the axes. CC gives rise to new freedoms for architectural design, such as dynamic layer shapes at inference time, or gradual architectures where the size changes by a small factor at each layer. This gives rise to many desired CNN properties, new architectural design capabilities, and useful applications. We further show that current Conv-layers suffer from inherent misalignments, which are ameliorated by CC layers.
Implicit Geometric Regularization for Learning Shapes
Feb 24, 2020
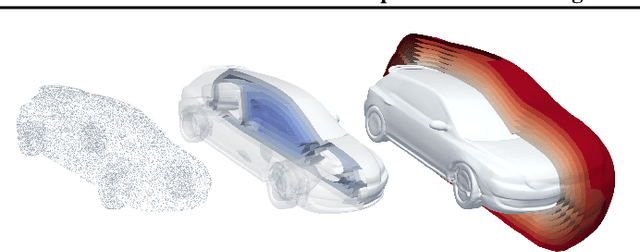
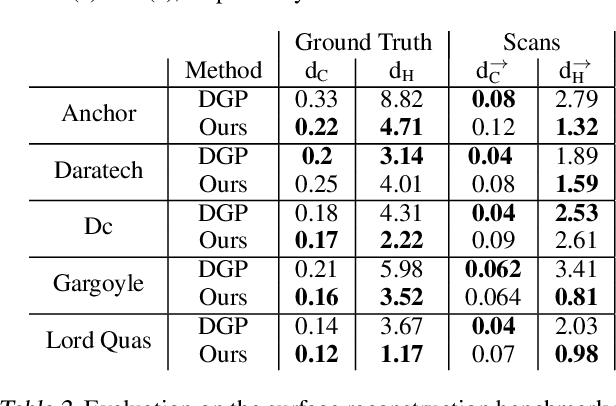

Representing shapes as level sets of neural networks has been recently proved to be useful for different shape analysis and reconstruction tasks So far, such representations were computed using either: (i) pre-computed implicit shape representations; or (ii) loss functions explicitly defined over the neural level sets. In this paper we offer a new paradigm for computing high fidelity implicit neural representations directly from raw data (i.e., point clouds, with or without normal information). We observe that a rather simple loss function, encouraging the neural network to vanish on the input point cloud and to have a unit norm gradient, possesses an implicit geometric regularization property that favors smooth and natural zero level set surfaces, avoiding bad zero-loss solutions. We provide a theoretical analysis of this property for the linear case, and show that, in practice, our method leads to state of the art implicit neural representations with higher level-of-details and fidelity compared to previous methods.
Controlling Neural Level Sets
May 28, 2019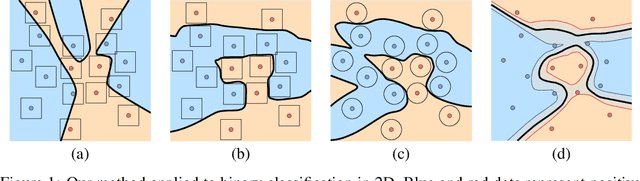

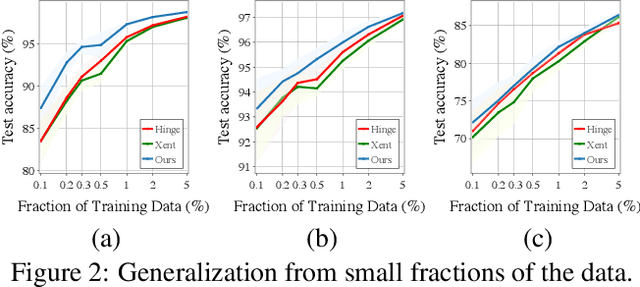
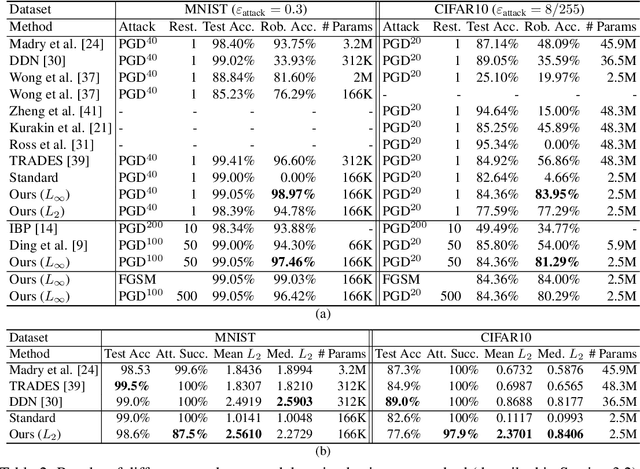
The level sets of neural networks represent fundamental properties such as decision boundaries of classifiers and are used to model non-linear manifold data such as curves and surfaces. Thus, methods for controlling the neural level sets could find many applications in machine learning. In this paper we present a simple and scalable approach to directly control level sets of a deep neural network. Our method consists of two parts: (i) sampling of the neural level sets, and (ii) relating the samples' positions to the network parameters. The latter is achieved by a \emph{sample network} that is constructed by adding a single fixed linear layer to the original network. In turn, the sample network can be used to incorporate the level set samples into a loss function of interest. We have tested our method on three different learning tasks: training networks robust to adversarial attacks, improving generalization to unseen data, and curve and surface reconstruction from point clouds. Notably, we increase robust accuracy to the level of standard classification accuracy in off-the-shelf networks, improving it by 2\% in MNIST and 27\% in CIFAR10 compared to state-of-the-art methods. For surface reconstruction, we produce high fidelity surfaces directly from raw 3D point clouds.