 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modal Distillation for Flood Extent Mapping
Feb 16, 2023The increasing intensity and frequency of floods is one of the many consequences of our changing climate. In this work, we explore ML techniques that improve the flood detection module of an operational early flood warning system. Our method exploits an unlabelled dataset of paired multi-spectral and Synthetic Aperture Radar (SAR) imagery to reduce the labeling requirements of a purely supervised learning method. Prior works have used unlabelled data by creating weak labels out of them. However, from our experiments we noticed that such a model still ends up learning the label mistakes in those weak labels. Motivated by knowledge distillation and semi supervised learning, we explore the use of a teacher to train a student with the help of a small hand labelled dataset and a large unlabelled dataset. Unlike the conventional self distillation setup, we propose a cross modal distillation framework that transfers supervision from a teacher trained on richer modality (multi-spectral images) to a student model trained on SAR imagery. The trained models are then tested on the Sen1Floods11 dataset. Our model outperforms the Sen1Floods11 baseline model trained on the weak labeled SAR imagery by an absolute margin of 6.53% Intersection-over-Union (IoU) on the test split.
Diverse Video Generation from a Single Video
May 11, 2022

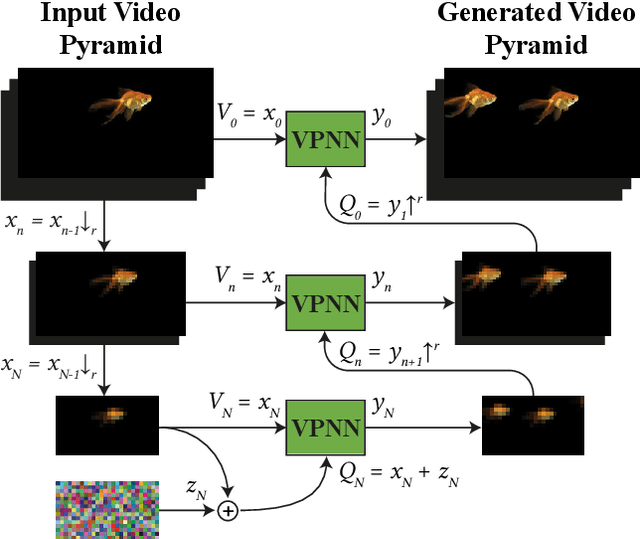
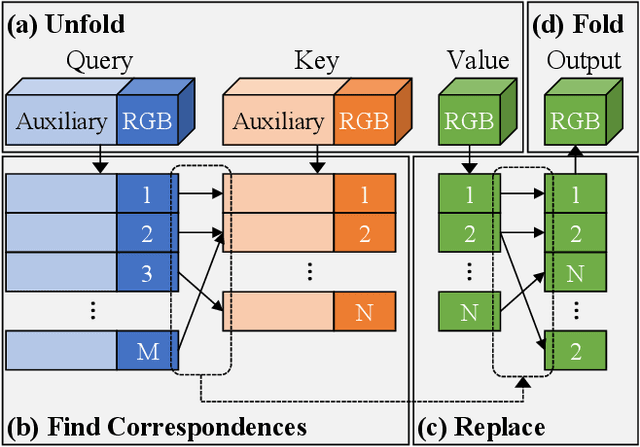
GANs are able to perform generation and manipulation tasks, trained on a single video. However, these single video GANs require unreasonable amount of time to train on a single video, rendering them almost impractical. In this paper we question the necessity of a GAN for generation from a single video, and introduce a non-parametric baseline for a variety of generation and manipulation tasks. We revive classical space-time patches-nearest-neighbors approaches and adapt them to a scalable unconditional generative model, without any learning. This simple baseline surprisingly outperforms single-video GANs in visual quality and realism (confirmed by quantitative and qualitative evaluations), and is disproportionately faster (runtime reduced from several days to seconds). Our approach is easily scaled to Full-HD videos. We also use the same framework to demonstrate video analogies and spatio-temporal retargeting. These observations show that classical approaches significantly outperform heavy deep learning machinery for these tasks. This sets a new baseline for single-video generation and manipulation tasks, and no less important -- makes diverse generation from a single video practically possible for the first time.
