 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriva-ML: A Continuous FAIRness Approach to Reproducible Machine Learning Models
Jun 27, 2024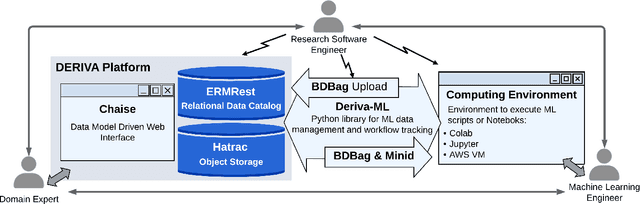
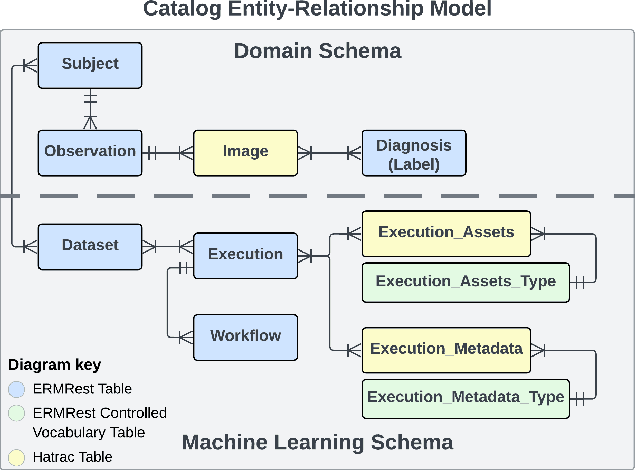
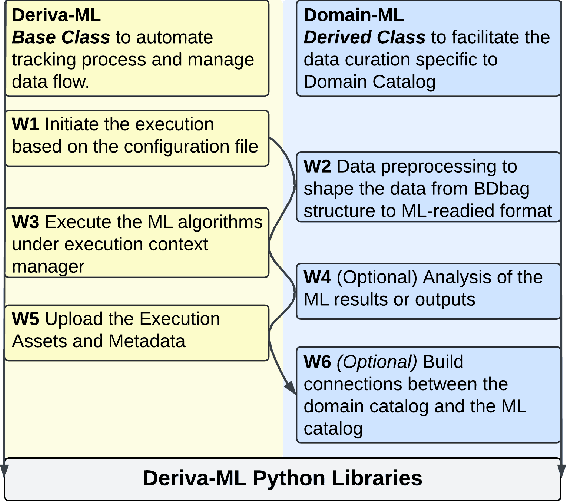
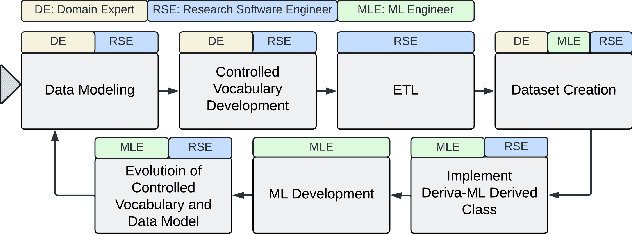
Increasingly, artificial intelligence (AI) and machine learning (ML) are used in eScience applications [9]. While these approaches have great potential, the literature has shown that ML-based approaches frequently suffer from results that are either incorrect or unreproducible due to mismanagement or misuse of data used for training and validating the models [12, 15]. Recognition of the necessity of high-quality data for correct ML results has led to data-centric ML approaches that shift the central focus from model development to creation of high-quality data sets to train and validate the models [14, 20]. However, there are limited tools and methods available for data-centric approaches to explore and evaluate ML solutions for eScience problems which often require collaborative multidisciplinary teams working with models and data that will rapidly evolve as an investigation unfolds [1]. In this paper, we show how data management tools based on the principle that all of the data for ML should be findable, accessible, interoperable and reusable (i.e. FAIR [26]) can significantly improve the quality of data that is used for ML applications. When combined with best practices that apply these tools to the entire life cycle of an ML-based eScience investigation, we can significantly improve the ability of an eScience team to create correct and reproducible ML solutions. We propose an architecture and implementation of such tools and demonstrate through two use cases how they can be used to improve ML-based eScience investigations.
