 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
Mar 21, 2024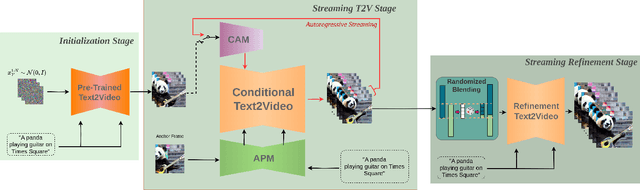
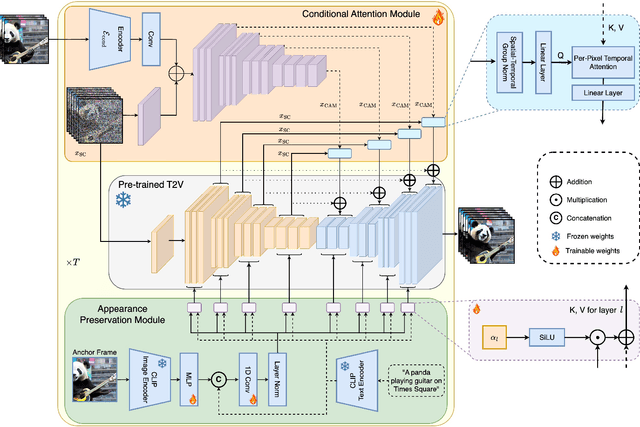


Text-to-video diffusion models enable the generation of high-quality videos that follow text instructions, making it easy to create diverse and individual content. However, existing approaches mostly focus on high-quality short video generation (typically 16 or 24 frames), ending up with hard-cuts when naively extended to the case of long video synthesis. To overcome these limitations, we introduce StreamingT2V, an autoregressive approach for long video generation of 80, 240, 600, 1200 or more frames with smooth transitions. The key components are:(i) a short-term memory block called conditional attention module (CAM), which conditions the current generation on the features extracted from the previous chunk via an attentional mechanism, leading to consistent chunk transitions, (ii) a long-term memory block called appearance preservation module, which extracts high-level scene and object features from the first video chunk to prevent the model from forgetting the initial scene, and (iii) a randomized blending approach that enables to apply a video enhancer autoregressively for infinitely long videos without inconsistencies between chunks. Experiments show that StreamingT2V generates high motion amount. In contrast, all competing image-to-video methods are prone to video stagnation when applied naively in an autoregressive manner. Thus, we propose with StreamingT2V a high-quality seamless text-to-long video generator that outperforms competitors with consistency and motion. Our code will be available at: https://github.com/Picsart-AI-Research/StreamingT2V
Video Instance Matting
Nov 08, 2023Conventional video matting outputs one alpha matte for all instances appearing in a video frame so that individual instances are not distinguished. While video instance segmentation provides time-consistent instance masks, results are unsatisfactory for matting applications, especially due to applied binarization. To remedy this deficiency, we propose Video Instance Matting~(VIM), that is, estimating alpha mattes of each instance at each frame of a video sequence. To tackle this challenging problem, we present MSG-VIM, a Mask Sequence Guided Video Instance Matting neural network, as a novel baseline model for VIM. MSG-VIM leverages a mixture of mask augmentations to make predictions robust to inaccurate and inconsistent mask guidance. It incorporates temporal mask and temporal feature guidance to improve the temporal consistency of alpha matte predictions. Furthermore, we build a new benchmark for VIM, called VIM50, which comprises 50 video clips with multiple human instances as foreground objects. To evaluate performances on the VIM task, we introduce a suitable metric called Video Instance-aware Matting Quality~(VIMQ). Our proposed model MSG-VIM sets a strong baseline on the VIM50 benchmark and outperforms existing methods by a large margin. The project is open-sourced at https://github.com/SHI-Labs/VIM.