Diverse Generation from a Single Video Made Possible
Sep 17, 2021

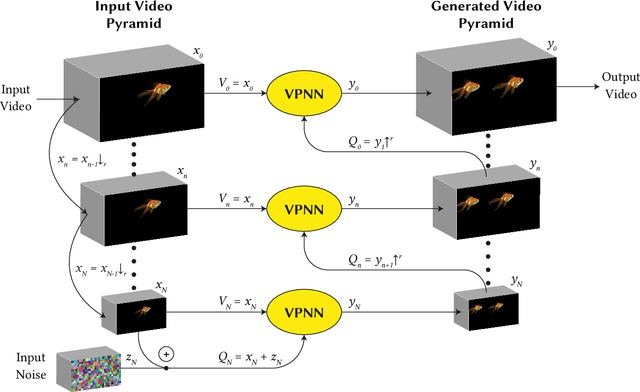
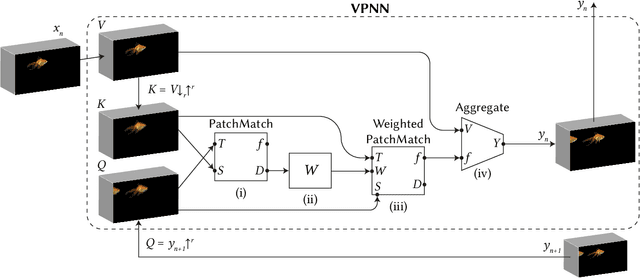
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.
Drop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
Mar 29, 2021
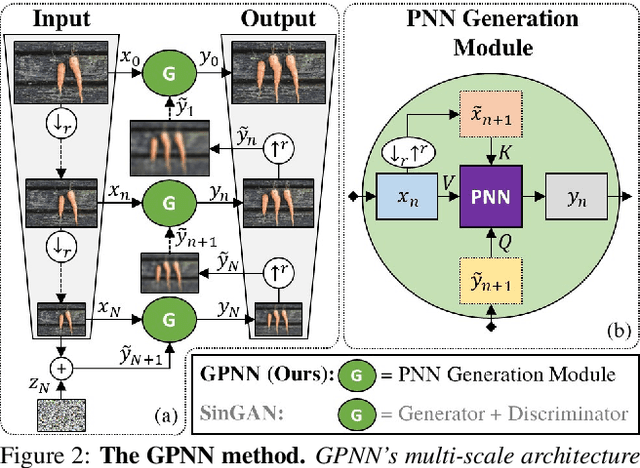
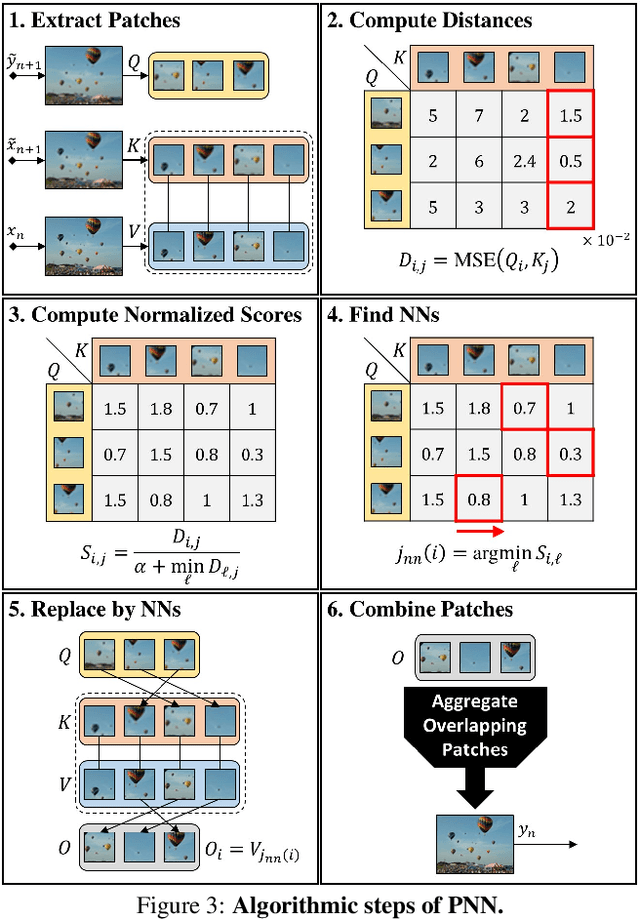

Single image generative models perform synthesis and manipulation tasks by capturing the distribution of patches within a single image. The classical (pre Deep Learning) prevailing approaches for these tasks are based on an optimization process that maximizes patch similarity between the input and generated output. Recently, however, Single Image GANs were introduced both as a superior solution for such manipulation tasks, but also for remarkable novel generative tasks. Despite their impressiveness, single image GANs require long training time (usually hours) for each image and each task. They often suffer from artifacts and are prone to optimization issues such as mode collapse. In this paper, we show that all of these tasks can be performed without any training, within several seconds, in a unified, surprisingly simple framework. We revisit and cast the "good-old" patch-based methods into a novel optimization-free framework. We start with an initial coarse guess, and then simply refine the details coarse-to-fine using patch-nearest-neighbor search. This allows generating random novel images better and much faster than GANs. We further demonstrate a wide range of applications, such as image editing and reshuffling, retargeting to different sizes, structural analogies, image collage and a newly introduced task of conditional inpainting. Not only is our method faster ($\times 10^3$-$\times 10^4$ than a GAN), it produces superior results (confirmed by quantitative and qualitative evaluation), less artifacts and more realistic global structure than any of the previous approaches (whether GAN-based or classical patch-based).
