 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpurious Prompts: Can Irrelevant Prompts Steer Large Language Models?
May 28, 2026Large language models are highly sensitive to prompts, but this sensitivity is usually studied through task-relevant instructions, demonstrations, or reasoning cues. In this paper, we study a different form of prompt sensitivity: whether prompts that are semantically unrelated to the task can nevertheless steer model behavior. We call them spurious prompts and show their surprising efficacy. We also propose a simple black-box search procedure for discovering them. Across reasoning and question-answering benchmarks, using models ranging from 0.8B to 27B parameters and spanning three model families, we show that spurious prompts can improve performance, often matching or outperforming standard prompting baselines and task-aware prompt optimization. We further show that they can steer models toward unintended behaviors, such as repeatedly selecting the first answer option, producing incorrect answers, returning an even, prime or small number without explicitly instructing the model to do so. These findings reveal a new kind of prompt sensitivity: LLMs can be systematically steered by prompts that are unrelated to the task they are asked to solve. Our code is available at https://github.com/Batorskq/spurious
Transcoda: End-to-End Zero-Shot Optical Music Recognition via Data-Centric Synthetic Training
May 11, 2026Optical Music Recognition (OMR), the task of transcribing sheet music into a structured textual representation, is currently bottlenecked by a lack of large-scale, annotated datasets of real scans. This forces models to rely on either few-shot transfer or synthetic training pipelines that remain overly simplistic. A secondary challenge is encoding non-uniqueness: in the popular Humdrum **kern format for transcribing music, multiple different text encodings can render into the same visual sheet music. This one-to-many mapping creates a harder learning task and introduces high uncertainty during decoding. We propose Transcoda, an OMR system built on (i) an advanced synthetic data generation pipeline, (ii) a normalization of the **kern encoding to enforce a unique normal form and (iii) grammar-based decoding to ensure the syntactic correctness of the output. This approach allows us to train a compact 59M-parameter model in just 6 hours on a single GPU that outperforms billion-parameter baselines. Transcoda achieves the best score among state of the art baselines on a newly curated benchmark of synthetically rendered scores at 18.46% OMR-NED (compared to 43.91% for the next-best system, Legato) and reduces the error rate on historical Polish scans to 63.97% OMR-NED (down from 80.16% for SMT++).
PLR: Plackett-Luce for Reordering In-Context Learning Examples
Mar 22, 2026In-context learning (ICL) adapts large language models by conditioning on a small set of ICL examples, avoiding costly parameter updates. Among other factors, performance is often highly sensitive to the ordering of the examples. However, exhaustive search over the $n!$ possible orderings is infeasible. Therefore more efficient ordering methods use model confidence measures (e.g., label-probability entropy) over label sets or take a direct approach to finding the best ordering. We propose PLR, a probabilistic approach to in-context example ordering that replaces discrete ordering search with learning a probability distribution over orderings with the Plackett-Luce model. PLR models orderings using a Plackett-Luce distribution and iteratively updates its parameters to concentrate probability mass on high-performing orderings under a task-level metric. Candidate orderings are sampled efficiently via a Gumbel perturb-and-sort procedure. Experiments on multiple classification benchmarks show that PLR consistently improves few-shot accuracy for $k \in \{4, 8, 16, 32\}$ examples, and we further demonstrate gains on mathematical reasoning tasks where label-based ordering methods are not applicable. Our code is available at https://github.com/Batorskq/PLR.
REBEL: Hidden Knowledge Recovery via Evolutionary-Based Evaluation Loop
Feb 05, 2026Machine unlearning for LLMs aims to remove sensitive or copyrighted data from trained models. However, the true efficacy of current unlearning methods remains uncertain. Standard evaluation metrics rely on benign queries that often mistake superficial information suppression for genuine knowledge removal. Such metrics fail to detect residual knowledge that more sophisticated prompting strategies could still extract. We introduce REBEL, an evolutionary approach for adversarial prompt generation designed to probe whether unlearned data can still be recovered. Our experiments demonstrate that REBEL successfully elicits ``forgotten'' knowledge from models that seemed to be forgotten in standard unlearning benchmarks, revealing that current unlearning methods may provide only a superficial layer of protection. We validate our framework on subsets of the TOFU and WMDP benchmarks, evaluating performance across a diverse suite of unlearning algorithms. Our experiments show that REBEL consistently outperforms static baselines, recovering ``forgotten'' knowledge with Attack Success Rates (ASRs) reaching up to 60% on TOFU and 93% on WMDP. We will make all code publicly available upon acceptance. Code is available at https://github.com/patryk-rybak/REBEL/
EvoMU: Evolutionary Machine Unlearning
Feb 02, 2026Machine unlearning aims to unlearn specified training data (e.g. sensitive or copyrighted material). A prominent approach is to fine-tune an existing model with an unlearning loss that retains overall utility. The space of suitable unlearning loss functions is vast, making the search for an optimal loss function daunting. Additionally, there might not even exist a universally optimal loss function: differences in the structure and overlap of the forget and retain data can cause a loss to work well in one setting but over-unlearn or under-unlearn in another. Our approach EvoMU tackles these two challenges simultaneously. An evolutionary search procedure automatically finds task-specific losses in the vast space of possible unlearning loss functions. This allows us to find dataset-specific losses that match or outperform existing losses from the literature, without the need for a human-in-the-loop. This work is therefore an instance of automatic scientific discovery, a.k.a. an AI co-scientist. In contrast to previous AI co-scientist works, we do so on a budget: We achieve SotA results using a small 4B parameter model (Qwen3-4B-Thinking), showing the potential of AI co-scientists with limited computational resources. Our experimental evaluation shows that we surpass previous loss-based unlearning formulations on TOFU-5%, TOFU-10%, MUSE and WMDP by synthesizing novel unlearning losses. Our code is available at https://github.com/Batorskq/EvoMU.
