 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Internal and External Constraints for Unrolling Shutter in Videos
Jul 24, 2022
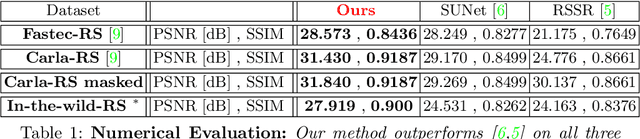

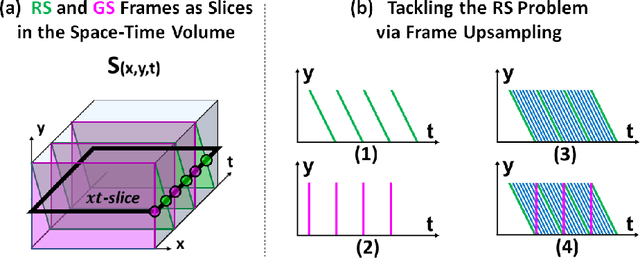
Videos obtained by rolling-shutter (RS) cameras result in spatially-distorted frames. These distortions become significant under fast camera/scene motions. Undoing effects of RS is sometimes addressed as a spatial problem, where objects need to be rectified/displaced in order to generate their correct global shutter (GS) frame. However, the cause of the RS effect is inherently temporal, not spatial. In this paper we propose a space-time solution to the RS problem. We observe that despite the severe differences between their xy frames, a RS video and its corresponding GS video tend to share the exact same xt slices -- up to a known sub-frame temporal shift. Moreover, they share the same distribution of small 2D xt-patches, despite the strong temporal aliasing within each video. This allows to constrain the GS output video using video-specific constraints imposed by the RS input video. Our algorithm is composed of 3 main components: (i) Dense temporal upsampling between consecutive RS frames using an off-the-shelf method, (which was trained on regular video sequences), from which we extract GS "proposals". (ii) Learning to correctly merge an ensemble of such GS "proposals" using a dedicated MergeNet. (iii) A video-specific zero-shot optimization which imposes the similarity of xt-patches between the GS output video and the RS input video. Our method obtains state-of-the-art results on benchmark datasets, both numerically and visually, despite being trained on a small synthetic RS/GS dataset. Moreover, it generalizes well to new complex RS videos with motion types outside the distribution of the training set (e.g., complex non-rigid motions) -- videos which competing methods trained on much more data cannot handle well. We attribute these generalization capabilities to the combination of external and internal constraints.
Across Scales \& Across Dimensions: Temporal Super-Resolution using Deep Internal Learning
Mar 19, 2020When a very fast dynamic event is recorded with a low-framerate camera, the resulting video suffers from severe motion blur (due to exposure time) and motion aliasing (due to low sampling rate in time). True Temporal Super-Resolution (TSR) is more than just Temporal-Interpolation (increasing framerate). It can also recover new high temporal frequencies beyond the temporal Nyquist limit of the input video, thus resolving both motion-blur and motion-aliasing effects that temporal frame interpolation (as sophisticated as it maybe) cannot undo. In this paper we propose a "Deep Internal Learning" approach for true TSR. We train a video-specific CNN on examples extracted directly from the low-framerate input video. Our method exploits the strong recurrence of small space-time patches inside a single video sequence, both within and across different spatio-temporal scales of the video. We further observe (for the first time) that small space-time patches recur also across-dimensions of the video sequence - i.e., by swapping the spatial and temporal dimensions. In particular, the higher spatial resolution of video frames provides strong examples as to how to increase the temporal resolution of that video. Such internal video-specific examples give rise to strong self-supervision, requiring no data but the input video itself. This results in Zero-Shot Temporal-SR of complex videos, which removes both motion blur and motion aliasing, outperforming previous supervised methods trained on external video datasets.