 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Markov Reinforcement Learning for City-Scale EV Ride-Hailing with Feasibility-Guaranteed Actions
Apr 28, 2026We study city-scale control of electric-vehicle (EV) ride-hailing fleets where dispatch, repositioning, and charging decisions must respect charger and feeder limits under uncertain, spatially correlated demand and travel times. We formulate the problem as a hex-grid semi-Markov decision process (semi-MDP) with mixed actions -- discrete actions for serving, repositioning, and charging, together with continuous charging power -- and variable action durations. To guarantee physical feasibility during both training and deployment, the policy learns over high-level intentions produced by a masked, temperature-annealed actor. These intentions are projected at every decision step through a time-limited rolling mixed-integer linear program (MILP) that strictly enforces state-of-charge, port, and feeder constraints. To mitigate distributional shifts, we optimize a Soft Actor--Critic (SAC) agent against a Wasserstein-1 ambiguity set with a graph-aligned Mahalanobis ground metric that captures spatial correlations. The robust backup uses the Kantorovich--Rubinstein dual, a projected subgradient inner loop, and a primal--dual risk-budget update. Our architecture combines a two-layer Graph Convolutional Network (GCN) encoder, twin critics, and a value network that drives the adversary. Experiments on a large-scale EV fleet simulator built from NYC taxi data show that PD--RSAC achieves the highest net profit, reaching \$1.22M, compared with \$0.58M--\$0.70M for strong heuristic, single-agent RL, and multi-agent RL baselines, including Greedy, SAC, MAPPO, and MADDPG, while maintaining zero feeder-limit violations.
Anchor-and-Resume Concession Under Dynamic Pricing for LLM-Augmented Freight Negotiation
Apr 22, 2026Freight brokerages negotiate thousands of carrier rates daily under dynamic pricing conditions where models frequently revise targets mid-conversation. Classical time-dependent concession frameworks use a fixed shape parameter $β$ that cannot adapt to these updates. Deriving $β$ from the live spread enables adaptation but introduces a new problem: a pricing shift can cause the formula to retract a previous offer, violating monotonicity. LLM-powered brokers offer flexibility but require expensive reasoning models, produce non-deterministic pricing, and remain vulnerable to prompt injection. We propose a two-index anchor-and-resume framework that addresses both limitations. A spread-derived $β$ maps each load's margin structure to the correct concession posture, while the anchor-and-resume mechanism guarantees monotonically non-decreasing offers under arbitrary pricing shifts. All pricing decisions remain in a deterministic formula; the LLM, when used, serves only as a natural-language translation layer. Empirical evaluation across 115,125 negotiations shows that the adaptive $β$ tailors behavior by regime: in narrow spreads, it concedes quickly to prioritize deal closure and load coverage; in medium and wide spreads, it matches or exceeds the best fixed-$β$ baselines in broker savings. Against an unconstrained 20-billion-parameter LLM broker, it achieves similar agreement rates and savings. Against LLM-powered carriers as more realistic stochastic counterparties, it maintains comparable savings and higher agreement rates than against rule-based opponents. By decoupling the LLM from pricing logic, the framework scales horizontally to thousands of concurrent negotiations with negligible inference cost and transparent decision-making.
Photorealistic Phantom Roads in Real Scenes: Disentangling 3D Hallucinations from Physical Geometry
Dec 17, 2025Monocular depth foundation models achieve remarkable generalization by learning large-scale semantic priors, but this creates a critical vulnerability: they hallucinate illusory 3D structures from geometrically planar but perceptually ambiguous inputs. We term this failure the 3D Mirage. This paper introduces the first end-to-end framework to probe, quantify, and tame this unquantified safety risk. To probe, we present 3D-Mirage, the first benchmark of real-world illusions (e.g., street art) with precise planar-region annotations and context-restricted crops. To quantify, we propose a Laplacian-based evaluation framework with two metrics: the Deviation Composite Score (DCS) for spurious non-planarity and the Confusion Composite Score (CCS) for contextual instability. To tame this failure, we introduce Grounded Self-Distillation, a parameter-efficient strategy that surgically enforces planarity on illusion ROIs while using a frozen teacher to preserve background knowledge, thus avoiding catastrophic forgetting. Our work provides the essential tools to diagnose and mitigate this phenomenon, urging a necessary shift in MDE evaluation from pixel-wise accuracy to structural and contextual robustness. Our code and benchmark will be publicly available to foster this exciting research direction.
