 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Physical Understanding in Video Generation: A 3D Point Regularization Approach
Feb 05, 2025We present a novel video generation framework that integrates 3-dimensional geometry and dynamic awareness. To achieve this, we augment 2D videos with 3D point trajectories and align them in pixel space. The resulting 3D-aware video dataset, PointVid, is then used to fine-tune a latent diffusion model, enabling it to track 2D objects with 3D Cartesian coordinates. Building on this, we regularize the shape and motion of objects in the video to eliminate undesired artifacts, \eg, nonphysical deformation. Consequently, we enhance the quality of generated RGB videos and alleviate common issues like object morphing, which are prevalent in current video models due to a lack of shape awareness. With our 3D augmentation and regularization, our model is capable of handling contact-rich scenarios such as task-oriented videos. These videos involve complex interactions of solids, where 3D information is essential for perceiving deformation and contact. Furthermore, our model improves the overall quality of video generation by promoting the 3D consistency of moving objects and reducing abrupt changes in shape and motion.
Wonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024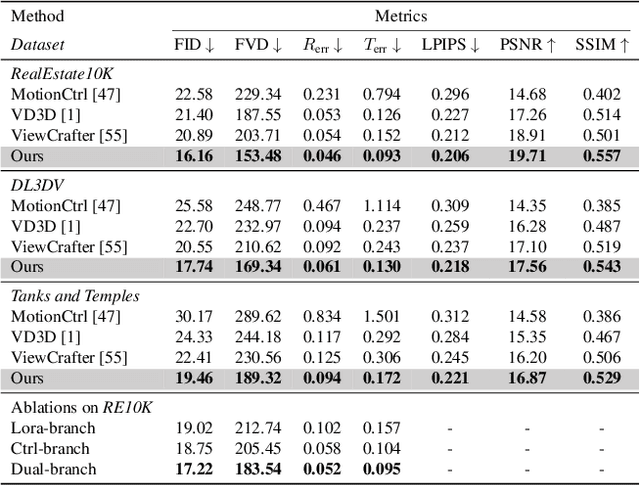
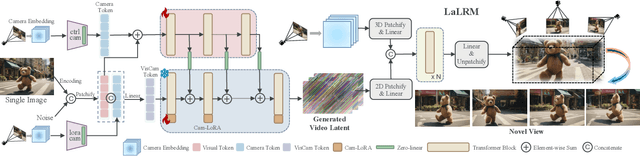
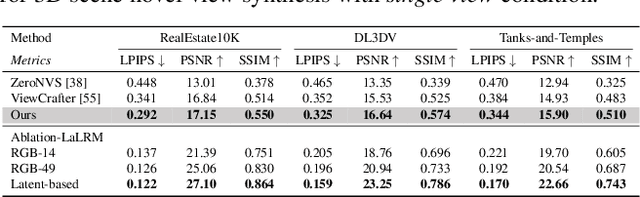

This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
Lightweight Predictive 3D Gaussian Splats
Jun 27, 2024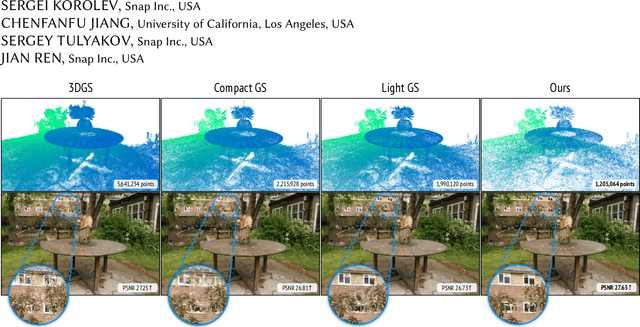
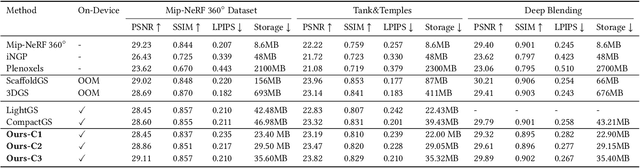
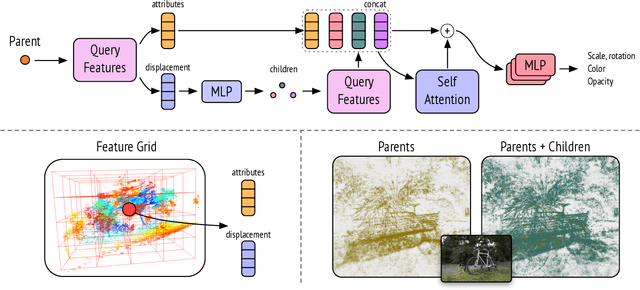