ConPro: Learning Severity Representation for Medical Images using Contrastive Learning and Preference Optimization
Apr 29, 2024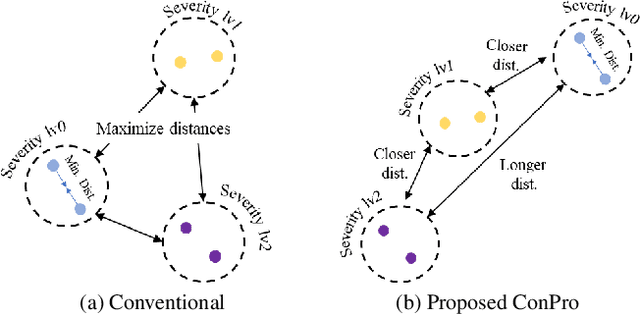
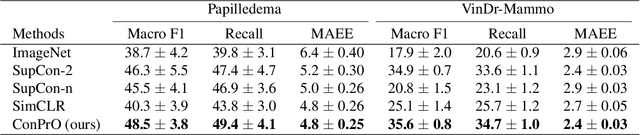
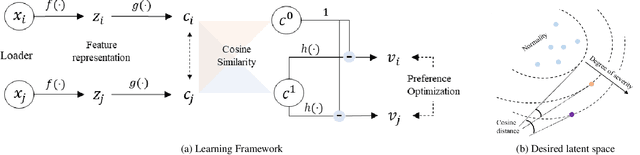
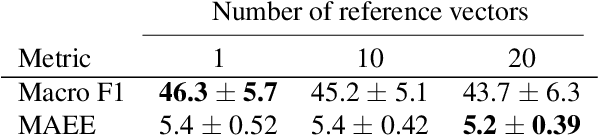
Understanding the severity of conditions shown in images in medical diagnosis is crucial, serving as a key guide for clinical assessment, treatment, as well as evaluating longitudinal progression. This paper proposes Con- PrO: a novel representation learning method for severity assessment in medical images using Contrastive learningintegrated Preference Optimization. Different from conventional contrastive learning methods that maximize the distance between classes, ConPrO injects into the latent vector the distance preference knowledge between various severity classes and the normal class. We systematically examine the key components of our framework to illuminate how contrastive prediction tasks acquire valuable representations. We show that our representation learning framework offers valuable severity ordering in the feature space while outperforming previous state-of-the-art methods on classification tasks. We achieve a 6% and 20% relative improvement compared to a supervised and a self-supervised baseline, respectively. In addition, we derived discussions on severity indicators and related applications of preference comparison in the medical domain.
