 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
Paper and Code
Mar 29, 2021
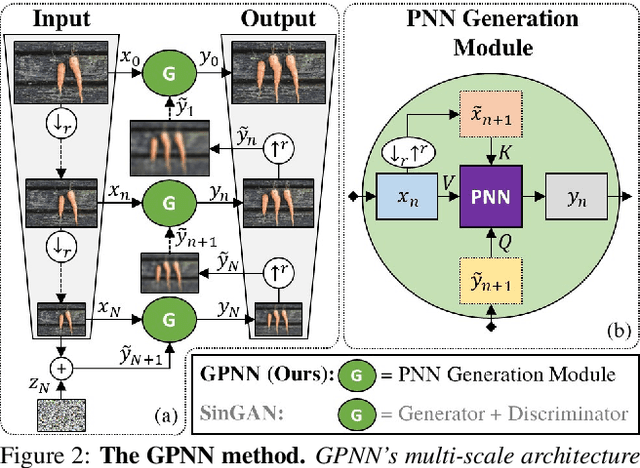
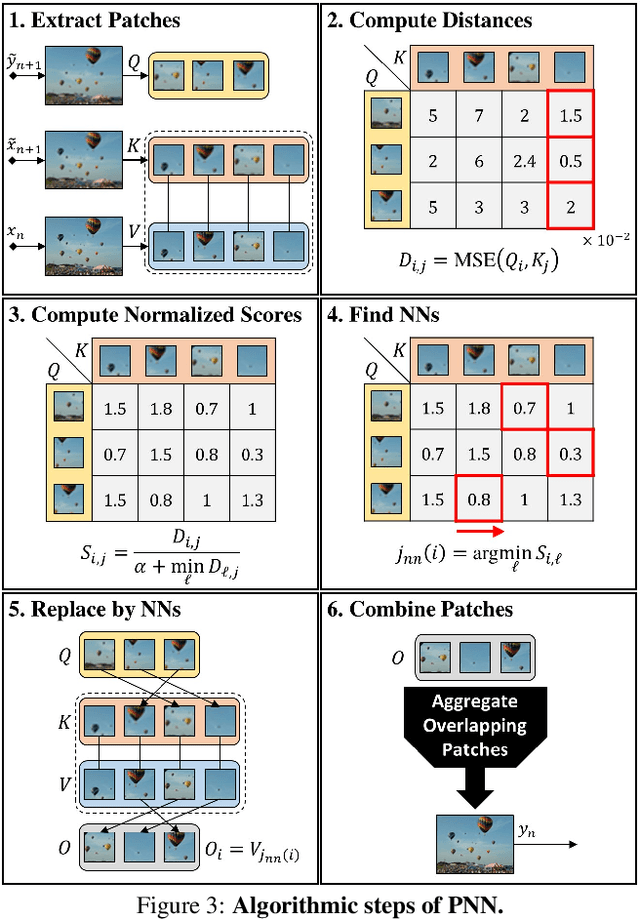

Single image generative models perform synthesis and manipulation tasks by capturing the distribution of patches within a single image. The classical (pre Deep Learning) prevailing approaches for these tasks are based on an optimization process that maximizes patch similarity between the input and generated output. Recently, however, Single Image GANs were introduced both as a superior solution for such manipulation tasks, but also for remarkable novel generative tasks. Despite their impressiveness, single image GANs require long training time (usually hours) for each image and each task. They often suffer from artifacts and are prone to optimization issues such as mode collapse. In this paper, we show that all of these tasks can be performed without any training, within several seconds, in a unified, surprisingly simple framework. We revisit and cast the "good-old" patch-based methods into a novel optimization-free framework. We start with an initial coarse guess, and then simply refine the details coarse-to-fine using patch-nearest-neighbor search. This allows generating random novel images better and much faster than GANs. We further demonstrate a wide range of applications, such as image editing and reshuffling, retargeting to different sizes, structural analogies, image collage and a newly introduced task of conditional inpainting. Not only is our method faster ($\times 10^3$-$\times 10^4$ than a GAN), it produces superior results (confirmed by quantitative and qualitative evaluation), less artifacts and more realistic global structure than any of the previous approaches (whether GAN-based or classical patch-based).