 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Training Data From Real World Models Trained with Transfer Learning
Jul 22, 2024Current methods for reconstructing training data from trained classifiers are restricted to very small models, limited training set sizes, and low-resolution images. Such restrictions hinder their applicability to real-world scenarios. In this paper, we present a novel approach enabling data reconstruction in realistic settings for models trained on high-resolution images. Our method adapts the reconstruction scheme of arXiv:2206.07758 to real-world scenarios -- specifically, targeting models trained via transfer learning over image embeddings of large pre-trained models like DINO-ViT and CLIP. Our work employs data reconstruction in the embedding space rather than in the image space, showcasing its applicability beyond visual data. Moreover, we introduce a novel clustering-based method to identify good reconstructions from thousands of candidates. This significantly improves on previous works that relied on knowledge of the training set to identify good reconstructed images. Our findings shed light on a potential privacy risk for data leakage from models trained using transfer learning.
Combining Internal and External Constraints for Unrolling Shutter in Videos
Jul 24, 2022
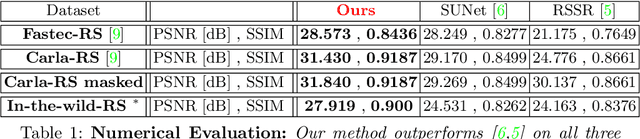

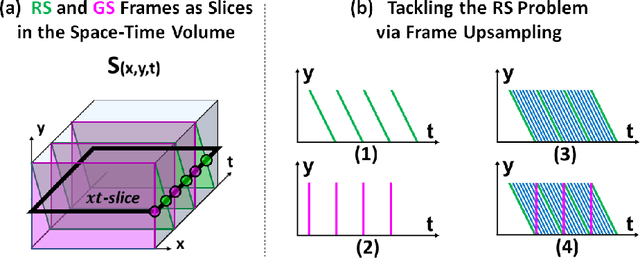
Videos obtained by rolling-shutter (RS) cameras result in spatially-distorted frames. These distortions become significant under fast camera/scene motions. Undoing effects of RS is sometimes addressed as a spatial problem, where objects need to be rectified/displaced in order to generate their correct global shutter (GS) frame. However, the cause of the RS effect is inherently temporal, not spatial. In this paper we propose a space-time solution to the RS problem. We observe that despite the severe differences between their xy frames, a RS video and its corresponding GS video tend to share the exact same xt slices -- up to a known sub-frame temporal shift. Moreover, they share the same distribution of small 2D xt-patches, despite the strong temporal aliasing within each video. This allows to constrain the GS output video using video-specific constraints imposed by the RS input video. Our algorithm is composed of 3 main components: (i) Dense temporal upsampling between consecutive RS frames using an off-the-shelf method, (which was trained on regular video sequences), from which we extract GS "proposals". (ii) Learning to correctly merge an ensemble of such GS "proposals" using a dedicated MergeNet. (iii) A video-specific zero-shot optimization which imposes the similarity of xt-patches between the GS output video and the RS input video. Our method obtains state-of-the-art results on benchmark datasets, both numerically and visually, despite being trained on a small synthetic RS/GS dataset. Moreover, it generalizes well to new complex RS videos with motion types outside the distribution of the training set (e.g., complex non-rigid motions) -- videos which competing methods trained on much more data cannot handle well. We attribute these generalization capabilities to the combination of external and internal constraints.