Explainable Severity ranking via pairwise n-hidden comparison: a case study of glaucoma
Dec 05, 2023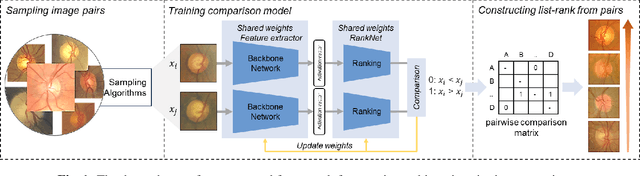

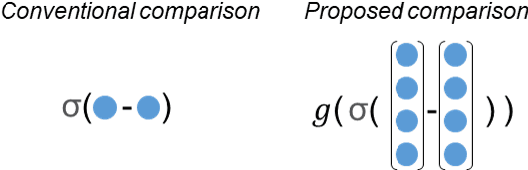
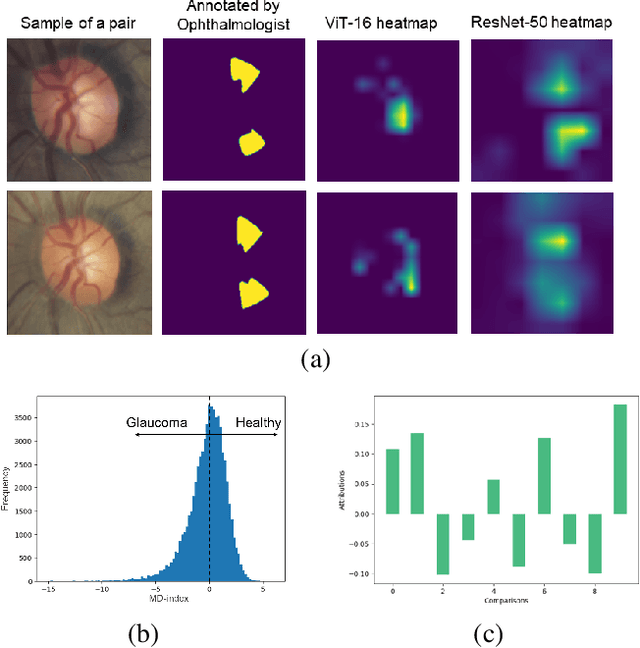
Primary open-angle glaucoma (POAG) is a chronic and progressive optic nerve condition that results in an acquired loss of optic nerve fibers and potential blindness. The gradual onset of glaucoma results in patients progressively losing their vision without being consciously aware of the changes. To diagnose POAG and determine its severity, patients must undergo a comprehensive dilated eye examination. In this work, we build a framework to rank, compare, and interpret the severity of glaucoma using fundus images. We introduce a siamese-based severity ranking using pairwise n-hidden comparisons. We additionally have a novel approach to explaining why a specific image is deemed more severe than others. Our findings indicate that the proposed severity ranking model surpasses traditional ones in terms of diagnostic accuracy and delivers improved saliency explanations.
Explaining Image Classifiers Using Contrastive Counterfactuals in Generative Latent Spaces
Jun 10, 2022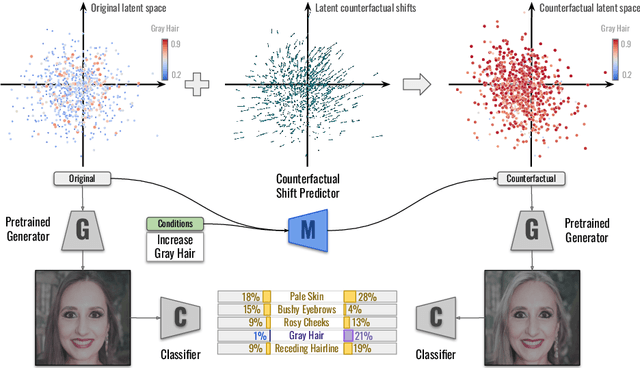


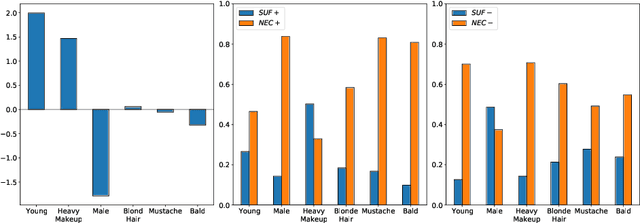
Despite their high accuracies, modern complex image classifiers cannot be trusted for sensitive tasks due to their unknown decision-making process and potential biases. Counterfactual explanations are very effective in providing transparency for these black-box algorithms. Nevertheless, generating counterfactuals that can have a consistent impact on classifier outputs and yet expose interpretable feature changes is a very challenging task. We introduce a novel method to generate causal and yet interpretable counterfactual explanations for image classifiers using pretrained generative models without any re-training or conditioning. The generative models in this technique are not bound to be trained on the same data as the target classifier. We use this framework to obtain contrastive and causal sufficiency and necessity scores as global explanations for black-box classifiers. On the task of face attribute classification, we show how different attributes influence the classifier output by providing both causal and contrastive feature attributions, and the corresponding counterfactual images.