Recent approaches representing 3D objects and scenes using Gaussian splats show increased rendering speed across a variety of platforms and devices. While rendering such representations is indeed extremely efficient, storing and transmitting them is often prohibitively expensive. To represent large-scale scenes, one often needs to store millions of 3D Gaussians, occupying gigabytes of disk space. This poses a very practical limitation, prohibiting widespread adoption.Several solutions have been proposed to strike a balance between disk size and rendering quality, noticeably reducing the visual quality. In this work, we propose a new representation that dramatically reduces the hard drive footprint while featuring similar or improved quality when compared to the standard 3D Gaussian splats. When compared to other compact solutions, ours offers higher quality renderings with significantly reduced storage, being able to efficiently run on a mobile device in real-time. Our key observation is that nearby points in the scene can share similar representations. Hence, only a small ratio of 3D points needs to be stored. We introduce an approach to identify such points which are called parent points. The discarded points called children points along with attributes can be efficiently predicted by tiny MLPs.
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Apr 11, 2024



Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos
Jan 04, 2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object's appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities. Further details, code and examples are available on our project page: https://helia95.github.io/vase-website/
Video Instance Matting
Nov 08, 2023Conventional video matting outputs one alpha matte for all instances appearing in a video frame so that individual instances are not distinguished. While video instance segmentation provides time-consistent instance masks, results are unsatisfactory for matting applications, especially due to applied binarization. To remedy this deficiency, we propose Video Instance Matting~(VIM), that is, estimating alpha mattes of each instance at each frame of a video sequence. To tackle this challenging problem, we present MSG-VIM, a Mask Sequence Guided Video Instance Matting neural network, as a novel baseline model for VIM. MSG-VIM leverages a mixture of mask augmentations to make predictions robust to inaccurate and inconsistent mask guidance. It incorporates temporal mask and temporal feature guidance to improve the temporal consistency of alpha matte predictions. Furthermore, we build a new benchmark for VIM, called VIM50, which comprises 50 video clips with multiple human instances as foreground objects. To evaluate performances on the VIM task, we introduce a suitable metric called Video Instance-aware Matting Quality~(VIMQ). Our proposed model MSG-VIM sets a strong baseline on the VIM50 benchmark and outperforms existing methods by a large margin. The project is open-sourced at https://github.com/SHI-Labs/VIM.
Interactive Neural Painting
Jul 31, 2023



In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
PAIR-Diffusion: Object-Level Image Editing with Structure-and-Appearance Paired Diffusion Models
Mar 30, 2023Image editing using diffusion models has witnessed extremely fast-paced growth recently. There are various ways in which previous works enable controlling and editing images. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we consider an image as a composition of multiple objects, each defined by various properties. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose Structure-and-Appearance Paired Diffusion model (PAIR-Diffusion), which is trained using structure and appearance information explicitly extracted from the images. The proposed model enables users to inject a reference image's appearance into the input image at both the object and global levels. Additionally, PAIR-Diffusion allows editing the structure while maintaining the style of individual components of the image unchanged. We extensively evaluate our method on LSUN datasets and the CelebA-HQ face dataset, and we demonstrate fine-grained control over both structure and appearance at the object level. We also applied the method to Stable Diffusion to edit any real image at the object level.
VMFormer: End-to-End Video Matting with Transformer
Aug 26, 2022
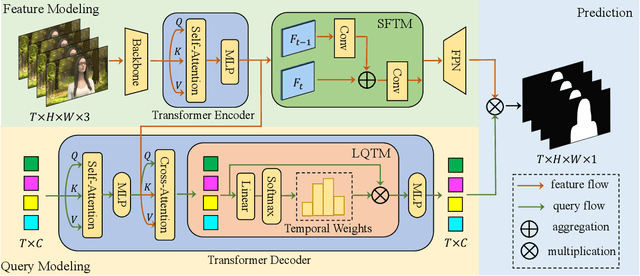