ReLAPSe: Reinforcement-Learning-trained Adversarial Prompt Search for Erased concepts in unlearned diffusion models
Jan 30, 2026Machine unlearning is a key defense mechanism for removing unauthorized concepts from text-to-image diffusion models, yet recent evidence shows that latent visual information often persists after unlearning. Existing adversarial approaches for exploiting this leakage are constrained by fundamental limitations: optimization-based methods are computationally expensive due to per-instance iterative search. At the same time, reasoning-based and heuristic techniques lack direct feedback from the target model's latent visual representations. To address these challenges, we introduce ReLAPSe, a policy-based adversarial framework that reformulates concept restoration as a reinforcement learning problem. ReLAPSe trains an agent using Reinforcement Learning with Verifiable Rewards (RLVR), leveraging the diffusion model's noise prediction loss as a model-intrinsic and verifiable feedback signal. This closed-loop design directly aligns textual prompt manipulation with latent visual residuals, enabling the agent to learn transferable restoration strategies rather than optimizing isolated prompts. By pioneering the shift from per-instance optimization to global policy learning, ReLAPSe achieves efficient, near-real-time recovery of fine-grained identities and styles across multiple state-of-the-art unlearning methods, providing a scalable tool for rigorous red-teaming of unlearned diffusion models. Some experimental evaluations involve sensitive visual concepts, such as nudity. Code is available at https://github.com/gmum/ReLaPSe
PIAST: Rapid Prompting with In-context Augmentation for Scarce Training data
Dec 11, 2025LLMs are highly sensitive to prompt design, but handcrafting effective prompts is difficult and often requires intricate crafting of few-shot examples. We propose a fast automatic prompt construction algorithm that augments human instructions by generating a small set of few shot examples. Our method iteratively replaces/drops/keeps few-shot examples using Monte Carlo Shapley estimation of example utility. For faster execution, we use aggressive subsampling and a replay buffer for faster evaluations. Our method can be run using different compute time budgets. On a limited budget, we outperform existing automatic prompting methods on text simplification and GSM8K and obtain second best results on classification and summarization. With an extended, but still modest compute budget we set a new state of the art among automatic prompting methods on classification, simplification and GSM8K. Our results show that carefully constructed examples, rather than exhaustive instruction search, are the dominant lever for fast and data efficient prompt engineering. Our code is available at https://github.com/Batorskq/PIAST.
How Many Tokens Do 3D Point Cloud Transformer Architectures Really Need?
Nov 07, 2025Recent advances in 3D point cloud transformers have led to state-of-the-art results in tasks such as semantic segmentation and reconstruction. However, these models typically rely on dense token representations, incurring high computational and memory costs during training and inference. In this work, we present the finding that tokens are remarkably redundant, leading to substantial inefficiency. We introduce gitmerge3D, a globally informed graph token merging method that can reduce the token count by up to 90-95% while maintaining competitive performance. This finding challenges the prevailing assumption that more tokens inherently yield better performance and highlights that many current models are over-tokenized and under-optimized for scalability. We validate our method across multiple 3D vision tasks and show consistent improvements in computational efficiency. This work is the first to assess redundancy in large-scale 3D transformer models, providing insights into the development of more efficient 3D foundation architectures. Our code and checkpoints are publicly available at https://gitmerge3d.github.io
PRL: Prompts from Reinforcement Learning
May 20, 2025Effective prompt engineering remains a central challenge in fully harnessing the capabilities of LLMs. While well-designed prompts can dramatically enhance performance, crafting them typically demands expert intuition and a nuanced understanding of the task. Moreover, the most impactful prompts often hinge on subtle semantic cues, ones that may elude human perception but are crucial for guiding LLM behavior. In this paper, we introduce PRL (Prompts from Reinforcement Learning), a novel RL-based approach for automatic prompt generation. Unlike previous methods, PRL can produce novel few-shot examples that were not seen during training. Our approach achieves state-of-the-art performance across a range of benchmarks, including text classification, simplification, and summarization. On the classification task, it surpasses prior methods by 2.58% over APE and 1.00% over EvoPrompt. Additionally, it improves the average ROUGE scores on the summarization task by 4.32 over APE and by 2.12 over EvoPrompt and the SARI score on simplification by 6.93 over APE and by 6.01 over EvoPrompt. Our code is available at https://github.com/Batorskq/prl .
NSA: Neuro-symbolic ARC Challenge
Jan 08, 2025


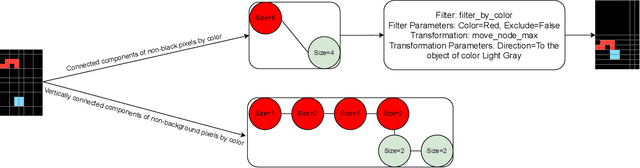
The Abstraction and Reasoning Corpus (ARC) evaluates general reasoning capabilities that are difficult for both machine learning models and combinatorial search methods. We propose a neuro-symbolic approach that combines a transformer for proposal generation with combinatorial search using a domain-specific language. The transformer narrows the search space by proposing promising search directions, which allows the combinatorial search to find the actual solution in short time. We pre-train the trainsformer with synthetically generated data. During test-time we generate additional task-specific training tasks and fine-tune our model. Our results surpass comparable state of the art on the ARC evaluation set by 27% and compare favourably on the ARC train set. We make our code and dataset publicly available at https://github.com/Batorskq/NSA.