A Natural Language Query Interface for Searching Personal Information on Smartwatches
Nov 22, 2016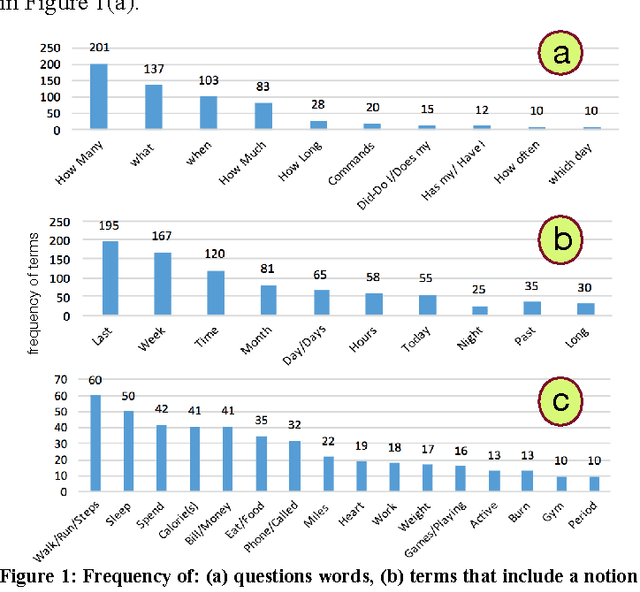
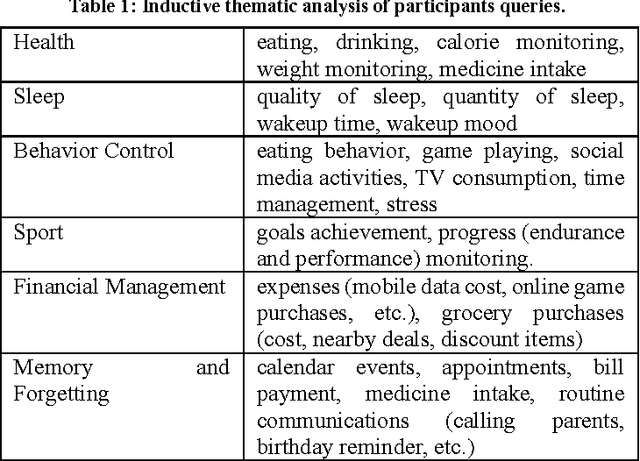

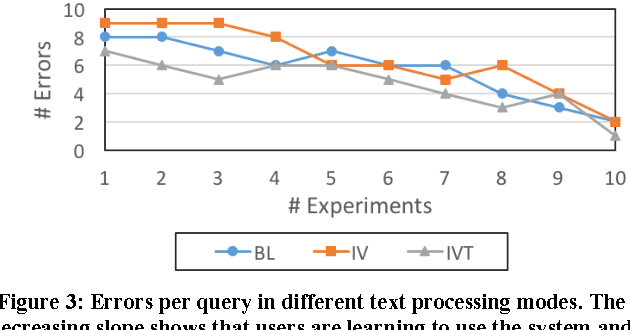
Currently, personal assistant systems, run on smartphones and use natural language interfaces. However, these systems rely mostly on the web for finding information. Mobile and wearable devices can collect an enormous amount of contextual personal data such as sleep and physical activities. These information objects and their applications are known as quantified-self, mobile health or personal informatics, and they can be used to provide a deeper insight into our behavior. To our knowledge, existing personal assistant systems do not support all types of quantified-self queries. In response to this, we have undertaken a user study to analyze a set of "textual questions/queries" that users have used to search their quantified-self or mobile health data. Through analyzing these questions, we have constructed a light-weight natural language based query interface, including a text parser algorithm and a user interface, to process the users' queries that have been used for searching quantified-self information. This query interface has been designed to operate on small devices, i.e. smartwatches, as well as augmenting the personal assistant systems by allowing them to process end users' natural language queries about their quantified-self data.