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Mar 23, 2023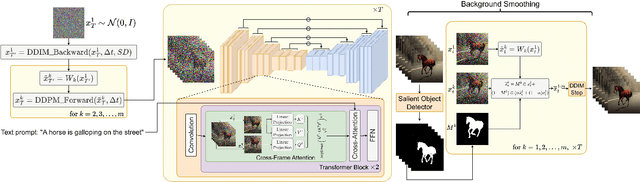

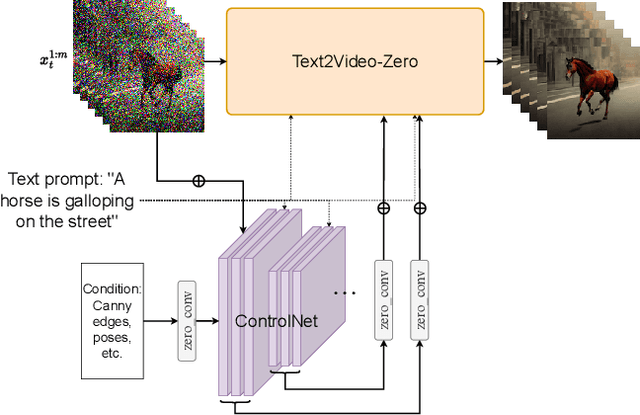

Recent text-to-video generation approaches rely on computationally heavy training and require large-scale video datasets. In this paper, we introduce a new task of zero-shot text-to-video generation and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g., Stable Diffusion), making them suitable for the video domain. Our key modifications include (i) enriching the latent codes of the generated frames with motion dynamics to keep the global scene and the background time consistent; and (ii) reprogramming frame-level self-attention using a new cross-frame attention of each frame on the first frame, to preserve the context, appearance, and identity of the foreground object. Experiments show that this leads to low overhead, yet high-quality and remarkably consistent video generation. Moreover, our approach is not limited to text-to-video synthesis but is also applicable to other tasks such as conditional and content-specialized video generation, and Video Instruct-Pix2Pix, i.e., instruction-guided video editing. As experiments show, our method performs comparably or sometimes better than recent approaches, despite not being trained on additional video data. Our code will be open sourced at: https://github.com/Picsart-AI-Research/Text2Video-Zero .
LMGP: Lifted Multicut Meets Geometry Projections for Multi-Camera Multi-Object Tracking
Nov 23, 2021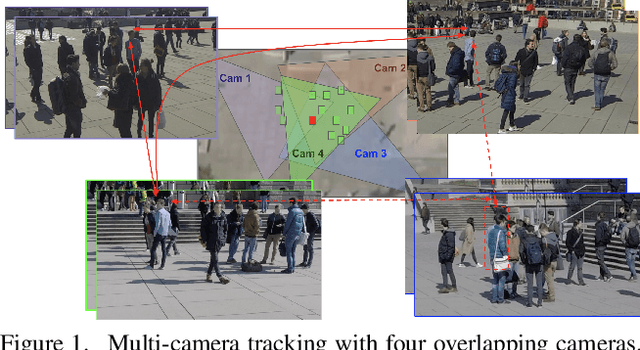


Multi-Camera Multi-Object Tracking is currently drawing attention in the computer vision field due to its superior performance in real-world applications such as video surveillance with crowded scenes or in vast space. In this work, we propose a mathematically elegant multi-camera multiple object tracking approach based on a spatial-temporal lifted multicut formulation. Our model utilizes state-of-the-art tracklets produced by single-camera trackers as proposals. As these tracklets may contain ID-Switch errors, we refine them through a novel pre-clustering obtained from 3D geometry projections. As a result, we derive a better tracking graph without ID switches and more precise affinity costs for the data association phase. Tracklets are then matched to multi-camera trajectories by solving a global lifted multicut formulation that incorporates short and long-range temporal interactions on tracklets located in the same camera as well as inter-camera ones. Experimental results on the WildTrack dataset yield near-perfect result, outperforming state-of-the-art trackers on Campus while being on par on the PETS-09 dataset. We will make our implementations available upon acceptance of the paper.