From Discrete to Continuous Convolution Layers
Jun 19, 2020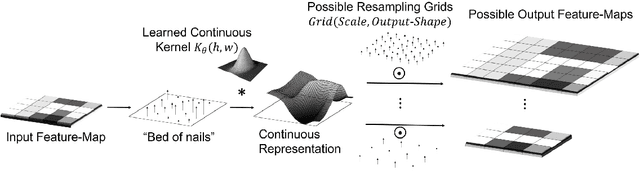
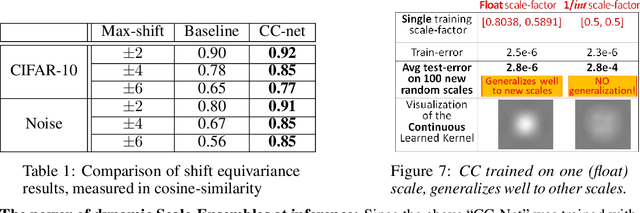
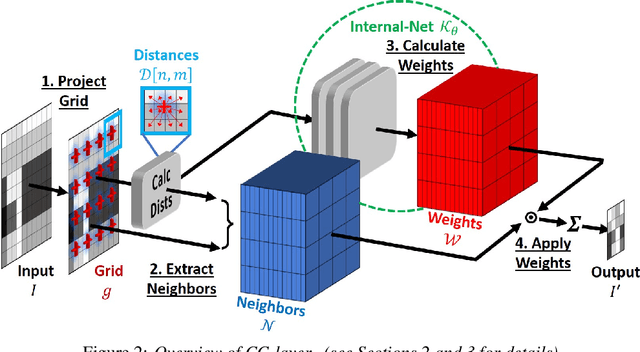

A basic operation in Convolutional Neural Networks (CNNs) is spatial resizing of feature maps. This is done either by strided convolution (donwscaling) or transposed convolution (upscaling). Such operations are limited to a fixed filter moving at predetermined integer steps (strides). Spatial sizes of consecutive layers are related by integer scale factors, predetermined at architectural design, and remain fixed throughout training and inference time. We propose a generalization of the common Conv-layer, from a discrete layer to a Continuous Convolution (CC) Layer. CC Layers naturally extend Conv-layers by representing the filter as a learned continuous function over sub-pixel coordinates. This allows learnable and principled resizing of feature maps, to any size, dynamically and consistently across scales. Once trained, the CC layer can be used to output any scale/size chosen at inference time. The scale can be non-integer and differ between the axes. CC gives rise to new freedoms for architectural design, such as dynamic layer shapes at inference time, or gradual architectures where the size changes by a small factor at each layer. This gives rise to many desired CNN properties, new architectural design capabilities, and useful applications. We further show that current Conv-layers suffer from inherent misalignments, which are ameliorated by CC layers.