Investigation of Using Non-Contact Electrodes for Fetal ECG Monitoring
Oct 01, 2025



Regular physiological monitoring of maternal and fetal parameters is indispensable for ensuring safe outcomes during pregnancy and parturition. Fetal electrocardiogram (fECG) assessment is crucial to detect fetal distress and developmental anomalies. Given challenges of prenatal care due to the lack of medical professionals and the limit of accessibility, especially in remote and resource-poor areas, we develop a fECG monitoring system using novel non-contact electrodes (NCE) to record the fetal/maternal ECG (f/mECG) signals through clothes, thereby improving the comfort during measurement. The system is designed to be incorporated inside a maternity belt with data acquisition, data transmission module as well as novel NCEs. Thorough characterizations were carried out to evaluate the novel NCE against traditional wet electrodes (i.e., Ag/AgCl electrodes), showing comparable performance. A successful {preliminary pilot feasibility study} conducted with pregnant women (n = 10) between 25 and 32 weeks of gestation demonstrates the system's performance, usability and safety.
AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Sep 11, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce AU-Harness, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. AU-Harness provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
LALM-Eval: An Open-Source Toolkit for Holistic Evaluation of Large Audio Language Models
Sep 09, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce LALM-Eval, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. LALM-Eval provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
A Survey on Large Language Model based Human-Agent Systems
May 01, 2025Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-LLM-Based-Human-Agent-System-Papers.
Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
Feb 05, 2025We present AlphaGeometry2, a significantly improved version of AlphaGeometry introduced in Trinh et al. (2024), which has now surpassed an average gold medalist in solving Olympiad geometry problems. To achieve this, we first extend the original AlphaGeometry language to tackle harder problems involving movements of objects, and problems containing linear equations of angles, ratios, and distances. This, together with other additions, has markedly improved the coverage rate of the AlphaGeometry language on International Math Olympiads (IMO) 2000-2024 geometry problems from 66% to 88%. The search process of AlphaGeometry2 has also been greatly improved through the use of Gemini architecture for better language modeling, and a novel knowledge-sharing mechanism that combines multiple search trees. Together with further enhancements to the symbolic engine and synthetic data generation, we have significantly boosted the overall solving rate of AlphaGeometry2 to 84% for $\textit{all}$ geometry problems over the last 25 years, compared to 54% previously. AlphaGeometry2 was also part of the system that achieved silver-medal standard at IMO 2024 https://dpmd.ai/imo-silver. Last but not least, we report progress towards using AlphaGeometry2 as a part of a fully automated system that reliably solves geometry problems directly from natural language input.