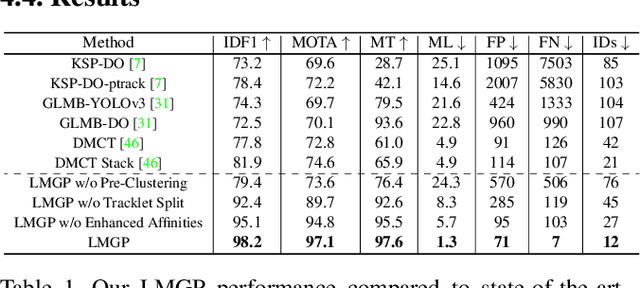
Making Higher Order MOT Scalable: An Efficient Approximate Solver for Lifted Disjoint Paths
Aug 24, 2021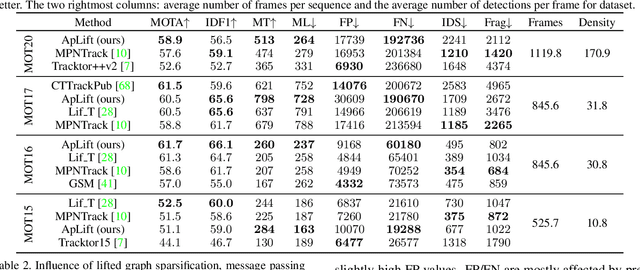
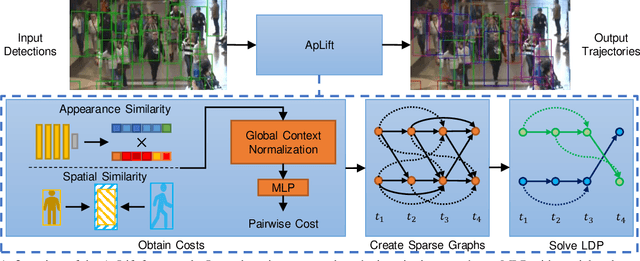
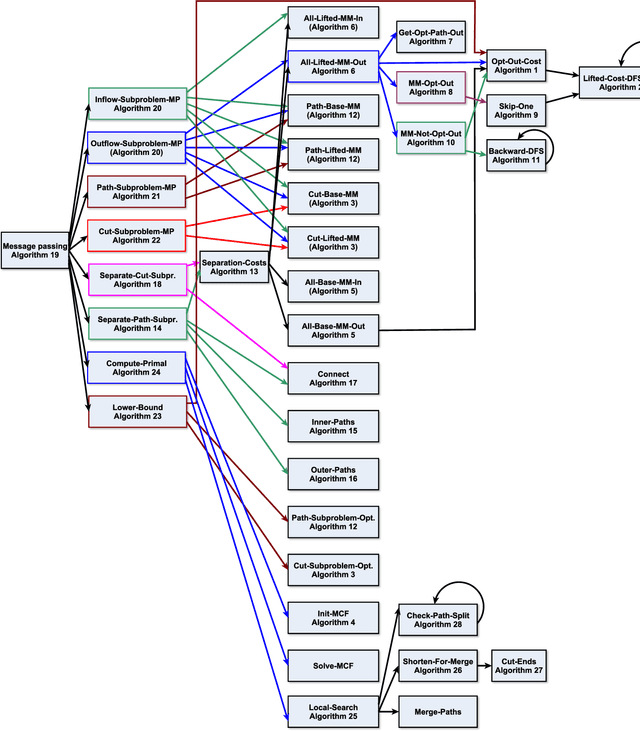
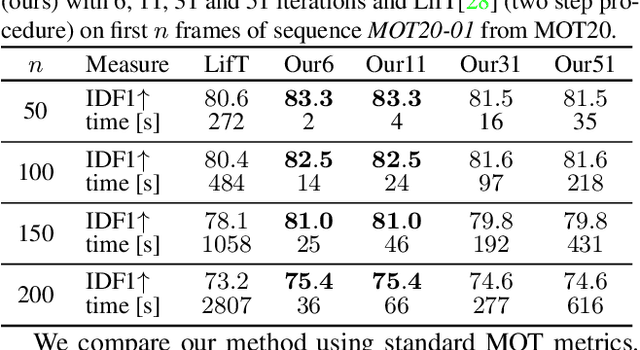
We present an efficient approximate message passing solver for the lifted disjoint paths problem (LDP), a natural but NP-hard model for multiple object tracking (MOT). Our tracker scales to very large instances that come from long and crowded MOT sequences. Our approximate solver enables us to process the MOT15/16/17 benchmarks without sacrificing solution quality and allows for solving MOT20, which has been out of reach up to now for LDP solvers due to its size and complexity. On all these four standard MOT benchmarks we achieve performance comparable or better than current state-of-the-art methods including a tracker based on an optimal LDP solver.