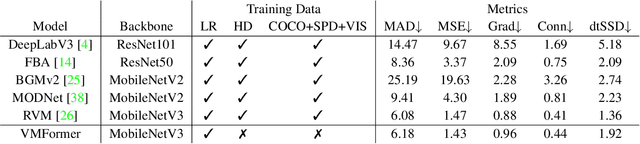
Video matting aims to predict the alpha mattes for each frame from a given input video sequence. Recent solutions to video matting have been dominated by deep convolutional neural networks (CNN) for the past few years, which have become the de-facto standard for both academia and industry. However, they have inbuilt inductive bias of locality and do not capture global characteristics of an image due to the CNN-based architectures. They also lack long-range temporal modeling considering computational costs when dealing with feature maps of multiple frames. In this paper, we propose VMFormer: a transformer-based end-to-end method for video matting. It makes predictions on alpha mattes of each frame from learnable queries given a video input sequence. Specifically, it leverages self-attention layers to build global integration of feature sequences with short-range temporal modeling on successive frames. We further apply queries to learn global representations through cross-attention in the transformer decoder with long-range temporal modeling upon all queries. In the prediction stage, both queries and corresponding feature maps are used to make the final prediction of alpha matte. Experiments show that VMFormer outperforms previous CNN-based video matting methods on the composited benchmarks. To our best knowledge, it is the first end-to-end video matting solution built upon a full vision transformer with predictions on the learnable queries. The project is open-sourced at https://chrisjuniorli.github.io/project/VMFormer/
VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution
Jun 09, 2022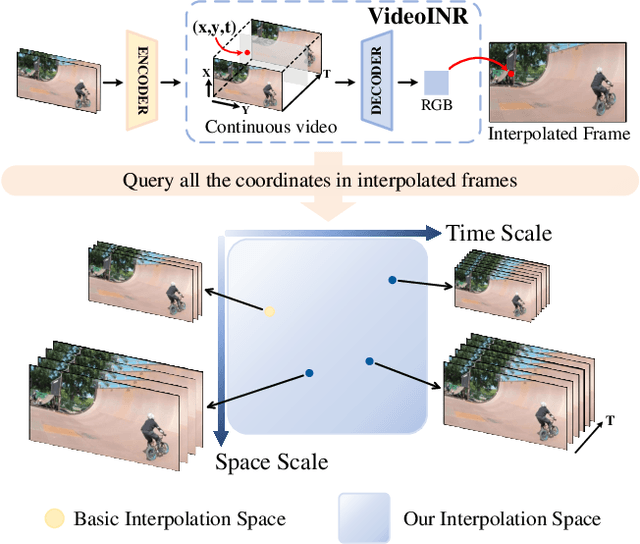
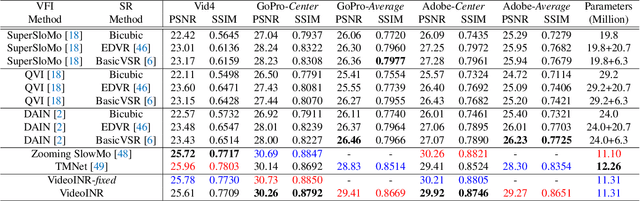
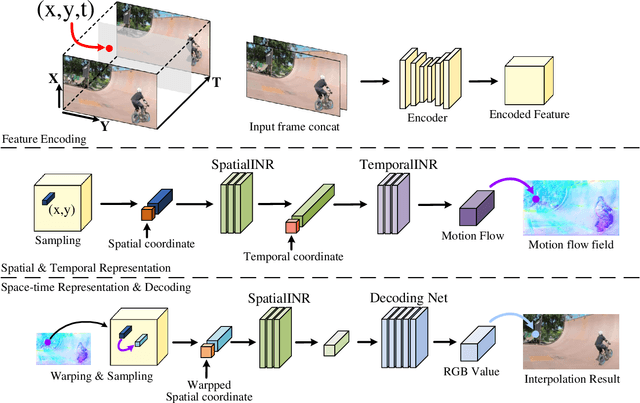
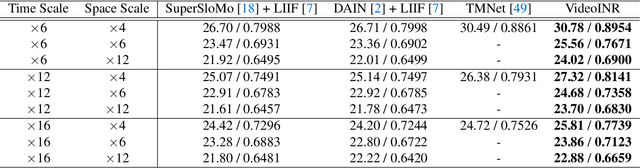
Videos typically record the streaming and continuous visual data as discrete consecutive frames. Since the storage cost is expensive for videos of high fidelity, most of them are stored in a relatively low resolution and frame rate. Recent works of Space-Time Video Super-Resolution (STVSR) are developed to incorporate temporal interpolation and spatial super-resolution in a unified framework. However, most of them only support a fixed up-sampling scale, which limits their flexibility and applications. In this work, instead of following the discrete representations, we propose Video Implicit Neural Representation (VideoINR), and we show its applications for STVSR. The learned implicit neural representation can be decoded to videos of arbitrary spatial resolution and frame rate. We show that VideoINR achieves competitive performances with state-of-the-art STVSR methods on common up-sampling scales and significantly outperforms prior works on continuous and out-of-training-distribution scales. Our project page is at http://zeyuan-chen.com/VideoINR/ .