AdaCS: Adaptive Normalization for Enhanced Code-Switching ASR
Jan 13, 2025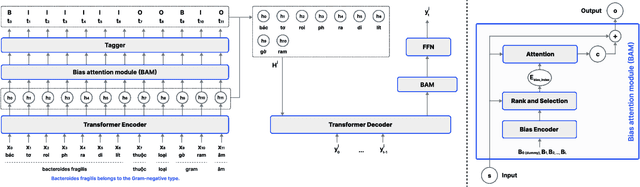
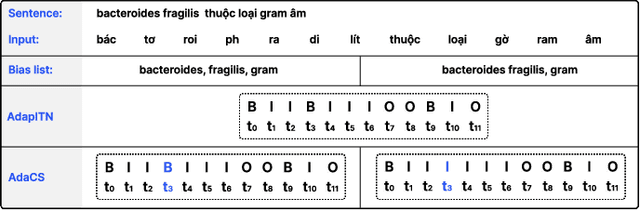
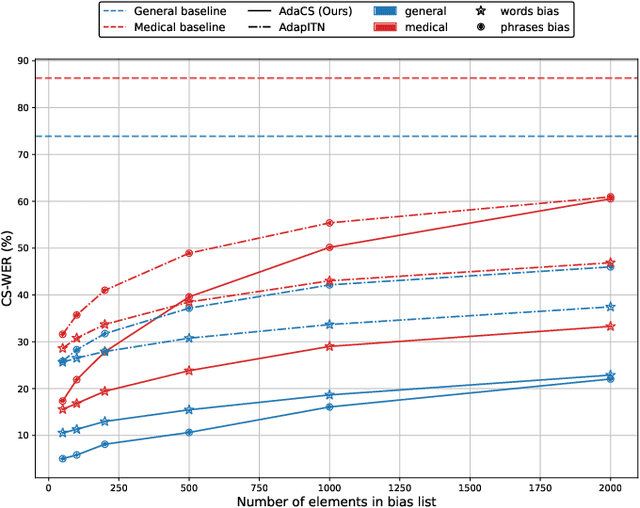

Intra-sentential code-switching (CS) refers to the alternation between languages that happens within a single utterance and is a significant challenge for Automatic Speech Recognition (ASR) systems. For example, when a Vietnamese speaker uses foreign proper names or specialized terms within their speech. ASR systems often struggle to accurately transcribe intra-sentential CS due to their training on monolingual data and the unpredictable nature of CS. This issue is even more pronounced for low-resource languages, where limited data availability hinders the development of robust models. In this study, we propose AdaCS, a normalization model integrates an adaptive bias attention module (BAM) into encoder-decoder network. This novel approach provides a robust solution to CS ASR in unseen domains, thereby significantly enhancing our contribution to the field. By utilizing BAM to both identify and normalize CS phrases, AdaCS enhances its adaptive capabilities with a biased list of words provided during inference. Our method demonstrates impressive performance and the ability to handle unseen CS phrases across various domains. Experiments show that AdaCS outperforms previous state-of-the-art method on Vietnamese CS ASR normalization by considerable WER reduction of 56.2% and 36.8% on the two proposed test sets.
Prompting with Phonemes: Enhancing LLM Multilinguality for non-Latin Script Languages
Nov 04, 2024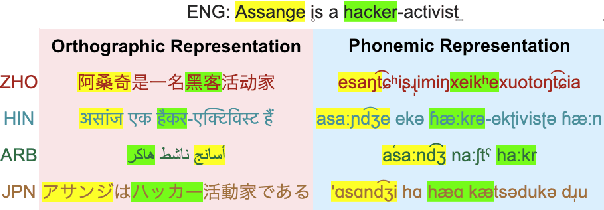

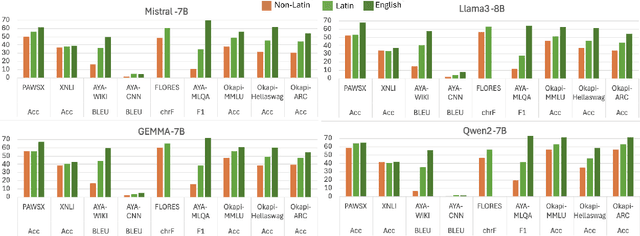

Multilingual LLMs have achieved remarkable benchmark performance, but we find they continue to underperform on non-Latin script languages across contemporary LLM families. This discrepancy arises from the fact that LLMs are pretrained with orthographic scripts, which are dominated by Latin characters that obscure their shared phonology with non-Latin scripts. We propose leveraging phonemic transcriptions as complementary signals to induce script-invariant representations. Our study demonstrates that integrating phonemic signals improves performance across both non-Latin and Latin languages, with a particularly significant impact on closing the performance gap between the two. Through detailed experiments, we show that phonemic and orthographic scripts retrieve distinct examples for in-context learning (ICL). This motivates our proposed Mixed-ICL retrieval strategy, where further aggregation leads to our significant performance improvements for both Latin script languages (up to 12.6%) and non-Latin script languages (up to 15.1%) compared to randomized ICL retrieval.