Lifted Disjoint Paths with Application in Multiple Object Tracking
Jun 25, 2020

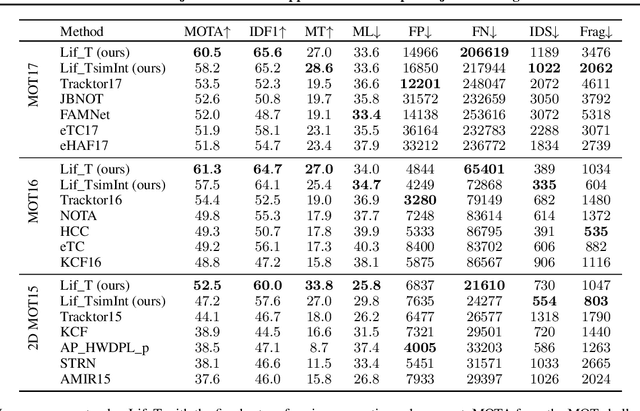

We present an extension to the disjoint paths problem in which additional \emph{lifted} edges are introduced to provide path connectivity priors. We call the resulting optimization problem the lifted disjoint paths problem. We show that this problem is NP-hard by reduction from integer multicommodity flow and 3-SAT. To enable practical global optimization, we propose several classes of linear inequalities that produce a high-quality LP-relaxation. Additionally, we propose efficient cutting plane algorithms for separating the proposed linear inequalities. The lifted disjoint path problem is a natural model for multiple object tracking and allows an elegant mathematical formulation for long range temporal interactions. Lifted edges help to prevent id switches and to re-identify persons. Our lifted disjoint paths tracker achieves nearly optimal assignments with respect to input detections. As a consequence, it leads on all three main benchmarks of the MOT challenge, improving significantly over state-of-the-art.
Fusion of Head and Full-Body Detectors for Multi-Object Tracking
Apr 24, 2018


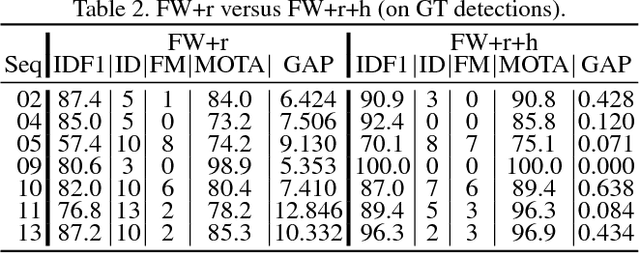
In order to track all persons in a scene, the tracking-by-detection paradigm has proven to be a very effective approach. Yet, relying solely on a single detector is also a major limitation, as useful image information might be ignored. Consequently, this work demonstrates how to fuse two detectors into a tracking system. To obtain the trajectories, we propose to formulate tracking as a weighted graph labeling problem, resulting in a binary quadratic program. As such problems are NP-hard, the solution can only be approximated. Based on the Frank-Wolfe algorithm, we present a new solver that is crucial to handle such difficult problems. Evaluation on pedestrian tracking is provided for multiple scenarios, showing superior results over single detector tracking and standard QP-solvers. Finally, our tracker ranks 2nd on the MOT16 benchmark and 1st on the new MOT17 benchmark, outperforming over 90 trackers.
