 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
Cross Modal Distillation for Flood Extent Mapping
Feb 16, 2023The increasing intensity and frequency of floods is one of the many consequences of our changing climate. In this work, we explore ML techniques that improve the flood detection module of an operational early flood warning system. Our method exploits an unlabelled dataset of paired multi-spectral and Synthetic Aperture Radar (SAR) imagery to reduce the labeling requirements of a purely supervised learning method. Prior works have used unlabelled data by creating weak labels out of them. However, from our experiments we noticed that such a model still ends up learning the label mistakes in those weak labels. Motivated by knowledge distillation and semi supervised learning, we explore the use of a teacher to train a student with the help of a small hand labelled dataset and a large unlabelled dataset. Unlike the conventional self distillation setup, we propose a cross modal distillation framework that transfers supervision from a teacher trained on richer modality (multi-spectral images) to a student model trained on SAR imagery. The trained models are then tested on the Sen1Floods11 dataset. Our model outperforms the Sen1Floods11 baseline model trained on the weak labeled SAR imagery by an absolute margin of 6.53% Intersection-over-Union (IoU) on the test split.
MSN: Efficient Online Mask Selection Network for Video Instance Segmentation
Jun 19, 2021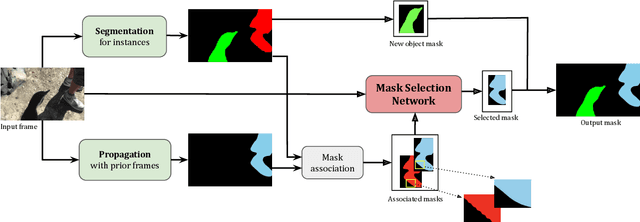


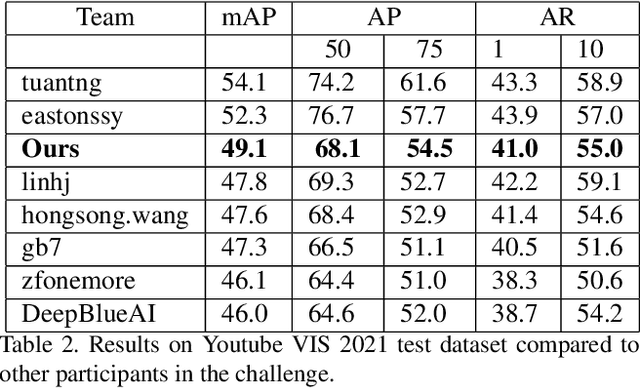
In this work we present a novel solution for Video Instance Segmentation(VIS), that is automatically generating instance level segmentation masks along with object class and tracking them in a video. Our method improves the masks from segmentation and propagation branches in an online manner using the Mask Selection Network (MSN) hence limiting the noise accumulation during mask tracking. We propose an effective design of MSN by using patch-based convolutional neural network. The network is able to distinguish between very subtle differences between the masks and choose the better masks out of the associated masks accurately. Further, we make use of temporal consistency and process the video sequences in both forward and reverse manner as a post processing step to recover lost objects. The proposed method can be used to adapt any video object segmentation method for the task of VIS. Our method achieves a score of 49.1 mAP on 2021 YouTube-VIS Challenge and was ranked third place among more than 30 global teams. Our code will be available at https://github.com/SHI-Labs/Mask-Selection-Networks.
MonoLayout: Amodal scene layout from a single image
Feb 19, 2020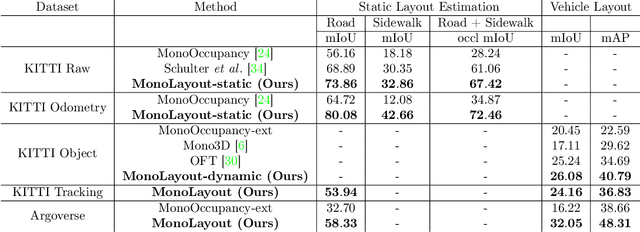
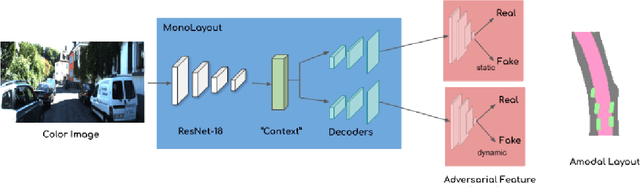
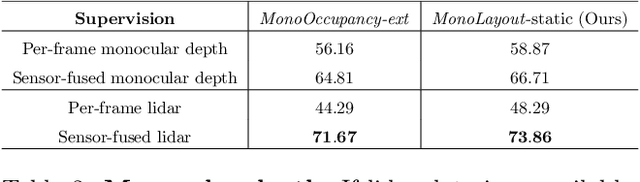
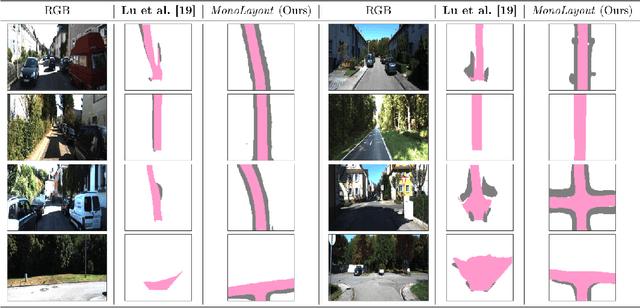
In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird's-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem amodal scene layout estimation, which involves "hallucinating" scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. Due to the lack of fair baseline methods, we extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird's-eye view to the amodal setup for rigorous evaluation. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets. On the KITTI and Argoverse datasets, we outperform all baselines by a significant margin. We also make all our annotations, and code publicly available. A video abstract of this paper is available https://www.youtube.com/watch?v=HcroGyo6yRQ .