Tracking with multi-level features
Jul 25, 2016
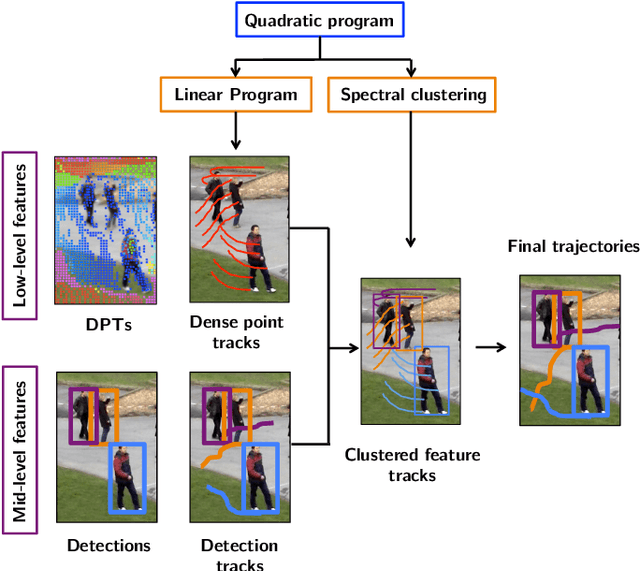
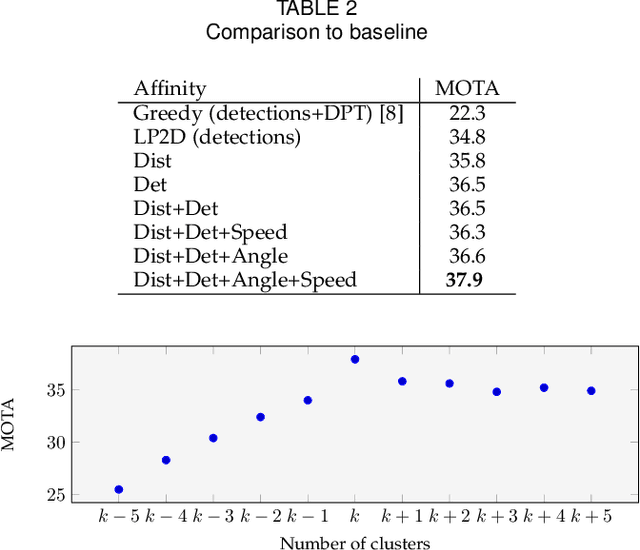
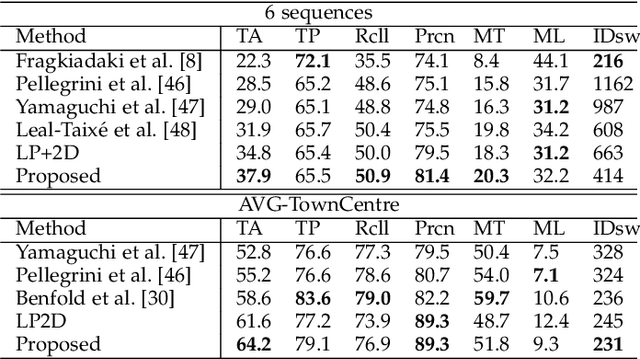
We present a novel formulation of the multiple object tracking problem which integrates low and mid-level features. In particular, we formulate the tracking problem as a quadratic program coupling detections and dense point trajectories. Due to the computational complexity of the initial QP, we propose an approximation by two auxiliary problems, a temporal and spatial association, where the temporal subproblem can be efficiently solved by a linear program and the spatial association by a clustering algorithm. The objective function of the QP is used in order to find the optimal number of clusters, where each cluster ideally represents one person. Evaluation is provided for multiple scenarios, showing the superiority of our method with respect to classic tracking-by-detection methods and also other methods that greedily integrate low-level features.